
Android 8.0-এ থ্রুপুট এবং লেটেন্সির জন্য বাইন্ডার এবং hwbinder পারফরম্যান্স পরীক্ষা রয়েছে। যদিও উপলব্ধিযোগ্য কর্মক্ষমতা সমস্যা সনাক্ত করার জন্য অনেকগুলি পরিস্থিতি বিদ্যমান, এই ধরনের পরিস্থিতিগুলি চালানো সময়সাপেক্ষ হতে পারে এবং একটি সিস্টেম একীভূত না হওয়া পর্যন্ত ফলাফলগুলি প্রায়শই অনুপলব্ধ হয়৷ প্রদত্ত কর্মক্ষমতা পরীক্ষাগুলি ব্যবহার করে বিকাশের সময় পরীক্ষা করা, আগে গুরুতর সমস্যাগুলি সনাক্ত করা এবং ব্যবহারকারীর অভিজ্ঞতা উন্নত করা সহজ করে তোলে।
কর্মক্ষমতা পরীক্ষা নিম্নলিখিত চারটি বিভাগ অন্তর্ভুক্ত:
- বাইন্ডার থ্রুপুট (
system/libhwbinder/vts/performance/Benchmark_binder.cppএ উপলব্ধ) - বাইন্ডার লেটেন্সি (
frameworks/native/libs/binder/tests/schd-dbg.cppএ উপলব্ধ) - hwbinder থ্রুপুট (
system/libhwbinder/vts/performance/Benchmark.cppএ উপলব্ধ) - hwbinder লেটেন্সি (
system/libhwbinder/vts/performance/Latency.cppএ উপলব্ধ)
বাইন্ডার এবং hwbinder সম্পর্কে
বাইন্ডার এবং hwbinder হল অ্যান্ড্রয়েড ইন্টার-প্রসেস কমিউনিকেশন (IPC) অবকাঠামো যা একই লিনাক্স ড্রাইভার ভাগ করে কিন্তু নিম্নলিখিত গুণগত পার্থক্য রয়েছে:
| দৃষ্টিভঙ্গি | বাইন্ডার | hwbinder |
|---|---|---|
| উদ্দেশ্য | কাঠামোর জন্য একটি সাধারণ উদ্দেশ্য IPC স্কিম প্রদান করুন | হার্ডওয়্যারের সাথে যোগাযোগ করুন |
| সম্পত্তি | অ্যান্ড্রয়েড ফ্রেমওয়ার্ক ব্যবহারের জন্য অপ্টিমাইজ করা হয়েছে | ন্যূনতম ওভারহেড কম লেটেন্সি |
| অগ্রভাগ/পটভূমির জন্য সময়সূচী নীতি পরিবর্তন করুন | হ্যাঁ | না |
| আর্গুমেন্ট পাস | পার্সেল অবজেক্ট দ্বারা সমর্থিত সিরিয়ালাইজেশন ব্যবহার করে | স্ক্যাটার বাফার ব্যবহার করে এবং পার্সেল সিরিয়ালাইজেশনের জন্য প্রয়োজনীয় ডেটা কপি করতে ওভারহেড এড়িয়ে যায় |
| অগ্রাধিকার উত্তরাধিকার | না | হ্যাঁ |
বাইন্ডার এবং hwbinder প্রক্রিয়া
একটি সিস্ট্রেস ভিজ্যুয়ালাইজার নিম্নরূপ লেনদেন প্রদর্শন করে:
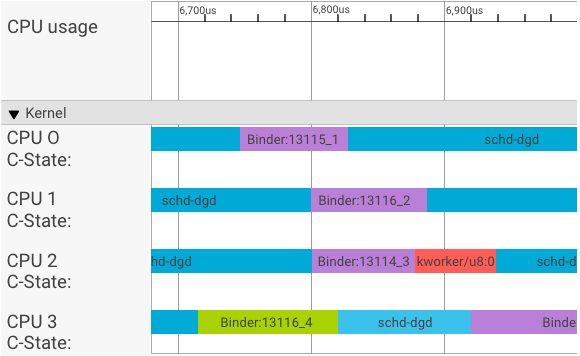
উপরের উদাহরণে:
- চারটি (4) schd-dbg প্রক্রিয়া হল ক্লায়েন্ট প্রক্রিয়া।
- চারটি (4) বাইন্ডার প্রক্রিয়া হল সার্ভার প্রক্রিয়া (নামটি বাইন্ডার দিয়ে শুরু হয় এবং একটি ক্রম সংখ্যা দিয়ে শেষ হয়)।
