
Android 8.0 bao gồm các bài kiểm thử hiệu suất của liên kết và hwbinder về tốc độ truyền và độ trễ. Mặc dù có nhiều trường hợp để phát hiện các vấn đề về hiệu suất dễ nhận thấy, nhưng việc chạy các trường hợp như vậy có thể mất nhiều thời gian và kết quả thường không có sẵn cho đến khi hệ thống được tích hợp. Việc sử dụng các bài kiểm thử hiệu suất được cung cấp giúp bạn dễ dàng kiểm thử trong quá trình phát triển, phát hiện sớm các vấn đề nghiêm trọng và cải thiện trải nghiệm người dùng.
Kiểm thử hiệu suất bao gồm 4 danh mục sau:
- thông lượng liên kết (có trong
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - độ trễ của liên kết (có trong
frameworks/native/libs/binder/tests/schd-dbg.cpp) - thông lượng hwbinder (có trong
system/libhwbinder/vts/performance/Benchmark.cpp) - Độ trễ hwbinder (có trong
system/libhwbinder/vts/performance/Latency.cpp)
Giới thiệu về trình liên kết và hwbinder
Binder và hwbinder là các cơ sở hạ tầng giao tiếp giữa các quy trình (IPC) của Android, dùng chung một trình điều khiển Linux nhưng có những khác biệt về chất lượng sau:
| Tỷ lệ | liên kết | hwbinder |
|---|---|---|
| Mục đích | Cung cấp một giao thức IPC dùng cho nhiều mục đích cho khung | Giao tiếp với phần cứng |
| Thuộc tính | Tối ưu hoá cho việc sử dụng khung Android | Độ trễ thấp với mức hao tổn tối thiểu |
| Thay đổi chính sách lên lịch cho nền trước/nền sau | Có | Không |
| Truyền đối số | Sử dụng tính năng chuyển đổi tuần tự do đối tượng Parcel hỗ trợ | Sử dụng vùng đệm phân tán và tránh hao tổn để sao chép dữ liệu cần thiết cho quá trình chuyển đổi tuần tự Gói |
| Kế thừa mức độ ưu tiên | Không | Có |
Quy trình liên kết và hwbinder
Trình trực quan hoá systrace hiển thị các giao dịch như sau:
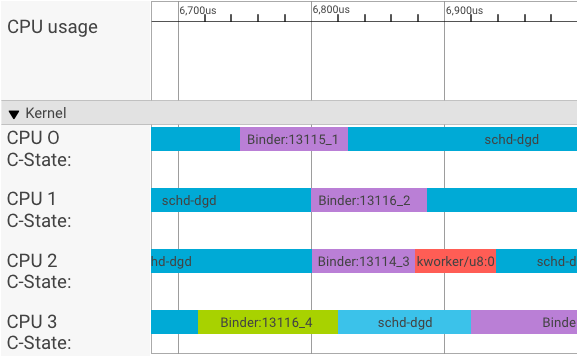
Trong ví dụ trên:
- Bốn (4) quy trình schd-dbg là các quy trình ứng dụng.
- Bốn (4) quy trình liên kết là các quy trình máy chủ (tên bắt đầu bằng Binder và kết thúc bằng một số thứ tự).
- Một quy trình ứng dụng khách luôn được ghép nối với một quy trình máy chủ dành riêng cho ứng dụng khách đó.
- Tất cả các cặp quy trình máy khách-máy chủ được hạt nhân lên lịch độc lập đồng thời.
Trong CPU 1, hạt nhân hệ điều hành sẽ thực thi ứng dụng để đưa ra yêu cầu. Sau đó, ứng dụng sẽ sử dụng cùng một CPU bất cứ khi nào có thể để đánh thức một quy trình máy chủ, xử lý yêu cầu và chuyển đổi ngữ cảnh trở lại sau khi yêu cầu hoàn tất.
Thông lượng so với độ trễ
Trong một giao dịch hoàn hảo, trong đó quy trình của máy khách và máy chủ chuyển đổi liền mạch, các thử nghiệm về băng thông và độ trễ không tạo ra thông báo khác biệt đáng kể. Tuy nhiên, khi hạt nhân hệ điều hành đang xử lý yêu cầu ngắt (IRQ) từ phần cứng, chờ khoá hoặc chỉ đơn giản là chọn không xử lý thông báo ngay lập tức, bong bóng độ trễ có thể hình thành.

