
Android 8.0 menyertakan pengujian performa binder dan hwbinder untuk throughput dan latensi. Meskipun ada banyak skenario untuk mendeteksi masalah performa yang terlihat, menjalankan skenario tersebut dapat memakan waktu dan hasilnya sering kali tidak tersedia hingga setelah sistem diintegrasikan. Menggunakan pengujian performa yang disediakan akan mempermudah pengujian selama pengembangan, mendeteksi masalah serius lebih awal, dan meningkatkan pengalaman pengguna.
Pengujian performa mencakup empat kategori berikut:
- throughput binder (tersedia di
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - latensi binder (tersedia di
frameworks/native/libs/binder/tests/schd-dbg.cpp) - Throughput hwbinder (tersedia di
system/libhwbinder/vts/performance/Benchmark.cpp) - Latensi hwbinder (tersedia di
system/libhwbinder/vts/performance/Latency.cpp)
Tentang binder dan hwbinder
Binder dan hwbinder adalah infrastruktur komunikasi antar-proses (IPC) Android yang menggunakan driver Linux yang sama, tetapi memiliki perbedaan kualitatif berikut:
| Aspek | pengikat | hwbinder |
|---|---|---|
| Tujuan | Menyediakan skema IPC tujuan umum untuk framework | Berkomunikasi dengan hardware |
| Properti | Dioptimalkan untuk penggunaan framework Android | Latensi rendah overhead minimum |
| Mengubah kebijakan penjadwalan untuk latar depan/latar belakang | Ya | Tidak |
| Penerusan argumen | Menggunakan serialisasi yang didukung oleh objek Parcel | Menggunakan buffer scatter dan menghindari overhead untuk menyalin data yang diperlukan untuk serialisasi Parcel |
| Pewarisan prioritas | Tidak | Ya |
Proses binder dan hwbinder
Visualisator systrace menampilkan transaksi sebagai berikut:
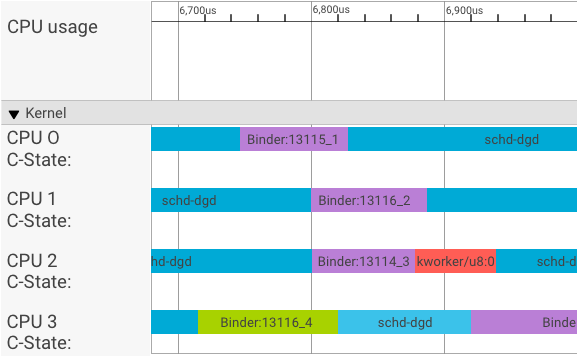
Dalam contoh di atas:
- Empat (4) proses schd-dbg adalah proses klien.
- Empat (4) proses binder adalah proses server (nama dimulai dengan Binder dan diakhiri dengan nomor urut).
- Proses klien selalu disambungkan dengan proses server, yang didedikasikan untuk kliennya.
- Semua pasangan proses klien-server dijadwalkan secara independen oleh kernel secara serentak.
Di CPU 1, kernel OS mengeksekusi klien untuk mengeluarkan permintaan. Kemudian, CPU yang sama akan digunakan jika memungkinkan untuk mengaktifkan proses server, menangani permintaan, dan beralih kembali ke konteks setelah permintaan selesai.
Throughput vs. latensi
Dalam transaksi yang sempurna, saat proses klien dan server beralih secara lancar, pengujian throughput dan latensi tidak menghasilkan pesan yang sangat berbeda. Namun, saat kernel OS menangani permintaan interupsi (IRQ) dari hardware, menunggu kunci, atau hanya memilih untuk tidak segera menangani pesan, gelembung latensi dapat terbentuk.

Pengujian throughput menghasilkan banyak transaksi dengan ukuran payload yang berbeda, memberikan estimasi yang baik untuk waktu transaksi reguler (dalam skenario kasus terbaik) dan throughput maksimum yang dapat dicapai binder.
Sebaliknya, pengujian latensi tidak melakukan tindakan apa pun pada payload untuk meminimalkan waktu transaksi reguler. Kita dapat menggunakan waktu transaksi untuk memperkirakan overhead binder, membuat statistik untuk kasus terburuk, dan menghitung rasio transaksi yang latensinya memenuhi batas waktu yang ditentukan.
