
systrace — это основной инструмент для анализа производительности устройств Android. Однако на самом деле это оболочка вокруг других инструментов. Это оболочка на стороне хоста вокруг atrace , исполняемого файла на стороне устройства, который управляет трассировкой пользовательского пространства и настраивает ftrace , а также основного механизма трассировки в ядре Linux. systrace использует atrace для включения трассировки, затем считывает буфер ftrace и оборачивает все это в автономный просмотрщик HTML. (Хотя более новые ядра поддерживают Linux Enhanced Berkeley Packet Filter (eBPF), эта страница относится к ядру 3.18 (без eFPF), поскольку именно оно использовалось в Pixel или Pixel XL.)
systrace принадлежит командам Google Android и Google Chrome и имеет открытый исходный код как часть проекта Catapult . Помимо systrace, Catapult включает в себя другие полезные утилиты. Например, ftrace имеет больше функций, чем могут быть напрямую включены systrace или atrace, и содержит некоторые расширенные функции, которые имеют решающее значение для отладки проблем производительности. (Для этих функций требуется доступ root и часто новое ядро.)
Запустить systrace
При отладке джиттера на Pixel или Pixel XL начните со следующей команды:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
В сочетании с дополнительными точками трассировки, необходимыми для активности графического процессора и конвейера отображения, это позволяет вам трассировать от пользовательского ввода до кадра, отображаемого на экране. Установите большой размер буфера, чтобы избежать потери событий (поскольку без большого буфера некоторые процессоры не содержат никаких событий после некоторой точки трассировки).
При работе с systrace помните, что каждое событие инициируется каким-либо событием на ЦП .
Поскольку systrace построен на основе ftrace, а ftrace работает на ЦП, что-то на ЦП должно записывать буфер ftrace, который регистрирует изменения оборудования. Это означает, что если вам интересно, почему изменился статус display fence, вы можете увидеть, что работало на ЦП в точной точке его перехода (что-то работающее на ЦП вызвало это изменение в журнале). Эта концепция является основой анализа производительности с использованием systrace.
Пример: рабочая рамка
В этом примере описывается systrace для обычного конвейера пользовательского интерфейса. Чтобы следовать примеру, загрузите zip-файл трассировок (который также включает другие трассировки, упомянутые в этом разделе), распакуйте файл и откройте файл systrace_tutorial.html в своем браузере.
Для постоянной периодической рабочей нагрузки, такой как TouchLatency, конвейер пользовательского интерфейса следует следующей последовательности:
- EventThread в SurfaceFlinger пробуждает поток пользовательского интерфейса приложения, сигнализируя о том, что пришло время отрисовать новый кадр.
- Приложение рендерит кадр в потоке пользовательского интерфейса, RenderThread и задачах HWUI, используя ресурсы CPU и GPU. Это основная часть емкости, затрачиваемая на пользовательский интерфейс.
- Приложение отправляет отрендеренный кадр в SurfaceFlinger с помощью связующего устройства, после чего SurfaceFlinger переходит в спящий режим.
- Второй EventThread в SurfaceFlinger пробуждает SurfaceFlinger для запуска композиции и отображения вывода. Если SurfaceFlinger определяет, что нет работы, которую нужно выполнить, он возвращается в спящий режим.
- SurfaceFlinger обрабатывает композицию с помощью Hardware Composer (HWC) или Hardware Composer 2 (HWC2) или GL. Композиция HWC и HWC2 быстрее и потребляет меньше энергии, но имеет ограничения в зависимости от системы на чипе (SoC). Обычно это занимает около 4–6 мс, но может перекрываться с шагом 2, поскольку приложения Android всегда имеют тройную буферизацию. (Хотя приложения всегда имеют тройную буферизацию, в SurfaceFlinger может быть только один ожидающий кадр, что делает его идентичным двойной буферизации.)
- SurfaceFlinger отправляет окончательный вывод на дисплей с помощью драйвера поставщика и возвращается в спящий режим, ожидая пробуждения EventThread.