Kiểm thử thông lượng tạo ra một số lượng lớn giao dịch với nhiều kích thước tải trọng, cung cấp thông tin ước tính chính xác về thời gian giao dịch thông thường (trong trường hợp tốt nhất) và thông lượng tối đa mà liên kết có thể đạt được.
Ngược lại, kiểm thử độ trễ không thực hiện hành động nào trên tải trọng để giảm thiểu thời gian giao dịch thông thường. Chúng ta có thể sử dụng thời gian giao dịch để ước tính hao tổn của liên kết, tạo số liệu thống kê cho trường hợp xấu nhất và tính tỷ lệ giao dịch có độ trễ đáp ứng thời hạn đã chỉ định.
Xử lý các trường hợp đảo ngược mức độ ưu tiên
Hiện tượng đảo ngược mức độ ưu tiên xảy ra khi một luồng có mức độ ưu tiên cao hơn đang chờ một luồng có mức độ ưu tiên thấp hơn. Ứng dụng theo thời gian thực (RT) có vấn đề đảo ngược mức độ ưu tiên:
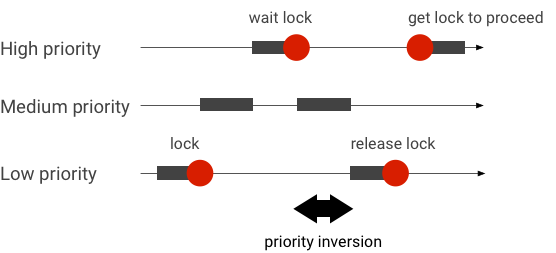
Khi sử dụng tính năng lập lịch biểu Linux Completely Fair Scheduler (CFS), một luồng luôn có cơ hội chạy ngay cả khi các luồng khác có mức độ ưu tiên cao hơn. Do đó, các ứng dụng có lịch biểu CFS xử lý việc đảo ngược mức độ ưu tiên như hành vi dự kiến và không phải là vấn đề. Tuy nhiên, trong trường hợp khung Android cần lên lịch RT để đảm bảo đặc quyền của các luồng có mức độ ưu tiên cao, bạn phải giải quyết vấn đề đảo ngược mức độ ưu tiên.
Ví dụ về việc đảo ngược mức độ ưu tiên trong một giao dịch liên kết (luồng RT bị các luồng CFS khác chặn theo logic khi chờ luồng liên kết phục vụ):
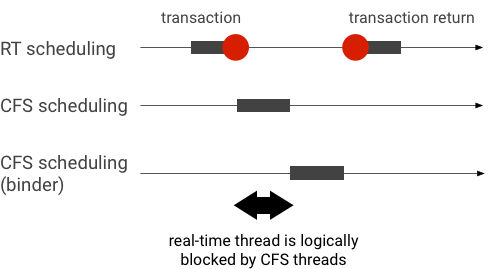
Để tránh bị chặn, bạn có thể sử dụng tính năng kế thừa mức độ ưu tiên để tạm thời chuyển luồng Binder lên luồng RT khi luồng này xử lý yêu cầu từ ứng dụng RT. Xin lưu ý rằng tính năng lập lịch biểu RT có tài nguyên hạn chế và bạn nên sử dụng tính năng này một cách cẩn thận. Trong một hệ thống có n CPU, số lượng luồng RT tối đa hiện tại cũng là n; các luồng RT bổ sung có thể cần phải đợi (và do đó bỏ lỡ thời hạn) nếu tất cả CPU đều bị các luồng RT khác chiếm dụng.
Để giải quyết mọi trường hợp đảo ngược mức độ ưu tiên có thể xảy ra, bạn có thể sử dụng tính năng kế thừa mức độ ưu tiên cho cả trình liên kết và hwbinder. Tuy nhiên, vì trình liên kết được sử dụng rộng rãi trên hệ thống, nên việc bật tính năng kế thừa mức độ ưu tiên cho các giao dịch liên kết có thể làm hệ thống bị làm phiền bằng nhiều luồng RT hơn mức hệ thống có thể xử lý.
Chạy kiểm thử lưu lượng
Bài kiểm thử tốc độ truyền dẫn được chạy dựa trên tốc độ giao dịch liên kết/hwbinder. Trong một hệ thống không bị quá tải, bong bóng độ trễ hiếm khi xuất hiện và tác động của chúng có thể bị loại bỏ miễn là số lần lặp lại đủ cao.