- একটি ক্লায়েন্ট প্রক্রিয়া সর্বদা একটি সার্ভার প্রক্রিয়ার সাথে যুক্ত থাকে, যা তার ক্লায়েন্টের জন্য উত্সর্গীকৃত।
- সমস্ত ক্লায়েন্ট-সার্ভার প্রক্রিয়া জোড়া একযোগে কার্নেল দ্বারা স্বাধীনভাবে নির্ধারিত হয়।
CPU 1-এ, OS কার্নেল ক্লায়েন্টকে অনুরোধটি ইস্যু করতে কার্যকর করে। যখনই সম্ভব সার্ভার প্রক্রিয়া জাগিয়ে তুলতে, অনুরোধটি পরিচালনা করতে এবং অনুরোধ সম্পূর্ণ হওয়ার পরে প্রসঙ্গটি ফিরে যেতে এটি একই CPU ব্যবহার করে।
থ্রুপুট বনাম লেটেন্সি
একটি নিখুঁত লেনদেনে, যেখানে ক্লায়েন্ট এবং সার্ভার প্রক্রিয়া নির্বিঘ্নে সুইচ করে, থ্রুপুট এবং লেটেন্সি পরীক্ষাগুলি উল্লেখযোগ্যভাবে ভিন্ন বার্তা তৈরি করে না। যাইহোক, যখন OS কার্নেল হার্ডওয়্যার থেকে একটি ইন্টারাপ্ট রিকোয়েস্ট (IRQ) পরিচালনা করছে, লকের জন্য অপেক্ষা করছে, অথবা শুধুমাত্র একটি বার্তা অবিলম্বে পরিচালনা না করা বেছে নেবে, তখন একটি লেটেন্সি বাবল তৈরি হতে পারে।

থ্রুপুট পরীক্ষা বিভিন্ন পেলোড আকারের সাথে প্রচুর সংখ্যক লেনদেন তৈরি করে, নিয়মিত লেনদেনের সময় (সর্বোত্তম ক্ষেত্রে) এবং বাইন্ডারের সর্বোচ্চ থ্রুপুট অর্জনের জন্য একটি ভাল অনুমান প্রদান করে।
বিপরীতে, লেটেন্সি পরীক্ষা নিয়মিত লেনদেনের সময় কমানোর জন্য পেলোডে কোনো কাজ করে না। আমরা বাইন্ডার ওভারহেড অনুমান করতে লেনদেনের সময় ব্যবহার করতে পারি, সবচেয়ে খারাপ ক্ষেত্রে পরিসংখ্যান তৈরি করতে পারি এবং লেনদেনের অনুপাত গণনা করতে পারি যার লেটেন্সি একটি নির্দিষ্ট সময়সীমা পূরণ করে।
অগ্রাধিকার বিপরীত হ্যান্ডেল
একটি অগ্রাধিকার বিপর্যয় ঘটে যখন উচ্চ অগ্রাধিকার সহ একটি থ্রেড যৌক্তিকভাবে নিম্ন অগ্রাধিকার সহ একটি থ্রেডের জন্য অপেক্ষা করে। রিয়েল-টাইম (RT) অ্যাপ্লিকেশনগুলির একটি অগ্রাধিকার বিপরীত সমস্যা রয়েছে:
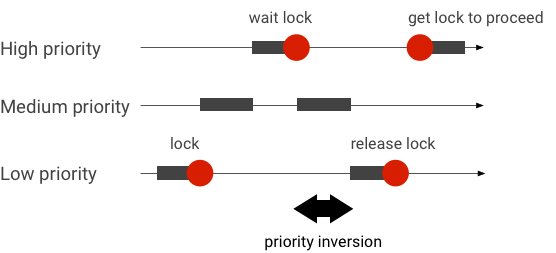
Linux Completely Fair Scheduler (CFS) শিডিউলিং ব্যবহার করার সময়, অন্যান্য থ্রেডের অগ্রাধিকার থাকলেও একটি থ্রেড সবসময় চালানোর সুযোগ থাকে। ফলস্বরূপ, CFS শিডিউলিং সহ অ্যাপ্লিকেশনগুলি প্রত্যাশিত আচরণ হিসাবে অগ্রাধিকার বিপরীতকে পরিচালনা করে এবং সমস্যা হিসাবে নয়। যে ক্ষেত্রে Android ফ্রেমওয়ার্কের উচ্চ অগ্রাধিকার থ্রেডের সুবিধার গ্যারান্টি দেওয়ার জন্য RT শিডিউলিংয়ের প্রয়োজন হয়, তবে অগ্রাধিকার পরিবর্তনের সমাধান করা আবশ্যক।