Вот пример последовательности кадров, начинающейся с 15409 мс:
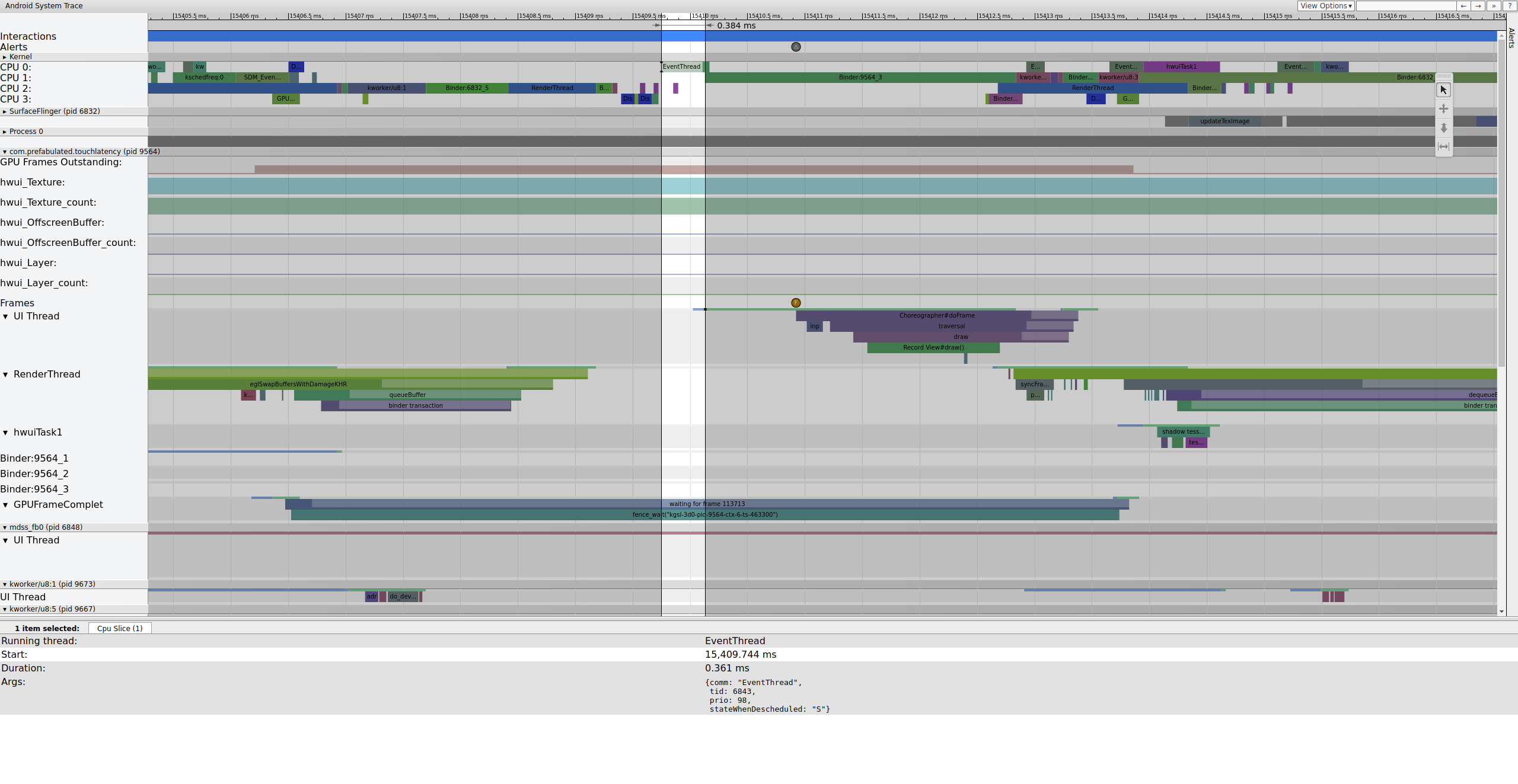
Рисунок 1. Обычный конвейер пользовательского интерфейса, EventThread запущен.
Рисунок 1 — это обычный кадр, окруженный обычными кадрами, поэтому это хорошая отправная точка для понимания того, как работает конвейер пользовательского интерфейса. Строка потока пользовательского интерфейса для TouchLatency включает разные цвета в разное время. Полоски обозначают разные состояния потока:
- Серый. Спит.
- Синий. Готов к запуску (может быть запущен, но планировщик еще не выбрал его для запуска).
- Зеленый. Активно работает (планировщик думает, что работает).
- Красный. Непрерывный сон (обычно сон на блокировке в ядре). Может указывать на нагрузку ввода-вывода. Крайне полезно для отладки проблем производительности.
- Оранжевый. Непрерывный сон из-за нагрузки ввода-вывода.