- Bài kiểm thử tốc độ truyền dữ liệu liên kết nằm trong
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Kiểm thử thông lượng hwbinder nằm trong
system/libhwbinder/vts/performance/Benchmark.cpp.
Kết quả thử nghiệm
Ví dụ về kết quả kiểm tra tốc độ truyền tải cho các giao dịch sử dụng nhiều kích thước tải trọng:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Thời gian cho biết độ trễ trọn vòng được đo theo thời gian thực.
- CPU cho biết thời gian tích luỹ khi CPU được lên lịch cho quá trình kiểm thử.
- Số lần lặp lại cho biết số lần hàm kiểm thử được thực thi.
Ví dụ: đối với tải trọng 8 byte:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… thông lượng tối đa mà liên kết có thể đạt được được tính như sau:
Tốc độ truyền MAX với tải trọng 8 byte = (8 * 21296)/69974 ~= 2,423 b/ns ~= 2,268 Gb/s
Tuỳ chọn kiểm thử
Để nhận kết quả ở định dạng .json, hãy chạy kiểm thử bằng đối số --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Chạy kiểm thử độ trễ
Kiểm thử độ trễ đo lường thời gian cần thiết để ứng dụng bắt đầu khởi chạy giao dịch, chuyển sang quy trình xử lý của máy chủ và nhận kết quả. Quy trình kiểm thử cũng tìm kiếm các hành vi lập lịch biểu xấu đã biết có thể ảnh hưởng tiêu cực đến độ trễ giao dịch, chẳng hạn như trình lập lịch biểu không hỗ trợ tính năng kế thừa mức độ ưu tiên hoặc tuân thủ cờ đồng bộ hoá.
- Kiểm thử độ trễ liên kết nằm trong
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Kiểm thử độ trễ hwbinder nằm trong
system/libhwbinder/vts/performance/Latency.cpp.
Kết quả thử nghiệm
Kết quả (ở định dạng .json) cho thấy số liệu thống kê về độ trễ trung bình/tốt nhất/tệ nhất và số lần bỏ lỡ thời hạn.
Tuỳ chọn kiểm thử
Các bài kiểm thử độ trễ có các tuỳ chọn sau:
| Lệnh | Mô tả |
|---|---|
-i value |
Chỉ định số lần lặp lại. |
-pair value |
Chỉ định số lượng cặp quy trình. |
-deadline_us 2500 |
Chỉ định thời hạn theo giờ Hoa Kỳ. |
-v |
Nhận kết quả chi tiết (gỡ lỗi). |
-trace |
Dừng dấu vết khi hết thời hạn. |
Các phần sau đây trình bày chi tiết từng tuỳ chọn, mô tả cách sử dụng và cung cấp kết quả mẫu.
Chỉ định số lần lặp lại
Ví dụ về một số lượng lớn lượt lặp và tắt kết quả chi tiết:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Kết quả kiểm thử này cho thấy những điều sau:
"pair":3- Tạo một cặp máy khách và máy chủ.
"iterations": 5000- Bao gồm 5000 lần lặp lại.
"deadline_us":2500- Thời hạn là 2500us (2,5 mili giây); hầu hết các giao dịch dự kiến sẽ đáp ứng giá trị này.
"I": 10000- Một vòng lặp kiểm thử bao gồm hai (2) giao dịch:
- Một giao dịch theo mức độ ưu tiên bình thường (
CFS other) - Một giao dịch theo mức độ ưu tiên theo thời gian thực (
RT-fifo)
- Một giao dịch theo mức độ ưu tiên bình thường (
"S": 9352- 9352 giao dịch được đồng bộ hoá trong cùng một CPU.
"R": 0.9352- Cho biết tỷ lệ đồng bộ hoá máy khách và máy chủ trong cùng một CPU.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Trường hợp trung bình (
avg), tệ nhất (wst) và tốt nhất (bst) cho tất cả các giao dịch do phương thức gọi có mức độ ưu tiên thông thường thực hiện. Hai giao dịchmissthời hạn, khiến tỷ lệ đáp ứng (meetR) là 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Tương tự như
other_ms, nhưng dành cho các giao dịch do ứng dụng phát hành với mức độ ưu tiênrt_fifo. Có thể (nhưng không bắt buộc) làfifo_mscó kết quả tốt hơnother_ms, với các giá trịavgvàwstthấp hơn vàmeetRcao hơn (sự khác biệt có thể còn đáng kể hơn khi tải ở chế độ nền).