Menangani inversi prioritas
Inversi prioritas terjadi saat thread dengan prioritas lebih tinggi secara logis menunggu thread dengan prioritas lebih rendah. Aplikasi real-time (RT) memiliki masalah inversi prioritas:
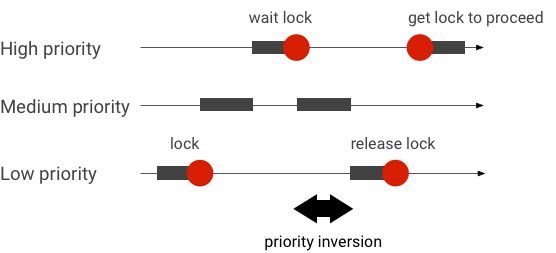
Saat menggunakan penjadwalan Linux Completely Fair Scheduler (CFS), thread selalu memiliki peluang untuk berjalan meskipun thread lain memiliki prioritas yang lebih tinggi. Akibatnya, aplikasi dengan penjadwalan CFS menangani inversi prioritas sebagai perilaku yang diharapkan dan bukan sebagai masalah. Namun, jika framework Android memerlukan penjadwalan RT untuk menjamin hak istimewa thread prioritas tinggi, inversi prioritas harus diselesaikan.
Contoh inversi prioritas selama transaksi binder (thread RT diblokir secara logis oleh thread CFS lain saat menunggu thread binder dilayani):
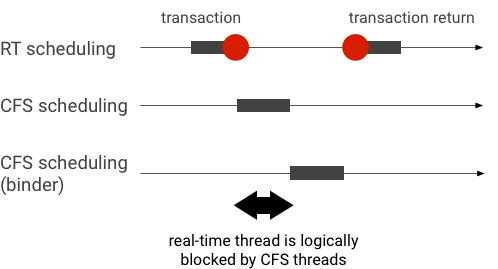
Untuk menghindari pemblokiran, Anda dapat menggunakan pewarisan prioritas untuk mengeskalasikan thread Binder ke thread RT untuk sementara saat melayani permintaan dari klien RT. Perlu diingat bahwa penjadwalan RT memiliki resource terbatas dan harus digunakan dengan hati-hati. Dalam sistem dengan CPU n, jumlah maksimum thread RT saat ini juga n; thread RT tambahan mungkin perlu menunggu (sehingga melewatkan batas waktunya) jika semua CPU diambil oleh thread RT lain.
Untuk menyelesaikan semua kemungkinan inversi prioritas, Anda dapat menggunakan pewarisan prioritas untuk binder dan hwbinder. Namun, karena binder digunakan secara luas di seluruh sistem, mengaktifkan pewarisan prioritas untuk transaksi binder dapat mengirim spam ke sistem dengan lebih banyak thread RT daripada yang dapat dilayani.
Menjalankan pengujian throughput
Pengujian throughput dijalankan terhadap throughput transaksi binder/hwbinder. Dalam sistem yang tidak kelebihan beban, bubble latensi jarang terjadi dan dampaknya dapat dihilangkan selama jumlah iterasi cukup tinggi.
- Pengujian throughput binder berada di
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Pengujian throughput hwbinder berada di
system/libhwbinder/vts/performance/Benchmark.cpp.
Hasil uji
Contoh hasil pengujian throughput untuk transaksi yang menggunakan berbagai ukuran payload:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Waktu menunjukkan keterlambatan bolak-balik yang diukur secara real time.
- CPU menunjukkan waktu yang terakumulasi saat CPU dijadwalkan untuk pengujian.
- Iterasi menunjukkan frekuensi fungsi pengujian dijalankan.
Misalnya, untuk payload 8 byte:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… throughput maksimum yang dapat dicapai binder dihitung sebagai:
Throughput MAKSIMAL dengan payload 8 byte = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
Opsi pengujian
Untuk mendapatkan hasil dalam .json, jalankan pengujian dengan argumen --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Menjalankan pengujian latensi
Pengujian latensi mengukur waktu yang diperlukan klien untuk mulai melakukan inisialisasi transaksi, beralih ke proses server untuk penanganan, dan menerima hasilnya. Pengujian ini juga mencari perilaku penjadwal buruk yang diketahui yang dapat berdampak negatif pada latensi transaksi, seperti penjadwal yang tidak mendukung pewarisan prioritas atau mematuhi flag sinkronisasi.
- Pengujian latensi binder berada di
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Pengujian latensi hwbinder berada di
system/libhwbinder/vts/performance/Latency.cpp.
Hasil uji
Hasil (dalam .json) menunjukkan statistik untuk latensi rata-rata/terbaik/terburuk dan jumlah batas waktu yang terlewat.
Opsi pengujian
Pengujian latensi menggunakan opsi berikut:
| Perintah | Deskripsi |
|---|---|
-i value |
Tentukan jumlah iterasi. |
-pair value |
Tentukan jumlah pasangan proses. |
-deadline_us 2500 |
Tentukan batas waktu dalam satuan detik. |
-v |
Mendapatkan output panjang (proses debug). |
-trace |
Menghentikan rekaman aktivitas saat batas waktu tercapai. |
Bagian berikut menjelaskan setiap opsi, menjelaskan penggunaan, dan memberikan contoh hasil.
Menentukan iterasi
Contoh dengan banyak iterasi dan output panjang dinonaktifkan:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Hasil pengujian ini menunjukkan hal berikut:
"pair":3- Membuat satu pasangan klien dan server.
"iterations": 5000- Mencakup 5.000 iterasi.