একটি বাইন্ডার লেনদেনের সময় অগ্রাধিকার বিপরীত উদাহরণ (RT থ্রেড যৌক্তিকভাবে অন্যান্য CFS থ্রেড দ্বারা ব্লক করা হয় যখন পরিষেবাতে বাইন্ডার থ্রেডের জন্য অপেক্ষা করা হয়):
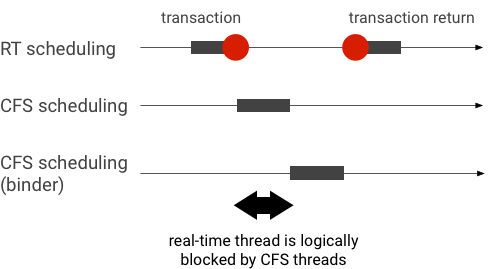
ব্লকেজ এড়াতে, আপনি বাইন্ডার থ্রেডকে সাময়িকভাবে RT থ্রেডে বাড়ানোর জন্য অগ্রাধিকারের উত্তরাধিকার ব্যবহার করতে পারেন যখন এটি একটি RT ক্লায়েন্টের কাছ থেকে একটি অনুরোধ করে। মনে রাখবেন যে RT শিডিউলিংয়ের সীমিত সংস্থান রয়েছে এবং সাবধানে ব্যবহার করা উচিত। n CPU সহ একটি সিস্টেমে, বর্তমান RT থ্রেডের সর্বাধিক সংখ্যাও n ; অতিরিক্ত RT থ্রেডের জন্য অপেক্ষা করতে হতে পারে (এবং এইভাবে তাদের সময়সীমা মিস) যদি সমস্ত CPU অন্যান্য RT থ্রেড দ্বারা নেওয়া হয়।
সমস্ত সম্ভাব্য অগ্রাধিকার বিপরীত সমাধান করতে, আপনি বাইন্ডার এবং hwbinder উভয়ের জন্য অগ্রাধিকার উত্তরাধিকার ব্যবহার করতে পারেন। যাইহোক, যেহেতু বাইন্ডারটি সিস্টেম জুড়ে ব্যাপকভাবে ব্যবহৃত হয়, তাই বাইন্ডার লেনদেনের জন্য অগ্রাধিকার উত্তরাধিকার সক্ষম করলে এটি পরিষেবার চেয়ে বেশি RT থ্রেড দিয়ে সিস্টেমটিকে স্প্যাম করতে পারে।
থ্রুপুট পরীক্ষা চালান
থ্রুপুট পরীক্ষাটি বাইন্ডার/হববিন্ডার লেনদেন থ্রুপুটের বিরুদ্ধে চালানো হয়। ওভারলোড করা হয় না এমন একটি সিস্টেমে, লেটেন্সি বুদবুদগুলি বিরল এবং তাদের প্রভাবগুলি দূর করা যেতে পারে যতক্ষণ না পুনরাবৃত্তির সংখ্যা যথেষ্ট বেশি হয়।
- বাইন্ডার থ্রুপুট পরীক্ষাটি
system/libhwbinder/vts/performance/Benchmark_binder.cppএ রয়েছে। - hwbinder থ্রুপুট পরীক্ষা হল
system/libhwbinder/vts/performance/Benchmark.cpp।
পরীক্ষার ফলাফল
বিভিন্ন পেলোড আকার ব্যবহার করে লেনদেনের জন্য থ্রুপুট পরীক্ষার ফলাফলের উদাহরণ:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- সময় নির্দেশ করে রাউন্ড ট্রিপ বিলম্ব রিয়েল টাইমে পরিমাপ করা হয়।
- সিপিইউ পরীক্ষার জন্য নির্ধারিত সময়ে জমা হওয়া সময় নির্দেশ করে।