Lưu ý: Tải trong nền có thể ảnh hưởng đến kết quả về thông lượng và bộ dữ liệu other_ms trong kiểm thử độ trễ. Chỉ fifo_ms mới có thể cho thấy kết quả tương tự, miễn là tải trong nền có mức độ ưu tiên thấp hơn RT-fifo.
Chỉ định giá trị cặp
Mỗi quy trình ứng dụng khách được ghép nối với một quy trình máy chủ dành riêng cho ứng dụng khách,
và mỗi cặp có thể được lên lịch độc lập cho bất kỳ CPU nào. Tuy nhiên, quá trình di chuyển CPU sẽ không xảy ra trong một giao dịch, miễn là cờ SYNC là honor.
Đảm bảo hệ thống không bị quá tải! Mặc dù độ trễ cao trong một hệ thống quá tải là điều dự kiến, nhưng kết quả kiểm thử cho một hệ thống quá tải không cung cấp thông tin hữu ích. Để kiểm thử một hệ thống có áp suất cao hơn, hãy sử dụng -pair
#cpu-1 (hoặc -pair #cpu một cách thận trọng). Việc kiểm thử bằng -pair n với n > #cpu sẽ làm quá tải hệ thống và tạo ra thông tin vô dụng.
Chỉ định giá trị thời hạn
Sau khi kiểm thử rộng rãi các tình huống người dùng (chạy kiểm thử độ trễ trên một sản phẩm đủ điều kiện), chúng tôi xác định rằng 2,5 mili giây là thời hạn cần đáp ứng. Đối với các ứng dụng mới có yêu cầu cao hơn (chẳng hạn như 1.000 ảnh/giây), giá trị thời hạn này sẽ thay đổi.
Chỉ định đầu ra chi tiết
Việc sử dụng tuỳ chọn -v sẽ hiển thị kết quả chi tiết. Ví dụ:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Luồng dịch vụ được tạo với mức độ ưu tiên
SCHED_OTHERvà chạy trongCPU:1vớipid 8674. - Sau đó, giao dịch đầu tiên sẽ được bắt đầu bằng một
fifo-caller. Để xử lý giao dịch này, hwbinder nâng cấp mức độ ưu tiên của máy chủ (pid: 8674 tid: 8676) lên 99 và cũng đánh dấu máy chủ bằng một lớp lên lịch tạm thời (in dưới dạng???). Sau đó, trình lập lịch biểu sẽ đặt quy trình máy chủ trongCPU:0để chạy và đồng bộ hoá quy trình đó với cùng một CPU với ứng dụng. - Phương thức gọi giao dịch thứ hai có mức độ ưu tiên
SCHED_OTHER. Máy chủ tự hạ cấp và phục vụ lệnh gọi với mức độ ưu tiênSCHED_OTHER.
Sử dụng dấu vết để gỡ lỗi
Bạn có thể chỉ định tuỳ chọn -trace để gỡ lỗi các vấn đề về độ trễ. Khi được sử dụng, kiểm thử độ trễ sẽ dừng quá trình ghi nhật ký theo dõi tại thời điểm phát hiện độ trễ không tốt. Ví dụ:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Các thành phần sau đây có thể ảnh hưởng đến độ trễ:
- Chế độ xây dựng Android. Chế độ Eng thường chậm hơn chế độ userdebug.
- Khung. Dịch vụ khung sử dụng
ioctlđể định cấu hình cho trình liên kết như thế nào? - Trình điều khiển liên kết. Trình điều khiển có hỗ trợ tính năng khoá chi tiết không? Tệp này có chứa tất cả các bản vá chuyển đổi hiệu suất không?
- Phiên bản hạt nhân. Hạt nhân có khả năng xử lý theo thời gian thực càng tốt thì kết quả càng tốt.
- Cấu hình hạt nhân. Cấu hình hạt nhân có chứa cấu hình
DEBUGnhưDEBUG_PREEMPTvàDEBUG_SPIN_LOCKkhông? - Trình lập lịch biểu hạt nhân. Nhân hệ điều hành có trình lập lịch biểu Tiết kiệm năng lượng (EAS) hay Trình lập lịch biểu đa xử lý không đồng nhất (HMP) không? Có trình điều khiển hạt nhân nào (trình điều khiển
cpu-freq, trình điều khiểncpu-idle,cpu-hotplug, v.v.) ảnh hưởng đến trình lập lịch biểu không?