
systrace ist das primäre Tool zur Analyse der Leistung von Android-Geräten. Es ist jedoch nur ein Wrapper für andere Tools. Es handelt sich um den Host-seitigen Wrapper für atrace, die geräteseitige ausführbare Datei, die das Tracing im Nutzerbereich steuert und ftrace einrichtet, den primären Tracing-Mechanismus im Linux-Kernel. systrace verwendet atrace, um das Tracing zu aktivieren, liest dann den ftrace-Puffer und verpackt alles in einem eigenständigen HTML-Viewer. Neuere Kernel unterstützen zwar den Linux Enhanced Berkeley Packet Filter (eBPF), diese Seite bezieht sich jedoch auf den Kernel 3.18 (ohne eBPF), da dieser auf dem Pixel und dem Pixel XL verwendet wurde.
systrace gehört zu den Google Android- und Google Chrome-Teams und ist als Teil des Catapult-Projekts Open Source. Zusätzlich zu systrace enthält Catapult weitere nützliche Dienstprogramme. Ftrace bietet beispielsweise mehr Funktionen, als direkt über systrace oder atrace aktiviert werden können, und enthält einige erweiterte Funktionen, die für das Debuggen von Leistungsproblemen unerlässlich sind. Für diese Funktionen ist Root-Zugriff und oft ein neuer Kernel erforderlich.
Systrace ausführen
Wenn Sie Jitter auf Pixel oder Pixel XL debuggen, beginnen Sie mit dem folgenden Befehl:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
In Kombination mit den zusätzlichen Tracepoints, die für GPU- und Display-Pipeline-Aktivitäten erforderlich sind, können Sie so den Weg von der Nutzereingabe bis zum auf dem Bildschirm angezeigten Frame nachvollziehen. Legen Sie die Puffergröße auf einen großen Wert fest, um den Verlust von Ereignissen zu vermeiden. Ohne einen großen Puffer enthalten einige CPUs nach einem bestimmten Punkt im Trace keine Ereignisse mehr.
Denken Sie beim Durchgehen von Systrace daran, dass jedes Ereignis durch etwas auf der CPU ausgelöst wird.
Da systrace auf ftrace basiert und ftrace auf der CPU ausgeführt wird, muss etwas auf der CPU den ftrace-Puffer schreiben, in dem Hardwareänderungen protokolliert werden. Wenn Sie wissen möchten, warum sich der Status einer Anzeigezaun geändert hat, können Sie sehen, was genau zum Zeitpunkt der Änderung auf der CPU ausgeführt wurde. Dieses Konzept ist die Grundlage für die Analyse der Leistung mit Systrace.
Beispiel: Arbeitsrahmen
In diesem Beispiel wird ein Systrace für eine normale UI-Pipeline beschrieben. Wenn Sie dem Beispiel folgen möchten, laden Sie die ZIP-Datei mit den Traces herunter (sie enthält auch andere Traces, auf die in diesem Abschnitt verwiesen wird), entpacken Sie die Datei und öffnen Sie die systrace_tutorial.html-Datei in Ihrem Browser.
Bei einer konsistenten, periodischen Arbeitslast wie TouchLatency folgt die UI-Pipeline dieser Sequenz:
- EventThread in SurfaceFlinger aktiviert den UI-Thread der App und signalisiert, dass es an der Zeit ist, einen neuen Frame zu rendern.
- Die App rendert einen Frame im UI-Thread, im RenderThread und in HWUI-Aufgaben mit CPU- und GPU-Ressourcen. Das ist der Großteil der für die Benutzeroberfläche verwendeten Kapazität.
- Die App sendet den gerenderten Frame über einen Binder an SurfaceFlinger. SurfaceFlinger wechselt dann in den Ruhemodus.
- Ein zweiter EventThread in SurfaceFlinger weckt SurfaceFlinger, um die Komposition und die Displayausgabe auszulösen. Wenn SurfaceFlinger feststellt, dass keine Arbeit zu erledigen ist, wird der Prozess wieder in den Ruhezustand versetzt.
- SurfaceFlinger übernimmt die Komposition mit dem Hardware Composer (HWC), dem Hardware Composer 2 (HWC2) oder GL. Die HWC- und HWC2-Zusammensetzung ist schneller und verbraucht weniger Strom, hat aber je nach System-on-Chip (SoC) Einschränkungen. Das dauert in der Regel etwa 4 bis 6 ms, kann sich aber mit Schritt 2 überschneiden, da Android-Apps immer dreifach gepuffert werden. Apps werden immer dreifach gepuffert. In SurfaceFlinger kann jedoch nur ein ausstehender Frame warten, sodass es so aussieht, als würde eine doppelte Pufferung verwendet.
- SurfaceFlinger sendet die endgültige Ausgabe an das Display mit einem Anbieter-Treiber und wechselt zurück in den Ruhemodus, um auf das Aufwachen des EventThread zu warten.
Hier ist ein Beispiel für die Frame-Sequenz ab 15.409 ms:
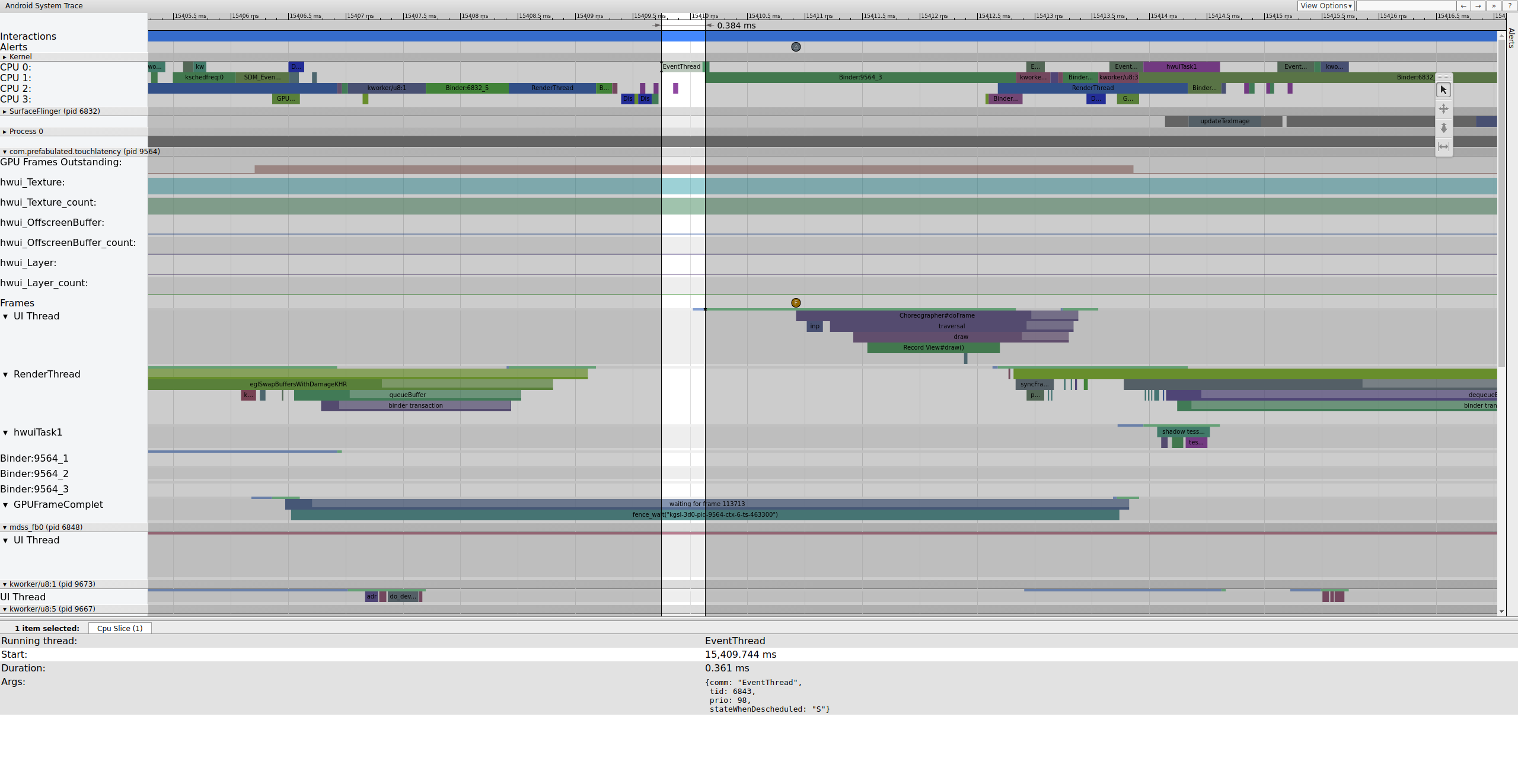
Abbildung 1: Normale UI-Pipeline, EventThread wird ausgeführt.