"deadline_us":2500- Batas waktu adalah 2.500 md (2,5 md); sebagian besar transaksi diharapkan memenuhi nilai ini.
"I": 10000- Satu iterasi pengujian mencakup dua (2) transaksi:
- Satu transaksi menurut prioritas normal (
CFS other) - Satu transaksi menurut prioritas real time (
RT-fifo)
- Satu transaksi menurut prioritas normal (
"S": 9352- 9352 transaksi disinkronkan di CPU yang sama.
"R": 0.9352- Menunjukkan rasio sinkronisasi klien dan server di CPU yang sama.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Kasus rata-rata (
avg), terburuk (wst), dan terbaik (bst) untuk semua transaksi yang dikeluarkan oleh pemanggil prioritas normal. Dua transaksimissbatas waktu, sehingga rasio temu (meetR) 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Serupa dengan
other_ms, tetapi untuk transaksi yang dikeluarkan oleh klien dengan prioritasrt_fifo. Kemungkinan (tetapi tidak wajib) bahwafifo_msmemiliki hasil yang lebih baik daripadaother_ms, dengan nilaiavgdanwstyang lebih rendah sertameetRyang lebih tinggi (perbedaannya dapat menjadi lebih signifikan dengan pemuatan di latar belakang).
Catatan: Pemuatan latar belakang dapat memengaruhi hasil throughput
dan tuple other_ms dalam pengujian latensi. Hanya
fifo_ms yang dapat menampilkan hasil serupa selama beban latar belakang memiliki
prioritas yang lebih rendah daripada RT-fifo.
Menentukan nilai pasangan
Setiap proses klien disambungkan dengan proses server yang didedikasikan untuk klien,
dan setiap pasangan dapat dijadwalkan secara terpisah ke CPU mana pun. Namun, migrasi
CPU tidak boleh terjadi selama transaksi selama flag SYNC
honor.
Pastikan sistem tidak kelebihan beban. Meskipun latensi tinggi dalam sistem yang kelebihan beban
diharapkan, hasil pengujian untuk sistem yang kelebihan beban tidak memberikan informasi
yang berguna. Untuk menguji sistem dengan tekanan yang lebih tinggi, gunakan -pair
#cpu-1 (atau -pair #cpu dengan hati-hati). Pengujian menggunakan
-pair n dengan n > #cpu membebani
sistem dan menghasilkan informasi yang tidak berguna.
Menentukan nilai batas waktu
Setelah pengujian skenario pengguna yang ekstensif (menjalankan pengujian latensi pada produk yang memenuhi syarat), kami memutuskan bahwa 2,5 md adalah batas waktu yang harus dipenuhi. Untuk aplikasi baru dengan persyaratan yang lebih tinggi (seperti 1.000 foto/detik), nilai batas waktu ini akan berubah.
Menentukan output panjang
Menggunakan opsi -v akan menampilkan output panjang. Contoh:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Thread layanan dibuat dengan
prioritas
SCHED_OTHERdan berjalan diCPU:1denganpid 8674. - Transaksi pertama kemudian dimulai oleh
fifo-caller. Untuk melayani transaksi ini, hwbinder mengupgrade prioritas server (pid: 8674 tid: 8676) menjadi 99 dan juga menandainya dengan class penjadwalan sementara (dicetak sebagai???). Penjadwal kemudian menempatkan proses server diCPU:0untuk dijalankan dan menyinkronkannya dengan CPU yang sama dengan kliennya. - Pemanggil transaksi kedua memiliki
prioritas
SCHED_OTHER. Server mendowngrade dirinya sendiri dan melayani pemanggil dengan prioritasSCHED_OTHER.
Menggunakan rekaman aktivitas untuk proses debug
Anda dapat menentukan opsi -trace untuk men-debug masalah latensi. Saat
digunakan, pengujian latensi akan menghentikan perekaman tracelog pada saat latensi
buruk terdeteksi. Contoh:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Komponen berikut dapat memengaruhi latensi:
- Mode build Android. Mode eng biasanya lebih lambat daripada mode userdebug.
- Framework. Bagaimana layanan framework menggunakan
ioctluntuk mengonfigurasi ke binder? - Driver binder. Apakah driver mendukung penguncian yang terperinci? Apakah patch ini berisi semua patch peningkatan performa?
- Versi kernel. Makin baik kemampuan real time yang dimiliki kernel, makin baik hasilnya.
- Konfigurasi kernel. Apakah konfigurasi kernel berisi
konfigurasi
DEBUGsepertiDEBUG_PREEMPTdanDEBUG_SPIN_LOCK? - Penjadwal kernel. Apakah kernel memiliki penjadwal Energy-Aware (EAS) atau Heterogeneous Multi-Processing (HMP)? Apakah ada driver kernel (driver
cpu-freq, drivercpu-idle,cpu-hotplug, dll.) yang memengaruhi penjadwal?