Чтобы просмотреть причину непрерывного сна (доступную из точки трассировки sched_blocked_reason ), выберите красный сектор непрерывного сна.
Пока EventThread работает, поток пользовательского интерфейса для TouchLatency становится работоспособным. Чтобы увидеть, что его разбудило, щелкните синий раздел.
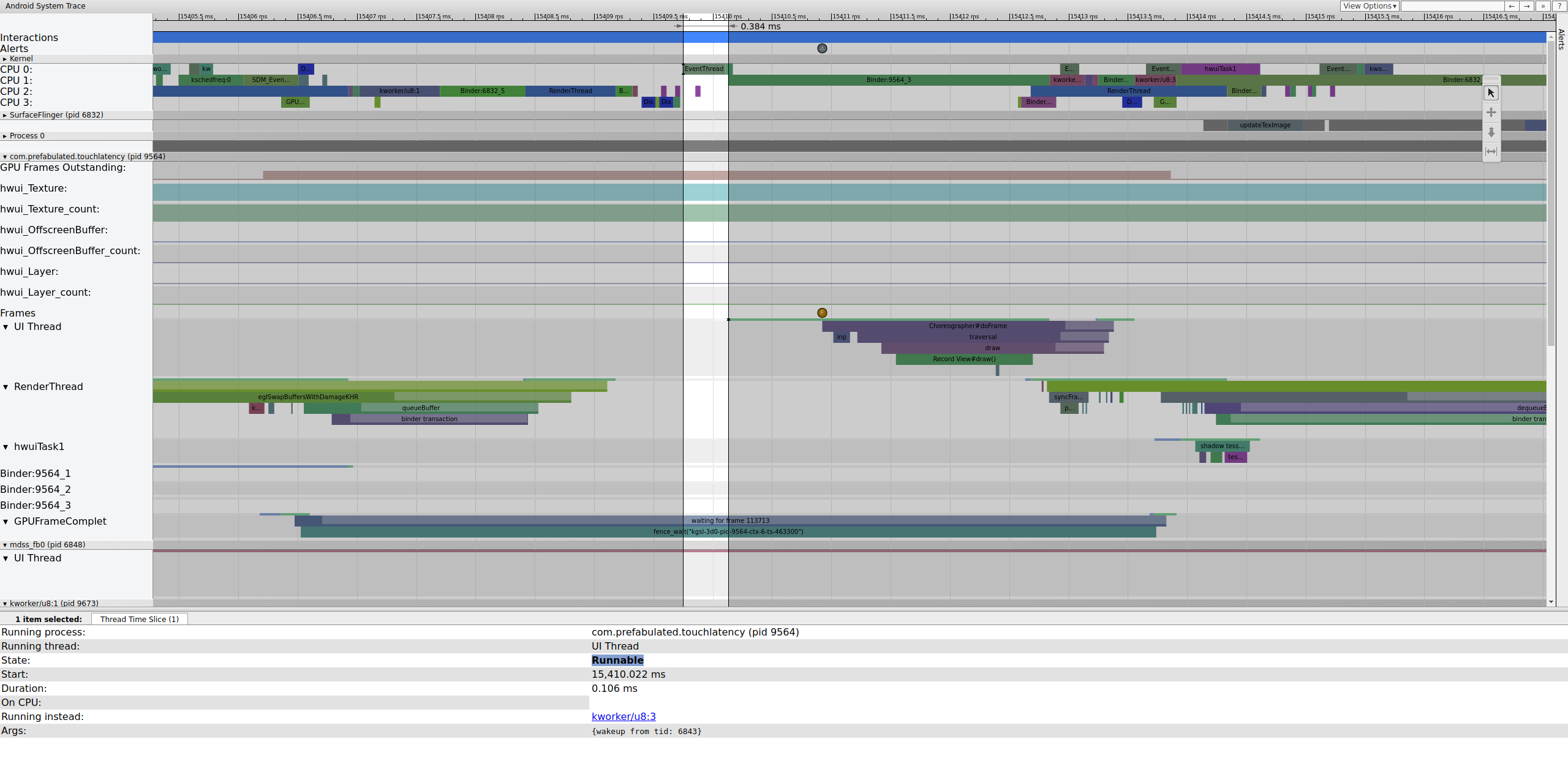
Рисунок 2. Поток пользовательского интерфейса для TouchLatency.
На рисунке 2 показано, что поток пользовательского интерфейса TouchLatency был разбужен tid 6843, что соответствует EventThread. Поток пользовательского интерфейса просыпается, визуализирует кадр и ставит его в очередь для использования SurfaceFlinger.
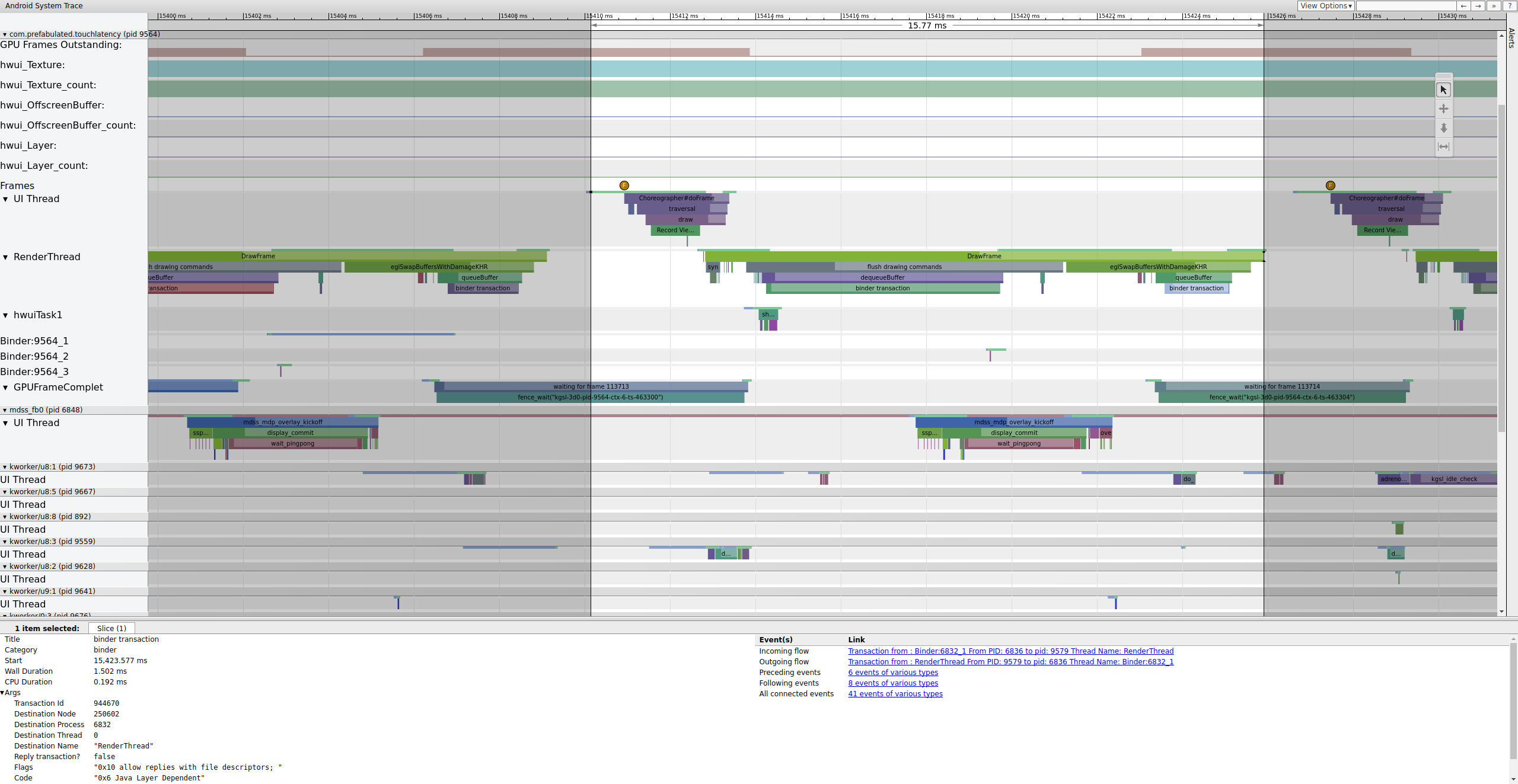
Рисунок 3. Поток пользовательского интерфейса пробуждается, визуализирует кадр и ставит его в очередь для использования SurfaceFlinger.