Abbildung 1 ist ein normaler Frame, der von normalen Frames umgeben ist. Sie ist also ein guter Ausgangspunkt, um die Funktionsweise der UI-Pipeline zu verstehen. Die Zeile für den UI-Thread für „TouchLatency“ hat zu verschiedenen Zeiten unterschiedliche Farben. Die Balken stehen für verschiedene Status des Threads:
- Grau Schlafen
- Blau Ausführbar (könnte ausgeführt werden, wurde aber noch nicht vom Scheduler ausgewählt).
- Grün Wird aktiv ausgeführt (der Scheduler geht davon aus, dass er ausgeführt wird).
- Rot: Unterbrechungsfreier Schlaf (normalerweise Schlaf auf einem Lock im Kernel). Kann auf eine hohe I/O-Last hinweisen. Sehr nützlich für die Fehlerbehebung bei Leistungsproblemen.
- Orange Unterbrechungsfreier Schlaf aufgrund von E/A-Last.
Wenn Sie den Grund für den ununterbrochenen Schlaf (verfügbar über den sched_blocked_reason-Tracepoint) sehen möchten, wählen Sie den roten Abschnitt für ununterbrochenen Schlaf aus.
Während EventThread ausgeführt wird, wird der UI-Thread für TouchLatency ausführbar. Wenn Sie sehen möchten, was das Gerät aktiviert hat, klicken Sie auf den blauen Bereich.

Abbildung 2: UI-Thread für TouchLatency.
Abbildung 2 zeigt, dass der TouchLatency-UI-Thread durch die Thread-ID 6843 reaktiviert wurde, die dem EventThread entspricht. Der UI-Thread wird aktiviert, rendert einen Frame und stellt ihn für SurfaceFlinger in die Warteschlange.
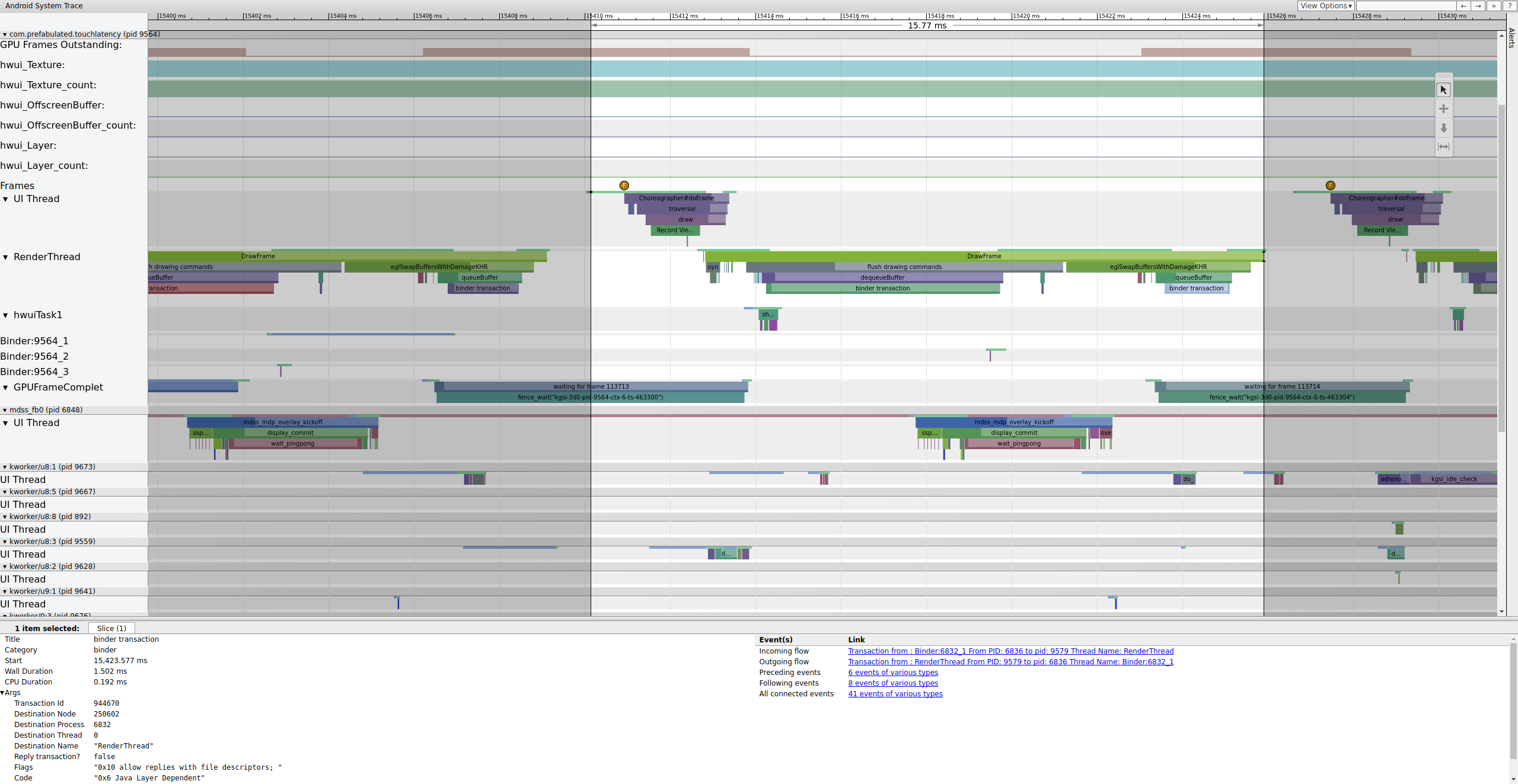
Abbildung 3: Der UI-Thread wird aktiviert, rendert einen Frame und stellt ihn für SurfaceFlinger in die Warteschlange.
Wenn das binder_driver-Tag in einem Trace aktiviert ist, können Sie eine Binder-Transaktion auswählen, um Informationen zu allen Prozessen aufzurufen, die an dieser Transaktion beteiligt sind.