- পুনরাবৃত্তিগুলি পরীক্ষা ফাংশনটি কতবার কার্যকর করা হয়েছে তা নির্দেশ করে।
উদাহরণস্বরূপ, একটি 8-বাইট পেলোডের জন্য:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… বাইন্ডার যে সর্বাধিক থ্রুপুট অর্জন করতে পারে তা হিসাবে গণনা করা হয়:
8-বাইট পেলোড = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s সহ MAX থ্রুপুট
পরীক্ষার বিকল্প
.json-এ ফলাফল পেতে, --benchmark_format=json আর্গুমেন্ট দিয়ে পরীক্ষা চালান:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}লেটেন্সি পরীক্ষা চালান
লেটেন্সি টেস্ট ক্লায়েন্টের লেনদেন শুরু করতে, পরিচালনার জন্য সার্ভার প্রক্রিয়াতে স্যুইচ করতে এবং ফলাফল পেতে সময় লাগে তা পরিমাপ করে। পরীক্ষাটি পরিচিত খারাপ সময়সূচীর আচরণেরও সন্ধান করে যা লেনদেনের বিলম্বকে নেতিবাচকভাবে প্রভাবিত করতে পারে, যেমন একটি শিডিউলকারী যা অগ্রাধিকার উত্তরাধিকার সমর্থন করে না বা সিঙ্ক পতাকাকে সম্মান করে না।
- বাইন্ডার লেটেন্সি টেস্ট
frameworks/native/libs/binder/tests/schd-dbg.cppএ হয়। - hwbinder লেটেন্সি পরীক্ষা
system/libhwbinder/vts/performance/Latency.cppএ হয়।
পরীক্ষার ফলাফল
ফলাফল (.json-এ) গড়/সর্বোত্তম/সবচেয়ে খারাপ লেটেন্সির পরিসংখ্যান এবং মিস করা সময়সীমার সংখ্যা দেখায়।
পরীক্ষার বিকল্প
লেটেন্সি পরীক্ষাগুলি নিম্নলিখিত বিকল্পগুলি গ্রহণ করে:
| আদেশ | বর্ণনা |
|---|---|
-i value | পুনরাবৃত্তির সংখ্যা নির্দিষ্ট করুন। |
-pair value | প্রক্রিয়া জোড়া সংখ্যা উল্লেখ করুন. |
-deadline_us 2500 | আমাদের মধ্যে সময়সীমা নির্দিষ্ট করুন. |
-v | ভার্বোস (ডিবাগিং) আউটপুট পান। |
-trace | একটি সময়সীমা আঘাত ট্রেস থামান. |
নিম্নলিখিত বিভাগগুলি প্রতিটি বিকল্পের বিশদ বিবরণ দেয়, ব্যবহার বর্ণনা করে এবং উদাহরণের ফলাফল প্রদান করে।
পুনরাবৃত্তি নির্দিষ্ট করুন
প্রচুর সংখ্যক পুনরাবৃত্তি এবং ভার্বোস আউটপুট অক্ষম সহ উদাহরণ:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}এই পরীক্ষার ফলাফল নিম্নলিখিত দেখায়:
-
"pair":3 - একটি ক্লায়েন্ট এবং সার্ভার জোড়া তৈরি করে।
-
"iterations": 5000 - 5000 পুনরাবৃত্তি অন্তর্ভুক্ত.