Если тег binder_driver включен в трассировке, вы можете выбрать транзакцию binder, чтобы просмотреть информацию обо всех процессах, вовлеченных в эту транзакцию.
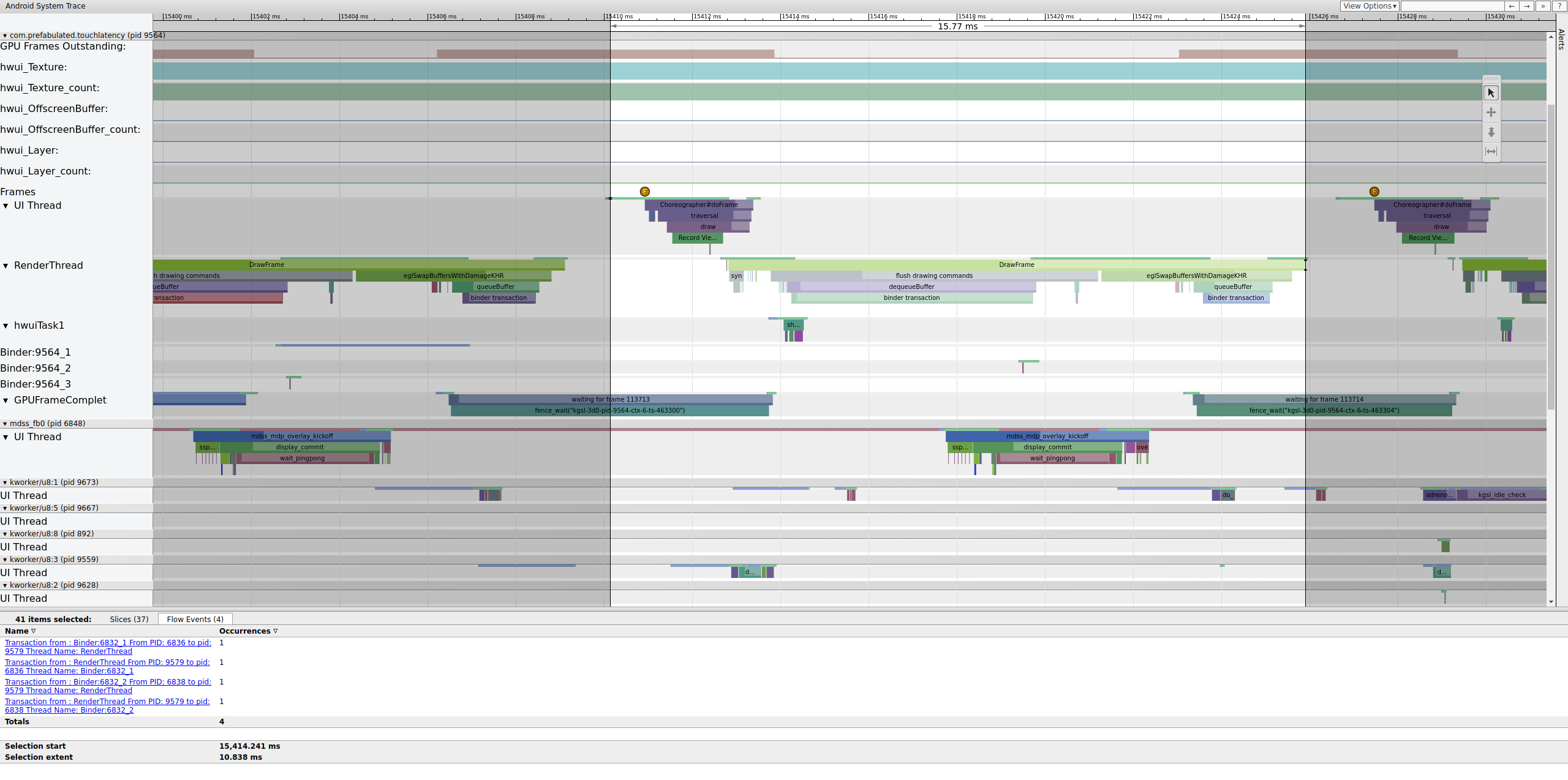
Рисунок 4. Транзакция Binder.
Рисунок 4 показывает, что в 15,423.65 мс Binder:6832_1 в SurfaceFlinger становится работоспособным из-за tid 9579, который является TouchLatency's RenderThread. Вы также можете видеть queueBuffer на обеих сторонах транзакции binder.
Во время queueBuffer на стороне SurfaceFlinger количество ожидающих кадров от TouchLatency увеличивается с 1 до 2.