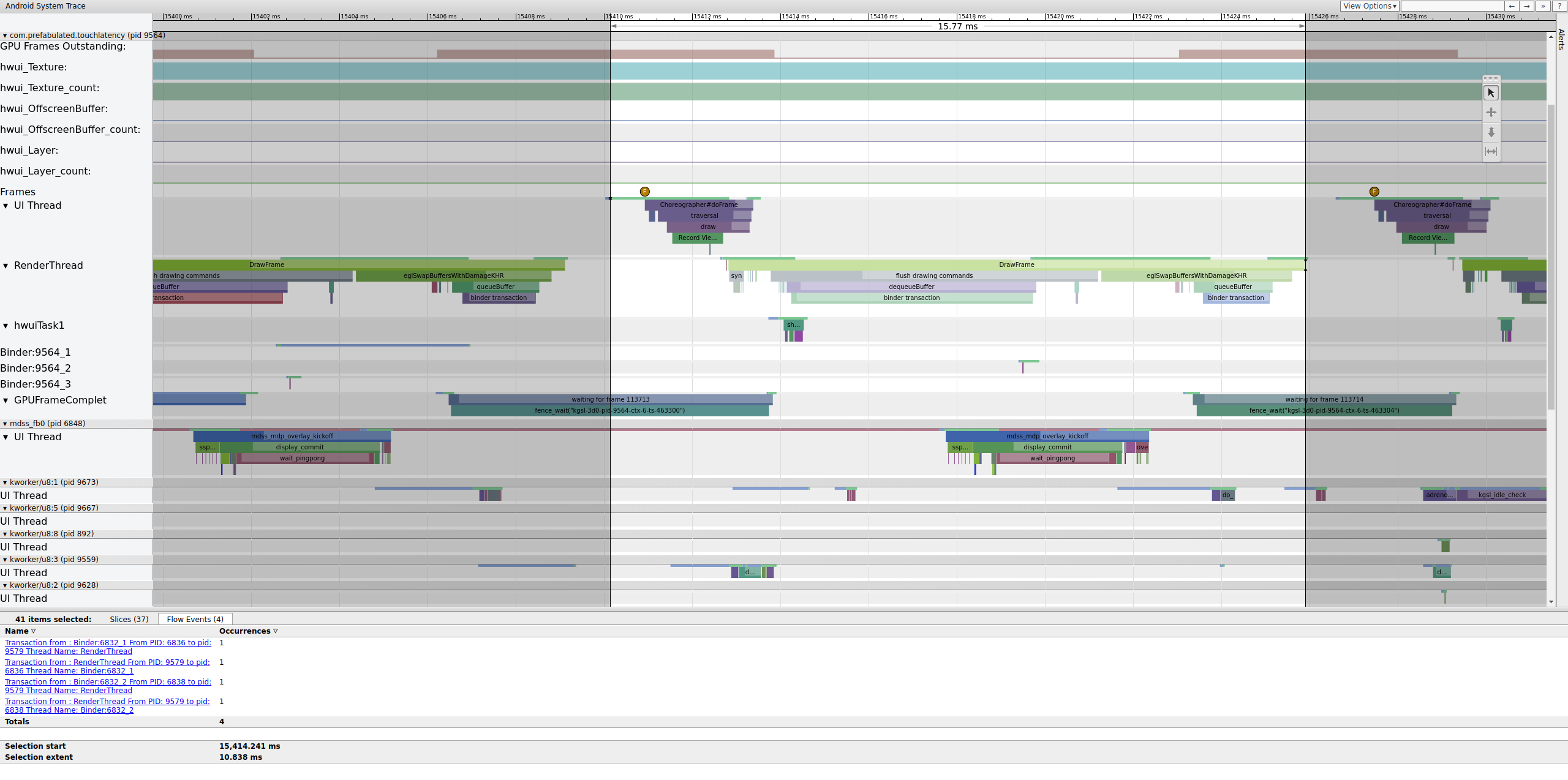
Abbildung 4: Binder-Transaktion.
Abbildung 4 zeigt, dass Binder:6832_1 in SurfaceFlinger bei 15.423,65 ms aufgrund von tid 9579, dem RenderThread von TouchLatency, ausführbar wird. Sie können „queueBuffer“ auch auf beiden Seiten der Binder-Transaktion sehen.
Während des queueBuffer auf der SurfaceFlinger-Seite steigt die Anzahl der ausstehenden Frames von TouchLatency von 1 auf 2.
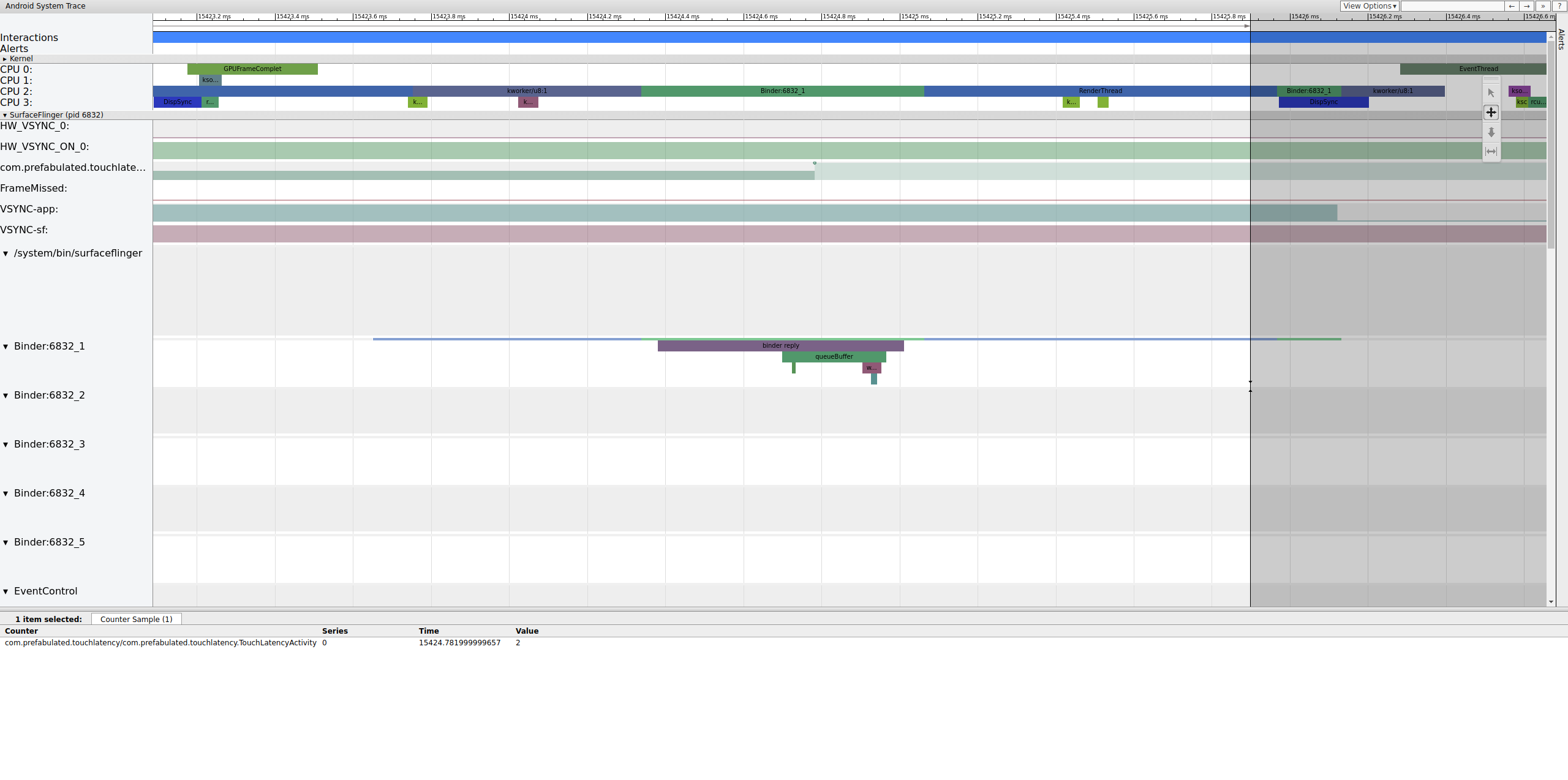
Abbildung 5: Die Anzahl der ausstehenden Frames liegt zwischen 1 und 2.