-
"deadline_us":2500 - সময়সীমা 2500us (2.5ms); অধিকাংশ লেনদেন এই মান পূরণের প্রত্যাশিত.
-
"I": 10000 - একটি একক পরীক্ষার পুনরাবৃত্তিতে দুটি (2) লেনদেন অন্তর্ভুক্ত রয়েছে:
- স্বাভাবিক অগ্রাধিকার দ্বারা একটি লেনদেন (
CFS other) - রিয়েল টাইম অগ্রাধিকার দ্বারা একটি লেনদেন (
RT-fifo)
- স্বাভাবিক অগ্রাধিকার দ্বারা একটি লেনদেন (
-
"S": 9352 - 9352টি লেনদেন একই CPU-তে সিঙ্ক করা হয়।
-
"R": 0.9352 - একই CPU-তে ক্লায়েন্ট এবং সার্ভার একসাথে সিঙ্ক করা অনুপাত নির্দেশ করে।
-
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996} - একটি সাধারণ অগ্রাধিকার কলার দ্বারা জারি করা সমস্ত লেনদেনের জন্য গড় (
avg), সবচেয়ে খারাপ (wst) এবং সেরা (bst) কেস৷ দুটি লেনদেনের সময়সীমাmiss, যার ফলে মিলিত অনুপাত (meetR) 0.9996 হয়। -
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1} -
other_msএর মতো, কিন্তু ক্লায়েন্ট দ্বারাrt_fifoঅগ্রাধিকার দিয়ে জারি করা লেনদেনের জন্য। এটা সম্ভবত (কিন্তু প্রয়োজনীয় নয়) যেfifo_msother_msচেয়ে ভাল ফলাফল রয়েছে, কমavgএবংwstমান এবং উচ্চতরmeetR(ব্যাকগ্রাউন্ডে লোডের সাথে পার্থক্যটি আরও বেশি তাৎপর্যপূর্ণ হতে পারে)।
দ্রষ্টব্য: ব্যাকগ্রাউন্ড লোড থ্রুপুট ফলাফলকে প্রভাবিত করতে পারে এবং লেটেন্সি পরীক্ষায় other_ms টিপল। শুধুমাত্র fifo_ms অনুরূপ ফলাফল দেখাতে পারে যতক্ষণ না ব্যাকগ্রাউন্ড লোডের অগ্রাধিকার RT-fifo চেয়ে কম থাকে।
জোড়া মান নির্দিষ্ট করুন
প্রতিটি ক্লায়েন্ট প্রক্রিয়া ক্লায়েন্টের জন্য নিবেদিত একটি সার্ভার প্রক্রিয়ার সাথে যুক্ত করা হয় এবং প্রতিটি জোড়া স্বাধীনভাবে যেকোনো CPU-তে নির্ধারিত হতে পারে। যাইহোক, যতক্ষণ পর্যন্ত SYNC পতাকা honor থাকে ততক্ষণ লেনদেনের সময় CPU মাইগ্রেশন হওয়া উচিত নয়।
সিস্টেম ওভারলোড করা হয় না নিশ্চিত করুন! একটি ওভারলোডেড সিস্টেমে উচ্চ লেটেন্সি প্রত্যাশিত হলেও, একটি ওভারলোডেড সিস্টেমের জন্য পরীক্ষার ফলাফল দরকারী তথ্য প্রদান করে না। উচ্চ চাপ সহ একটি সিস্টেম পরীক্ষা করতে, -pair #cpu-1 (বা -pair #cpu সতর্কতার সাথে) ব্যবহার করুন। -pair n সাথে n > #cpu ব্যবহার করে পরীক্ষা করা হলে সিস্টেম ওভারলোড হয় এবং অকেজো তথ্য উৎপন্ন হয়।
সময়সীমার মান উল্লেখ করুন