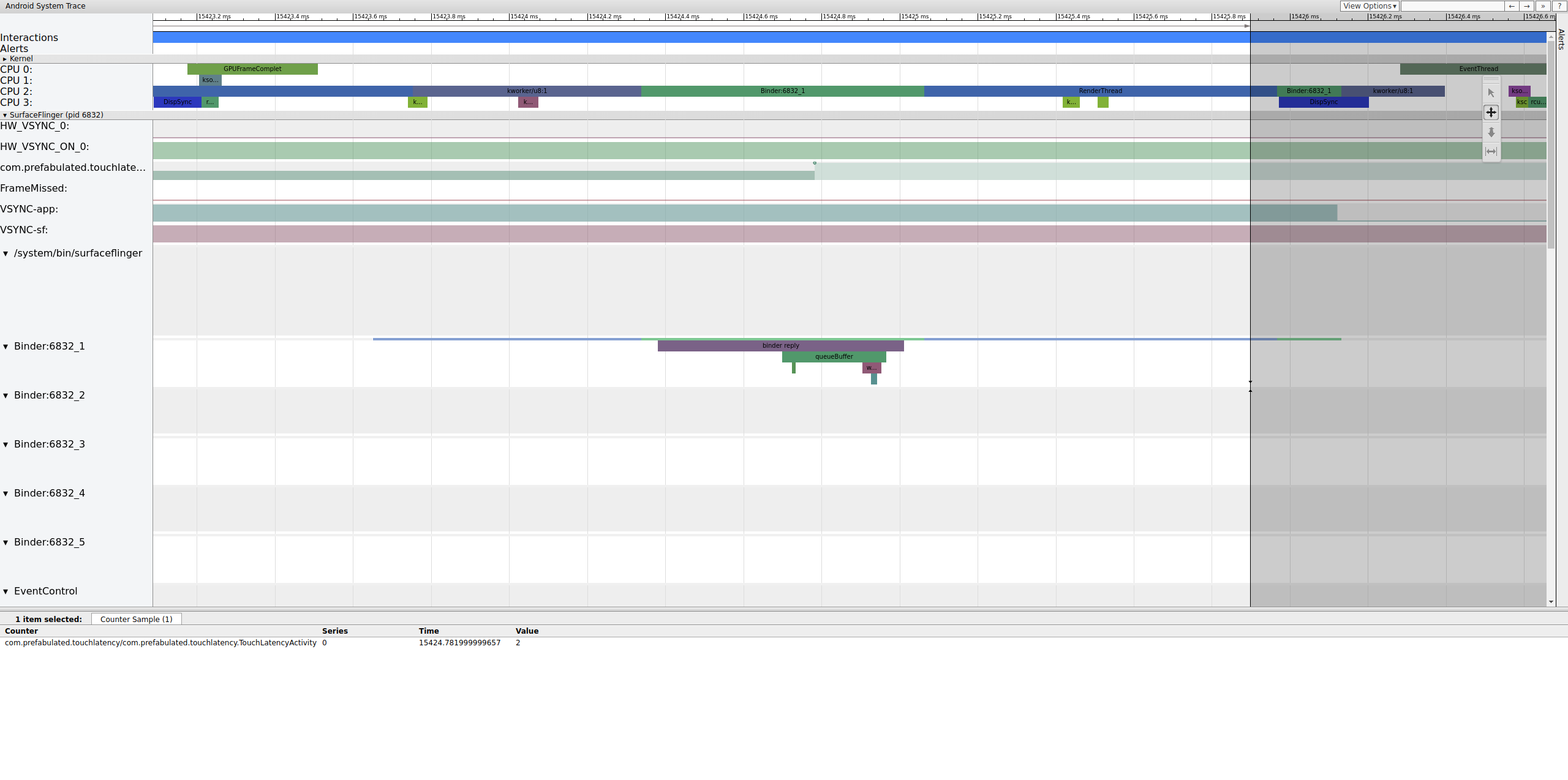
Рисунок 5. Ожидающие кадры переходят от 1 к 2.
Рисунок 5 показывает тройную буферизацию, где есть два завершенных кадра, и приложение собирается начать рендеринг третьего. Это происходит потому, что мы уже потеряли несколько кадров, поэтому приложение сохраняет два ожидающих кадра вместо одного, чтобы попытаться избежать дальнейших потерь кадров.