Abbildung 5 zeigt die dreifache Pufferung. Es sind zwei gerenderte Frames vorhanden und die App beginnt mit dem Rendern eines dritten. Das liegt daran, dass wir bereits einige Frames verworfen haben. Die App behält also zwei ausstehende Frames anstelle von einem bei, um weitere verworfene Frames zu vermeiden.
Kurz darauf wird der Hauptthread von SurfaceFlinger durch einen zweiten EventThread reaktiviert, damit er den älteren ausstehenden Frame auf dem Display ausgeben kann:
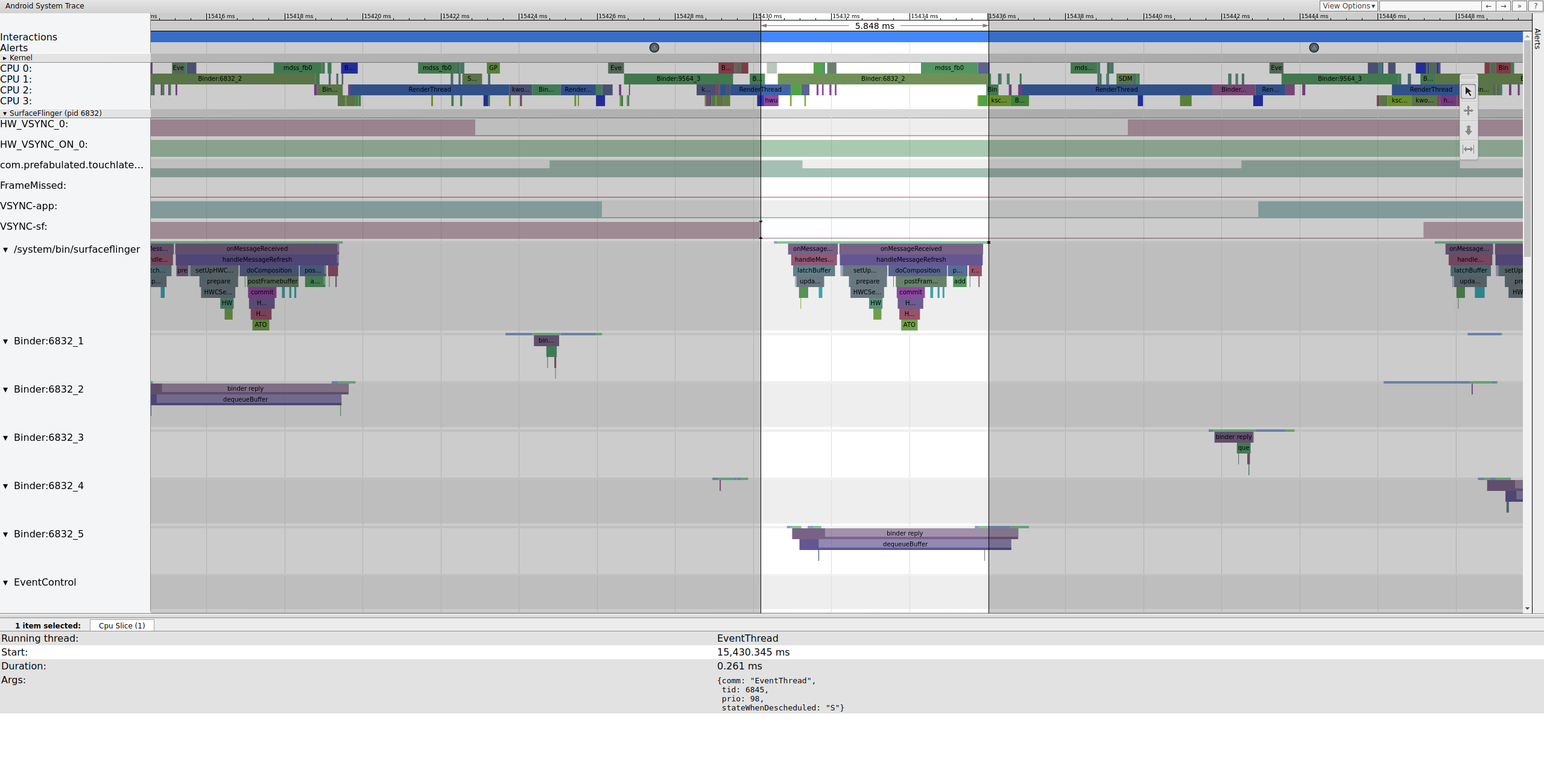
Abbildung 6 Der Hauptthread von SurfaceFlinger wird von einem zweiten EventThread reaktiviert.
SurfaceFlinger übernimmt zuerst den älteren ausstehenden Puffer, wodurch die Anzahl der ausstehenden Puffer von 2 auf 1 sinkt:
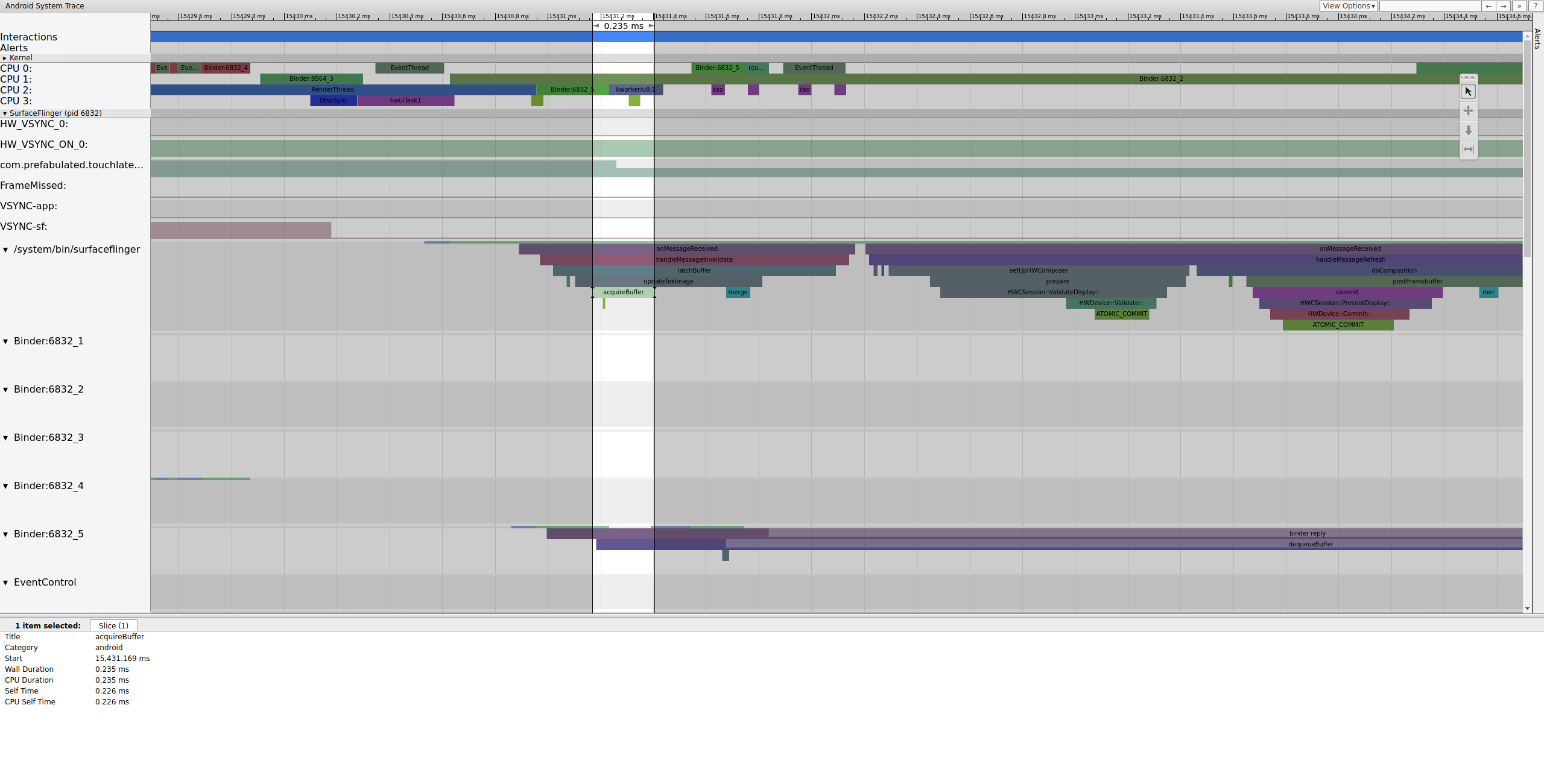
Abbildung 7. SurfaceFlinger greift zuerst auf den älteren ausstehenden Puffer zu.