ব্যাপক ব্যবহারকারীর দৃশ্যকল্প পরীক্ষার পর (একটি যোগ্য পণ্যে লেটেন্সি পরীক্ষা চালানো), আমরা নির্ধারণ করেছি যে 2.5ms হল পূরণের সময়সীমা। উচ্চতর প্রয়োজনীয়তা সহ নতুন অ্যাপ্লিকেশনগুলির জন্য (যেমন 1000 ফটো/সেকেন্ড), এই সময়সীমার মান পরিবর্তন হবে।
ভার্বোস আউটপুট নির্দিষ্ট করুন
-v বিকল্পটি ব্যবহার করে ভার্বোস আউটপুট দেখায়। উদাহরণ:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- পরিষেবা থ্রেডটি একটি
SCHED_OTHERঅগ্রাধিকারের সাথে তৈরি করা হয়েছে এবংpid 8674সহCPU:1এ চলে। - প্রথম লেনদেন শুরু হয় একজন
fifo-callerদ্বারা। এই লেনদেনটি পরিষেবা দেওয়ার জন্য, hwbinder সার্ভারের অগ্রাধিকার (pid: 8674 tid: 8676) 99-এ আপগ্রেড করে এবং এটিকে একটি ক্ষণস্থায়ী শিডিউলিং ক্লাস (এভাবে মুদ্রিত???) দিয়ে চিহ্নিত করে। শিডিউলকারী তারপরে সার্ভার প্রক্রিয়াটিকেCPU:0তে রাখে এবং এটিকে তার ক্লায়েন্টের সাথে একই CPU এর সাথে সিঙ্ক করে। - দ্বিতীয় লেনদেন কলারের একটি
SCHED_OTHERঅগ্রাধিকার রয়েছে৷ সার্ভার নিজেকে ডাউনগ্রেড করে এবং কলকারীকেSCHED_OTHERঅগ্রাধিকার দিয়ে পরিষেবা দেয়৷
ডিবাগিংয়ের জন্য ট্রেস ব্যবহার করুন
আপনি লেটেন্সি সমস্যা ডিবাগ করতে -trace বিকল্পটি নির্দিষ্ট করতে পারেন। যখন ব্যবহার করা হয়, যখন খারাপ লেটেন্সি শনাক্ত হয় তখন লেটেন্সি পরীক্ষা ট্রেসলগ রেকর্ডিং বন্ধ করে দেয়। উদাহরণ:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
নিম্নলিখিত উপাদানগুলি বিলম্বকে প্রভাবিত করতে পারে:
- অ্যান্ড্রয়েড বিল্ড মোড । Eng মোড সাধারণত userdebug মোডের চেয়ে ধীর হয়।
- ফ্রেমওয়ার্ক ফ্রেমওয়ার্ক পরিষেবা বাইন্ডারে কনফিগার করতে
ioctlব্যবহার করে কিভাবে? - বাইন্ডার ড্রাইভার । ড্রাইভার কি সূক্ষ্ম দানাদার লকিং সমর্থন করে? এটা কি সব কর্মক্ষমতা বাঁক প্যাচ ধারণ করে?
- কার্নেল সংস্করণ । কার্নেলের রিয়েল টাইম ক্ষমতা যত ভাল, ফলাফল তত ভাল।
- কার্নেল কনফিগারেশন । কার্নেল কনফিগারেশনে কি
DEBUGকনফিগার রয়েছে যেমনDEBUG_PREEMPTএবংDEBUG_SPIN_LOCK? - কার্নেল সময়সূচী । কার্নেলের কি একটি শক্তি-সচেতন সময়সূচী (EAS) বা ভিন্নধর্মী মাল্টি-প্রসেসিং (HMP) শিডিউলার আছে? কোন কার্নেল ড্রাইভার (
cpu-freqড্রাইভার,cpu-idleড্রাইভার,cpu-hotplug, ইত্যাদি) কি শিডিউলারকে প্রভাবিত করে?