Вскоре после этого основной поток SurfaceFlinger пробуждается вторым EventThread, чтобы он мог вывести на дисплей старый ожидающий кадр:
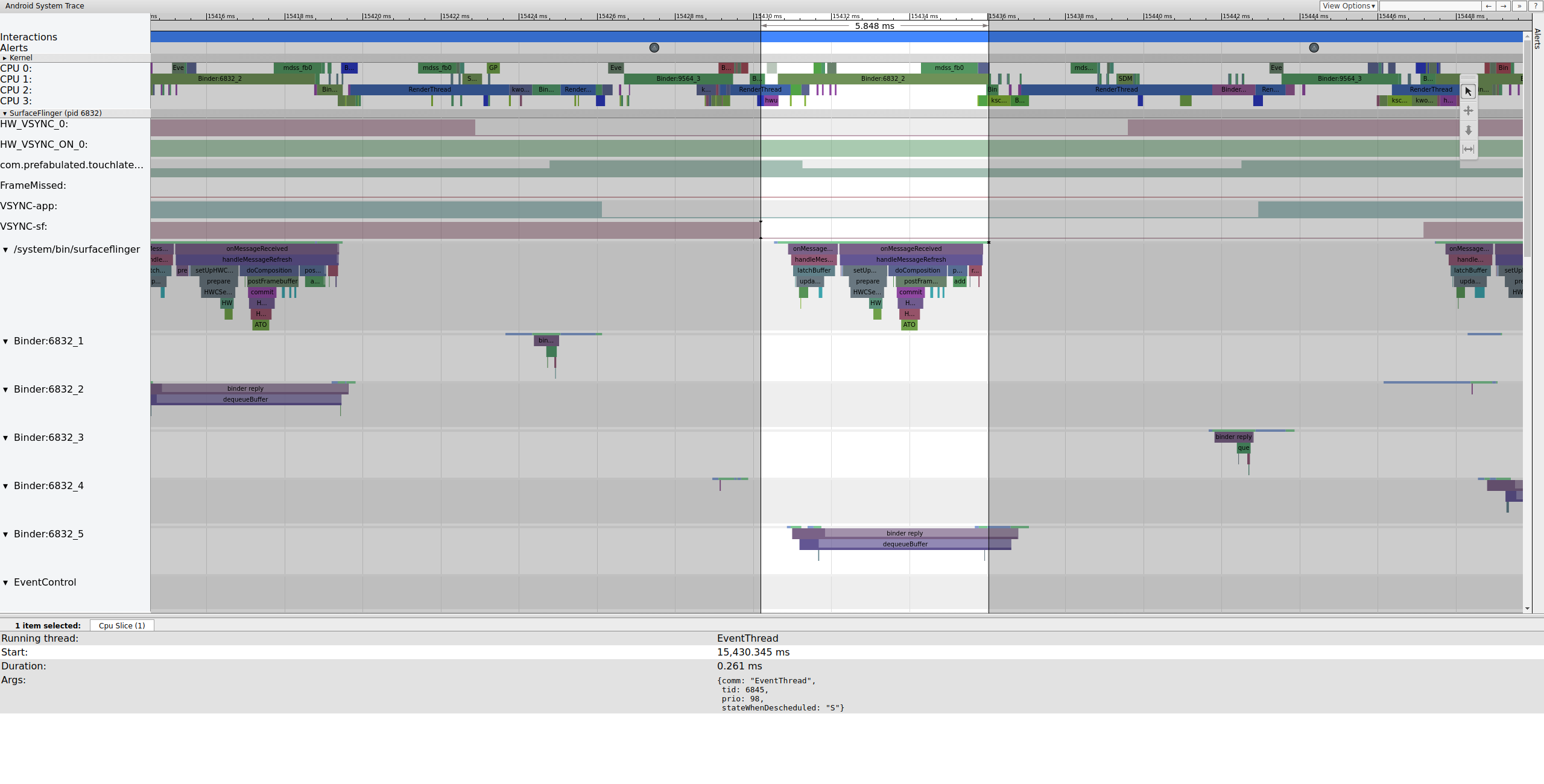
Рисунок 6. Основной поток SurfaceFlinger пробуждается вторым EventThread.
SurfaceFlinger сначала фиксирует старый ожидающий буфер, в результате чего количество ожидающих буферов уменьшается с 2 до 1:
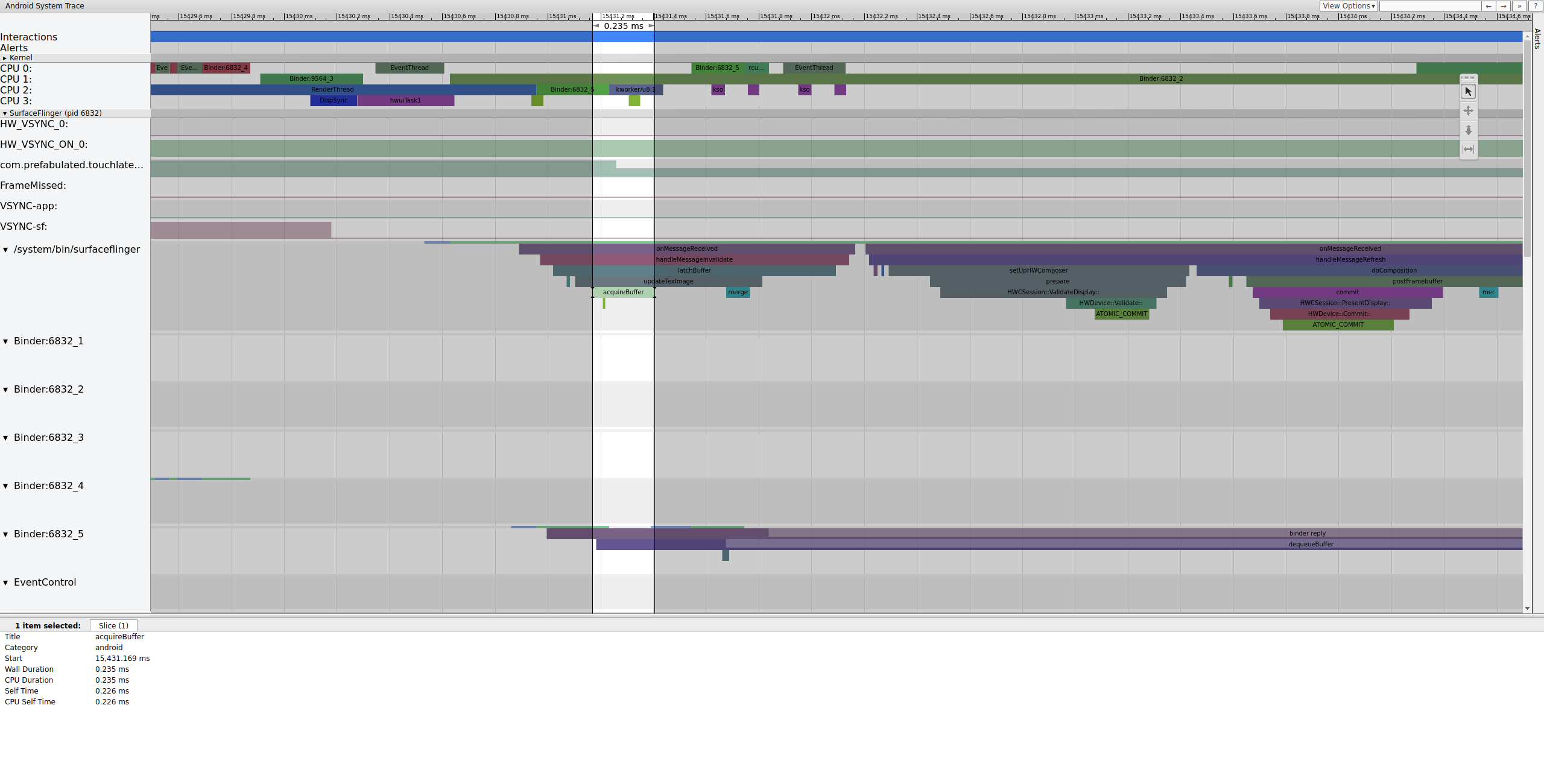
Рисунок 7. SurfaceFlinger сначала прикрепляется к старому ожидающему буферу.