Nachdem der Puffer verriegelt wurde, richtet SurfaceFlinger die Komposition ein und übergibt den endgültigen Frame an das Display. Einige dieser Abschnitte sind als Teil des mdss-Tracepoints aktiviert und sind daher möglicherweise nicht auf Ihrem SoC enthalten.

Abbildung 8. SurfaceFlinger richtet die Komposition ein und sendet den endgültigen Frame.
Als Nächstes wird mdss_fb0 auf CPU 0 aktiviert. mdss_fb0 ist der Kernel-Thread der Display-Pipeline für die Ausgabe eines gerenderten Frames auf dem Display.
mdss_fb0 wird in einer eigenen Zeile im Trace angezeigt (scrollen Sie nach unten, um sie zu sehen):
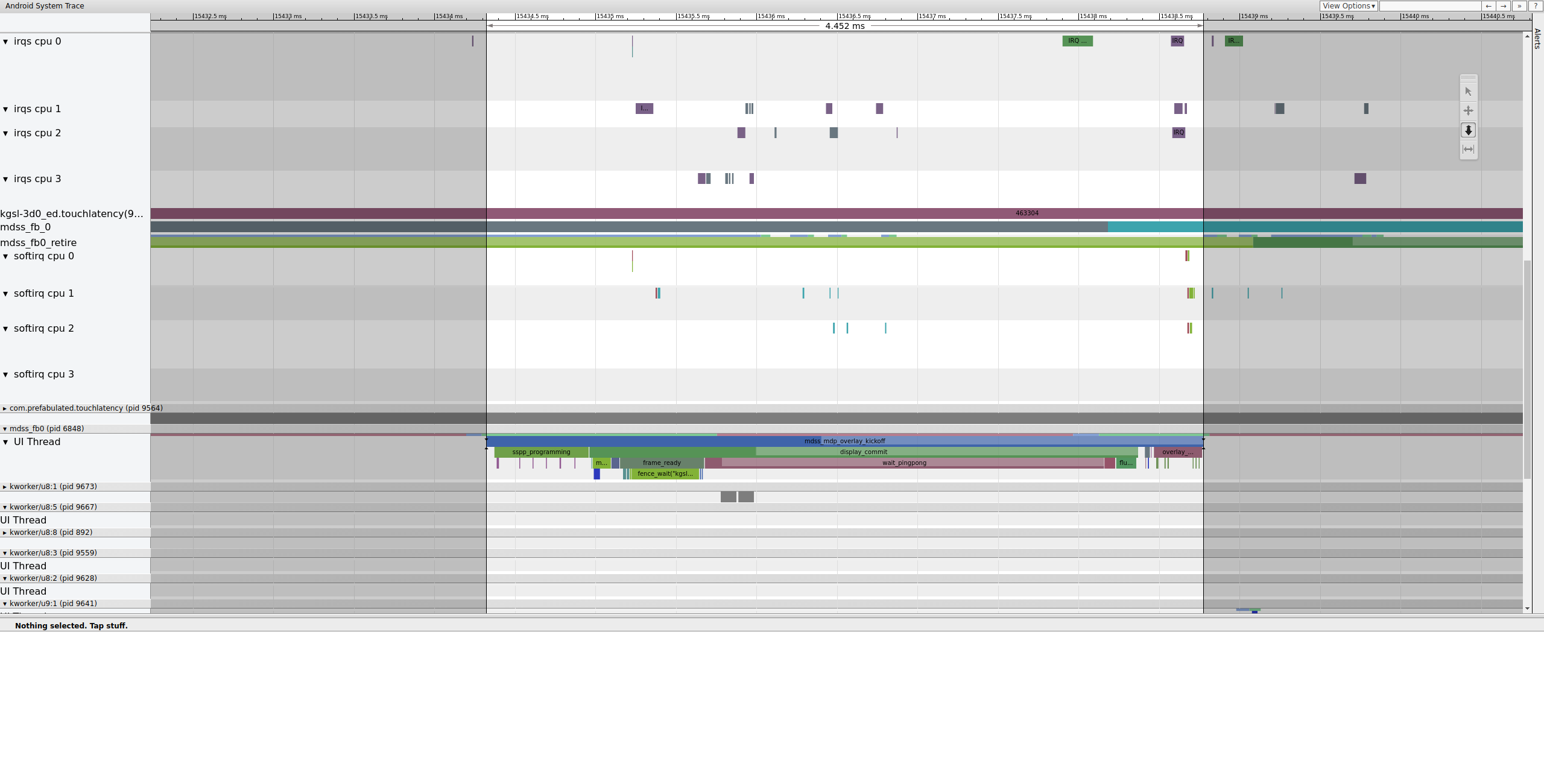
Abbildung 9. mdss_fb0 wird auf CPU 0 aktiviert.
mdss_fb0 wacht auf, läuft kurz, geht in den unterbrechungsfreien Schlaf und wacht dann wieder auf.
Beispiel: Nicht funktionierender Frame
In diesem Beispiel wird ein Systrace beschrieben, das zum Debuggen von Jitter auf dem Pixel oder Pixel XL verwendet wird. Wenn Sie dem Beispiel folgen möchten, laden Sie die ZIP-Datei mit den Traces herunter (sie enthält auch andere Traces, auf die in diesem Abschnitt verwiesen wird), entpacken Sie die Datei und öffnen Sie die systrace_tutorial.html-Datei in Ihrem Browser.
Wenn Sie den Systrace öffnen, sehen Sie etwa Folgendes:

Abbildung 10. TouchLatency auf dem Pixel XL mit den meisten Optionen aktiviert.
In Abbildung 10 sind die meisten Optionen aktiviert, einschließlich der Tracepoints mdss und kgsl.