После фиксации буфера SurfaceFlinger настраивает композицию и отправляет финальный кадр на дисплей. (Некоторые из этих разделов включены как часть точки трассировки mdss , поэтому они могут быть не включены в вашу SoC.)
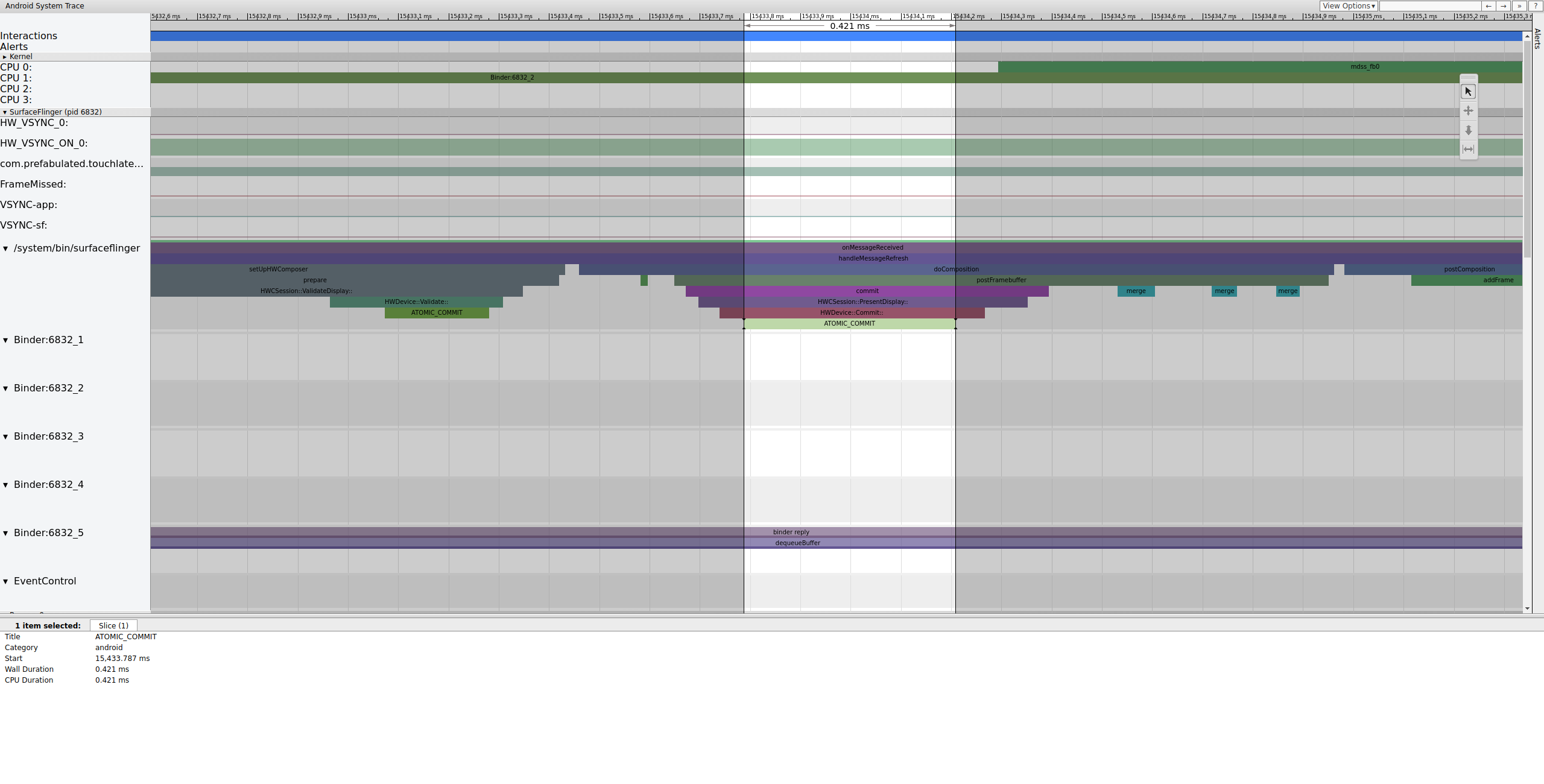
Рисунок 8. SurfaceFlinger настраивает композицию и отправляет финальный кадр.