Wenn Sie nach Rucklern suchen, sehen Sie sich die Zeile „FrameMissed“ unter „SurfaceFlinger“ an.
„FrameMissed“ ist eine Funktion des HWC2, die die Nutzung erleichtert. Wenn Sie den Systrace-Bericht für andere Geräte ansehen, ist die Zeile „FrameMissed“ möglicherweise nicht vorhanden, wenn das Gerät nicht HWC2 verwendet. In beiden Fällen korreliert „FrameMissed“ damit, dass SurfaceFlinger eine seiner regulären Laufzeiten verpasst hat und die Anzahl der ausstehenden Puffer für die App (com.prefabulated.touchlatency) bei einem VSync unverändert ist.

Abbildung 11. Korrelation von „FrameMissed“ mit SurfaceFlinger.
Abbildung 11 zeigt einen ausgelassenen Frame bei 15.598,29 ms. SurfaceFlinger wurde kurzzeitig im VSync-Intervall aktiviert und wechselte dann wieder in den Ruhemodus, ohne etwas zu tun. Das bedeutet, dass SurfaceFlinger entschieden hat, dass es sich nicht lohnt, noch einmal zu versuchen, einen Frame an das Display zu senden.
Um zu verstehen, warum die Pipeline für diesen Frame unterbrochen wurde, sehen Sie sich zuerst das Beispiel für einen funktionierenden Frame oben an, um zu sehen, wie eine normale UI-Pipeline in Systrace aussieht. Wenn Sie bereit sind, kehren Sie zum verpassten Frame zurück und arbeiten Sie rückwärts. SurfaceFlinger wird aktiviert und wechselt sofort wieder in den Ruhemodus. Wenn Sie sich die Anzahl der ausstehenden Frames von TouchLatency ansehen, gibt es zwei Frames. Das ist ein guter Hinweis darauf, was passiert.
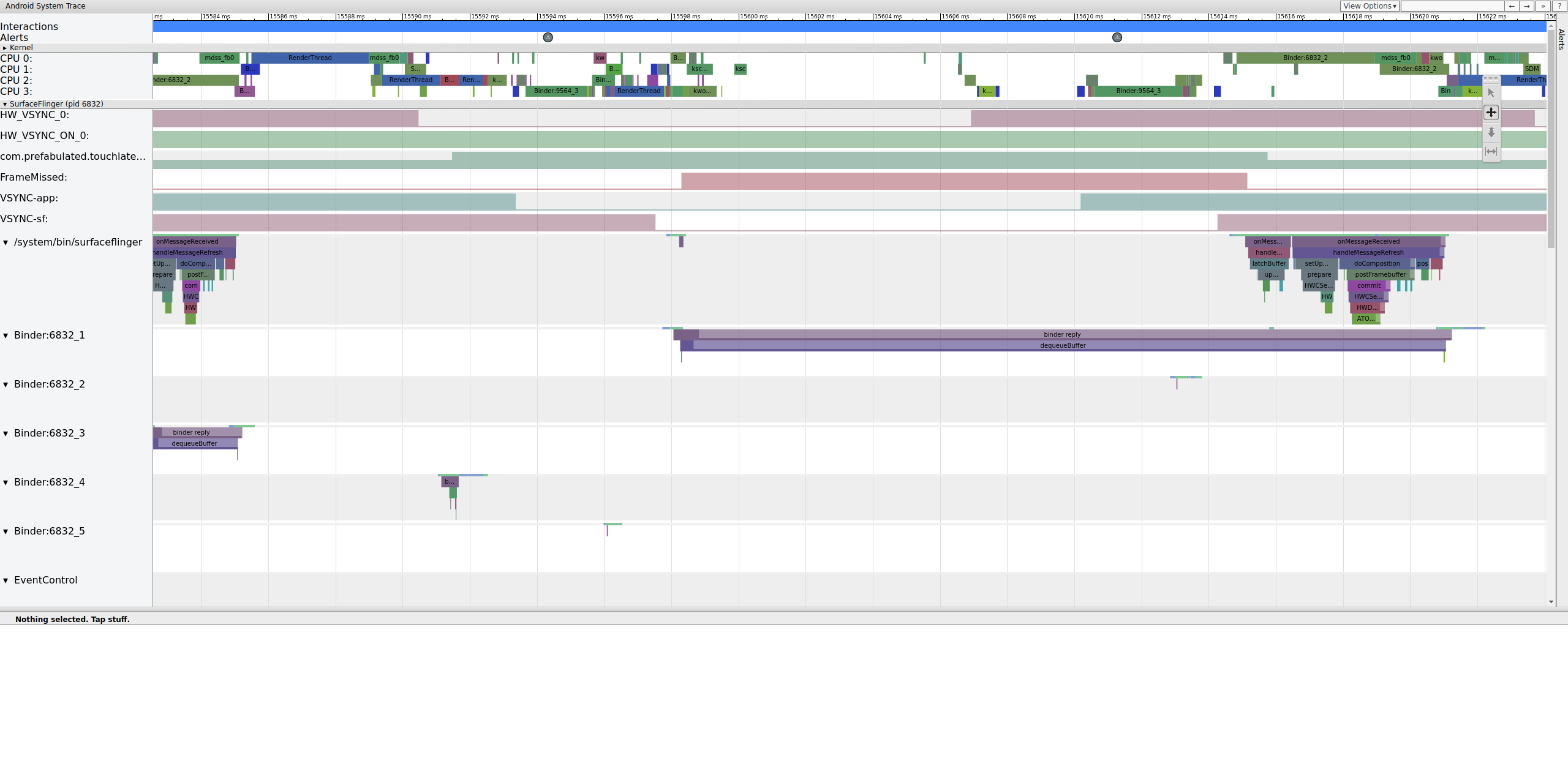
Abbildung 12. SurfaceFlinger wird aktiviert und wechselt sofort wieder in den Ruhezustand.
Da es Frames in SurfaceFlinger gibt, handelt es sich nicht um ein App-Problem. Außerdem wird SurfaceFlinger zur richtigen Zeit aktiviert. Es handelt sich also nicht um ein SurfaceFlinger-Problem. Wenn SurfaceFlinger und die App beide normal aussehen, liegt wahrscheinlich ein Treiberproblem vor.
Da die Tracepoints mdss und sync aktiviert sind, können Sie Informationen zu den Fences (die zwischen dem Displaytreiber und SurfaceFlinger geteilt werden) abrufen, die steuern, wann Frames an das Display gesendet werden.
Diese Fences sind unter mdss_fb0_retire aufgeführt. Sie geben an, wann ein Frame auf dem Display angezeigt wird. Diese Zäune sind Teil der Trace-Kategorie sync. Welche Fences bestimmten Ereignissen in SurfaceFlinger entsprechen, hängt von Ihrem SOC und Treiberstack ab. Wenden Sie sich daher an Ihren SOC-Anbieter, um die Bedeutung der Fence-Kategorien in Ihren Traces zu verstehen.

Abbildung 13. mdss_fb0_retire fences.
Abbildung 13 zeigt einen Frame, der 33 ms lang angezeigt wurde, nicht wie erwartet 16,7 ms. Auf halbem Weg durch diesen Slice sollte dieser Frame durch einen neuen ersetzt werden, was aber nicht passiert ist. Sehen Sie sich den vorherigen Frame an und suchen Sie nach Auffälligkeiten.
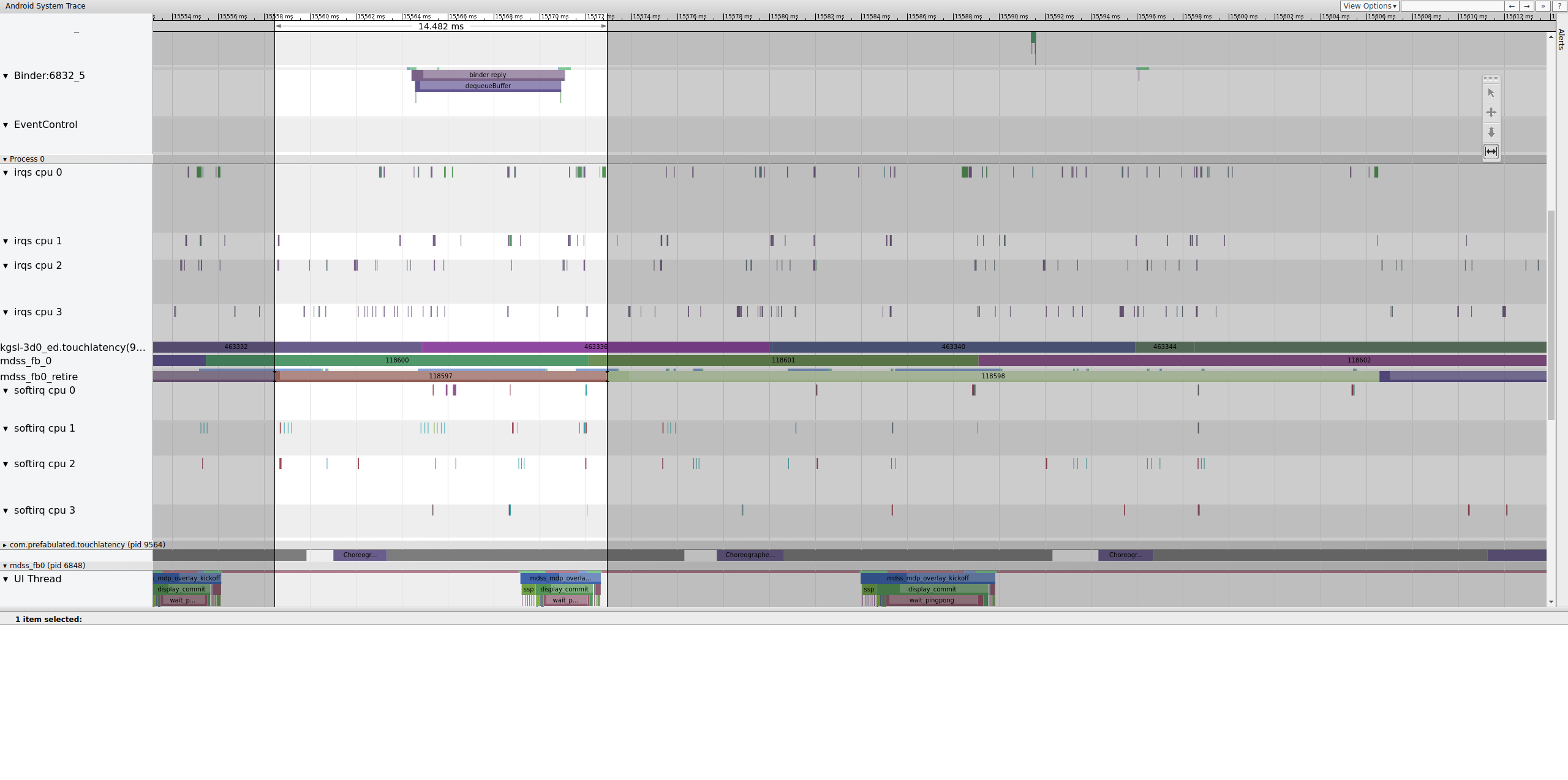
Abbildung 14. Frame vor dem fehlerhaften Frame.
Abbildung 14 zeigt einen Frame mit einer Dauer von 14.482 ms. Das unterbrochene Segment mit zwei Frames dauerte 33,6 ms, was ungefähr dem entspricht, was für zwei Frames erwartet wird (gerendert mit 60 Hz, 16,7 ms pro Frame, was nah dran ist). 14,482 ms sind jedoch nicht annähernd 16,7 ms. Das deutet darauf hin, dass etwas mit dem Display-Pipeline nicht stimmt.
Sehen Sie sich genau an, wo die Grenze endet, um festzustellen, welche Steuerelemente dafür verantwortlich sind:
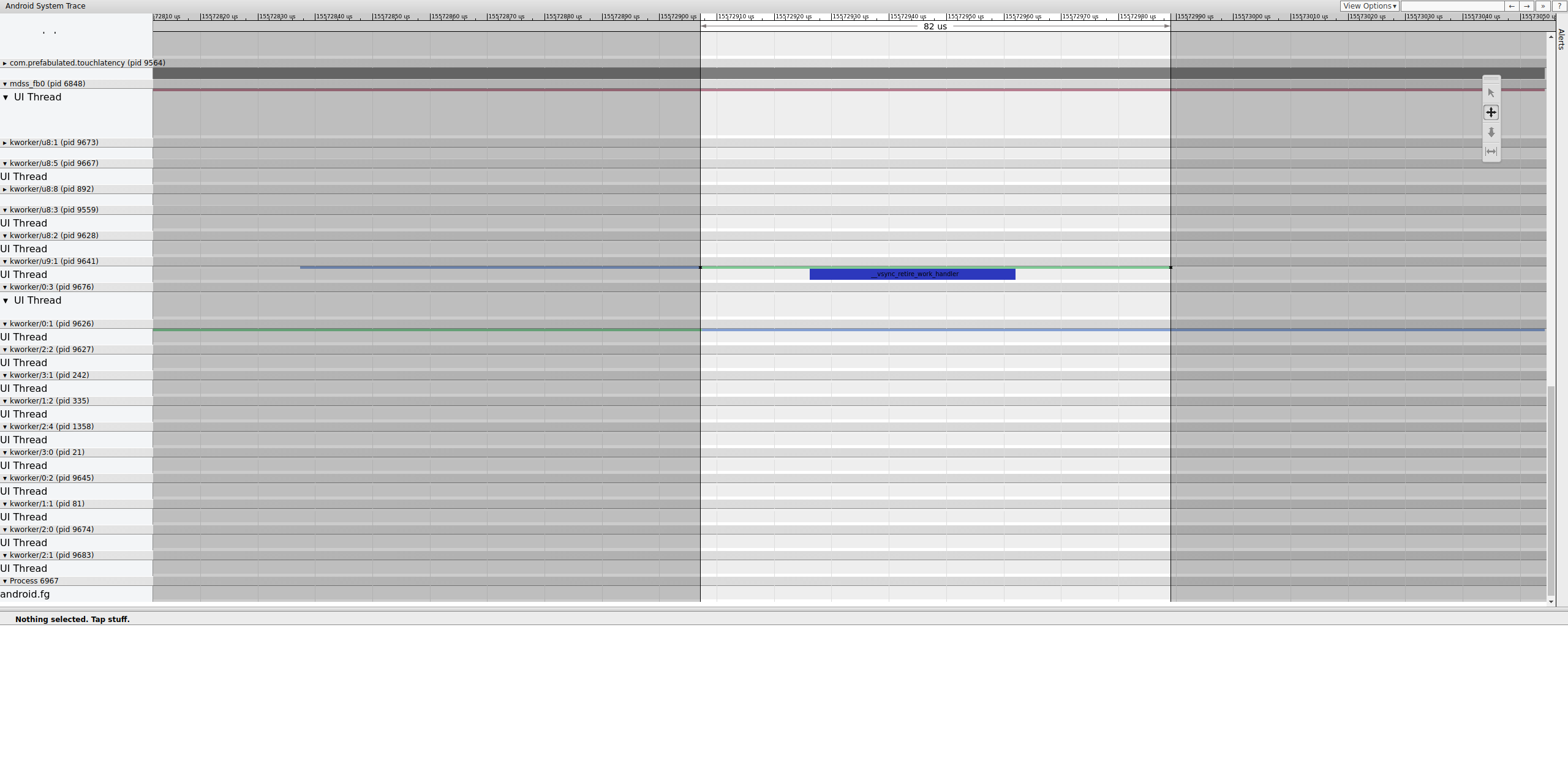
Abbildung 15. Untersuchen Sie das Ende des Zauns.
Eine Arbeitswarteschlange enthält __vsync_retire_work_handler, die ausgeführt wird, wenn sich der Fence ändert. Wenn Sie sich den Kernel-Quellcode ansehen, können Sie sehen, dass er Teil des Displaytreibers ist. Sie scheint sich auf dem kritischen Pfad für die Display-Pipeline zu befinden und muss daher so schnell wie möglich ausgeführt werden. Sie kann etwa 70 μs lang ausgeführt werden (keine lange Planungsverzögerung), aber es handelt sich um eine Workqueue, die möglicherweise nicht genau geplant wird.
Sehen Sie sich den vorherigen Frame an, um festzustellen, ob er dazu beigetragen hat. Manchmal kann sich Jitter im Laufe der Zeit summieren und schließlich zu einer verpassten Deadline führen:
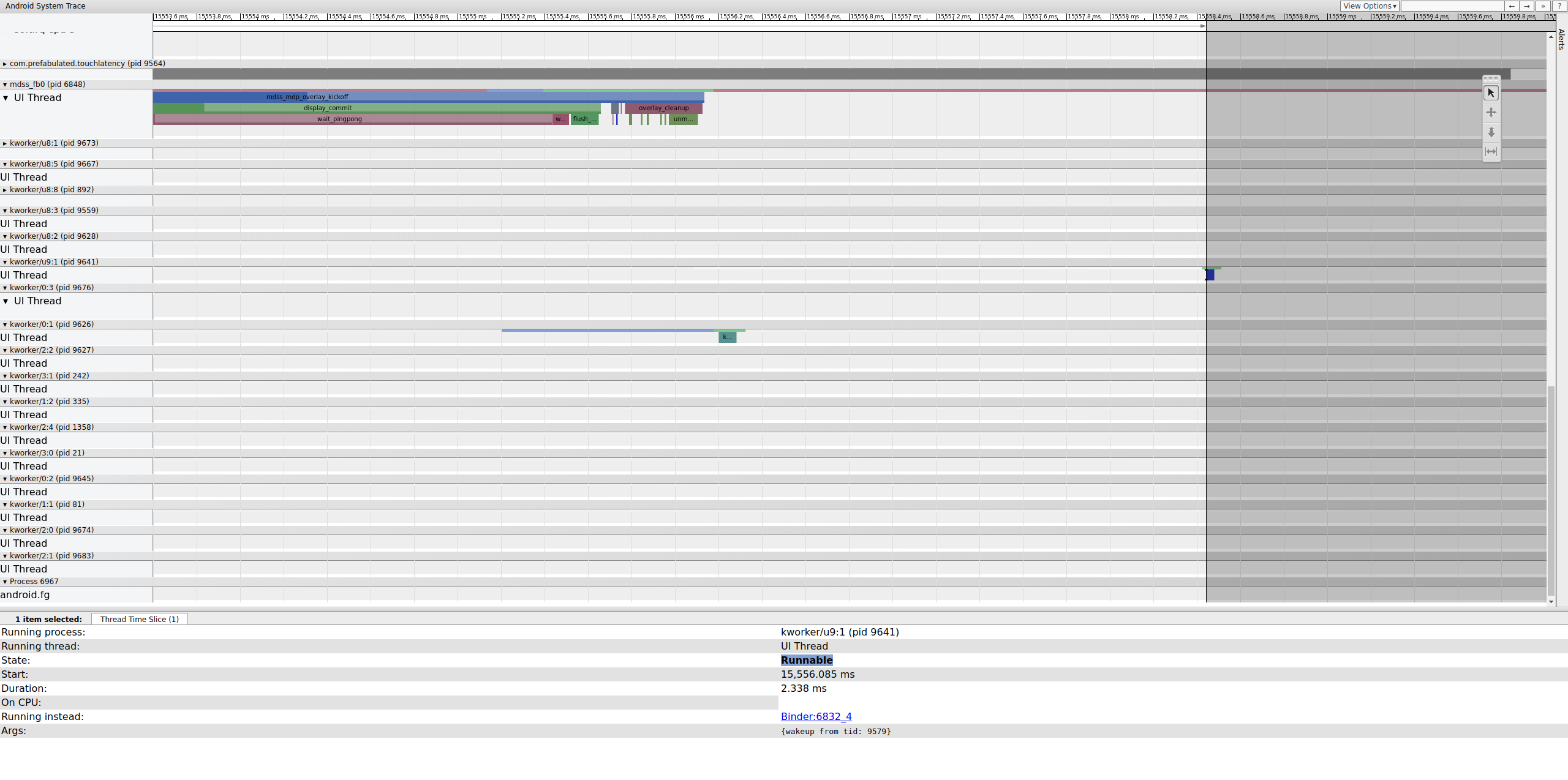
Abbildung 16: Vorheriger Frame.
Die ausführbare Zeile für den kworker ist nicht sichtbar, da sie vom Betrachter weiß dargestellt wird, wenn sie ausgewählt ist.Die Statistiken sprechen jedoch für sich: Eine Planerverzögerung von 2,3 ms für einen Teil des kritischen Pfads der Display-Pipeline ist schlecht.
Bevor Sie fortfahren, beheben Sie die Verzögerung, indem Sie diesen Teil des kritischen Pfads der Display-Pipeline von einer Workqueue (die als SCHED_OTHER-CFS-Thread ausgeführt wird) zu einem dedizierten SCHED_FIFO-Kthread verschieben. Diese Funktion erfordert Timing-Garantien, die Workqueues nicht bieten können (und auch nicht bieten sollen).
Es ist nicht klar, ob das der Grund für die Ruckler ist. Außerhalb von Fällen, die sich leicht diagnostizieren lassen, z. B. wenn Kernel-Locks zu Konflikten führen, die dazu führen, dass displaykritische Threads in den Ruhezustand versetzt werden, wird das Problem in Traces in der Regel nicht angegeben. Dieser Jitter könnte die Ursache für den Frame-Drop gewesen sein. Die Fence-Zeiten sollten 16,7 ms betragen, aber in den Frames vor dem ausgelassenen Frame sind sie überhaupt nicht in der Nähe dieses Werts. Da die Display-Pipeline so eng gekoppelt ist, kann es sein, dass der Jitter bei den Fence-Timings zu einem ausgelassenen Frame geführt hat.
In diesem Beispiel wird __vsync_retire_work_handler von einer Workqueue in einen dedizierten kthread konvertiert. Dadurch wird das Ruckeln beim Test mit dem hüpfenden Ball deutlich reduziert. Nachfolgende Traces zeigen Fence-Zeiten, die sehr nahe an 16,7 ms liegen.