Далее mdss_fb0 просыпается на CPU 0. mdss_fb0 — это поток ядра конвейера дисплея для вывода отрендеренного кадра на дисплей. Обратите внимание, что mdss_fb0 — это его собственная строка в трассировке (прокрутите вниз, чтобы увидеть):
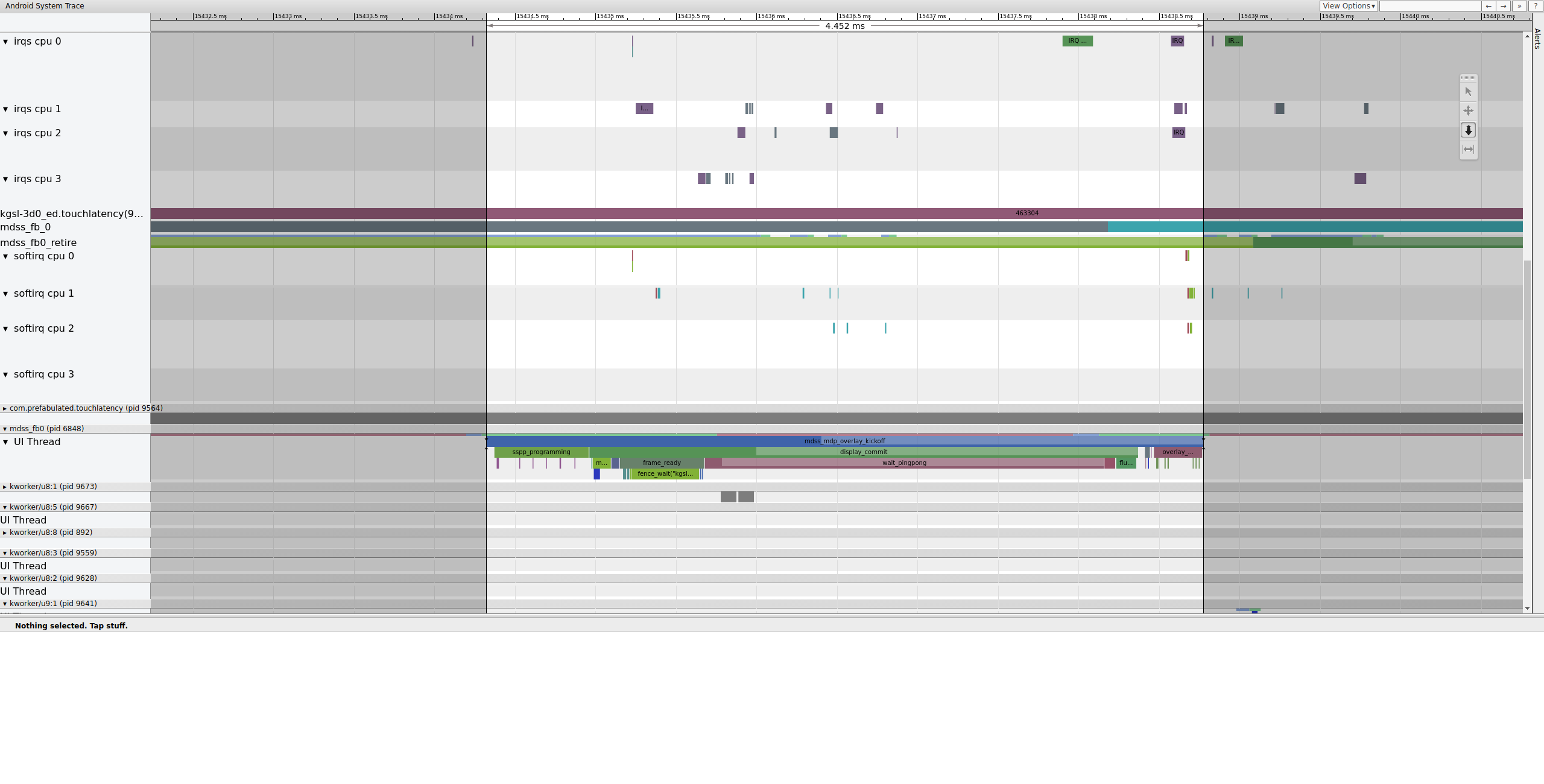
Рисунок 9. mdss_fb0 пробуждается на CPU 0.
mdss_fb0 просыпается, работает недолго, переходит в непрерываемый сон, затем снова просыпается.
Пример: Нерабочий кадр
В этом примере описывается systrace, используемая для отладки дрожания Pixel или Pixel XL. Чтобы следовать примеру, загрузите zip-файл трассировок (который включает другие трассировки, упомянутые в этом разделе), распакуйте файл и откройте файл systrace_tutorial.html в своем браузере.
Открыв systrace, вы увидите что-то вроде следующего рисунка:

Рисунок 10. TouchLatency работает на Pixel XL с большинством включенных параметров.
На рисунке 10 включено большинство параметров, включая точки трассировки mdss и kgsl .
При поиске зависаний проверьте строку FrameMissed в SurfaceFlinger. FrameMissed — это улучшение качества жизни, предоставляемое HWC2. При просмотре systrace для других устройств строка FrameMissed может отсутствовать, если устройство не использует HWC2. В любом случае FrameMissed коррелирует с тем, что SurfaceFlinger пропускает одну из своих обычных сред выполнения и неизменным счетчиком буферов ожидания для приложения ( com.prefabulated.touchlatency ) при VSync.

Рисунок 11. Корреляция FrameMissed с SurfaceFlinger.
На рисунке 11 показан пропущенный кадр на 15598,29 мс. SurfaceFlinger ненадолго проснулся на интервале VSync и снова заснул, не выполнив никакой работы, что означает, что SurfaceFlinger решил, что не стоит снова пытаться отправить кадр на дисплей.
Чтобы понять, почему конвейер сломался для этого кадра, сначала просмотрите пример рабочего кадра выше, чтобы увидеть, как обычный конвейер пользовательского интерфейса выглядит в systrace. Когда будете готовы, вернитесь к пропущенному кадру и двигайтесь в обратном направлении. Обратите внимание, что SurfaceFlinger просыпается и немедленно засыпает. При просмотре количества ожидающих кадров из TouchLatency есть два кадра (хорошая подсказка, помогающая определить, что происходит).
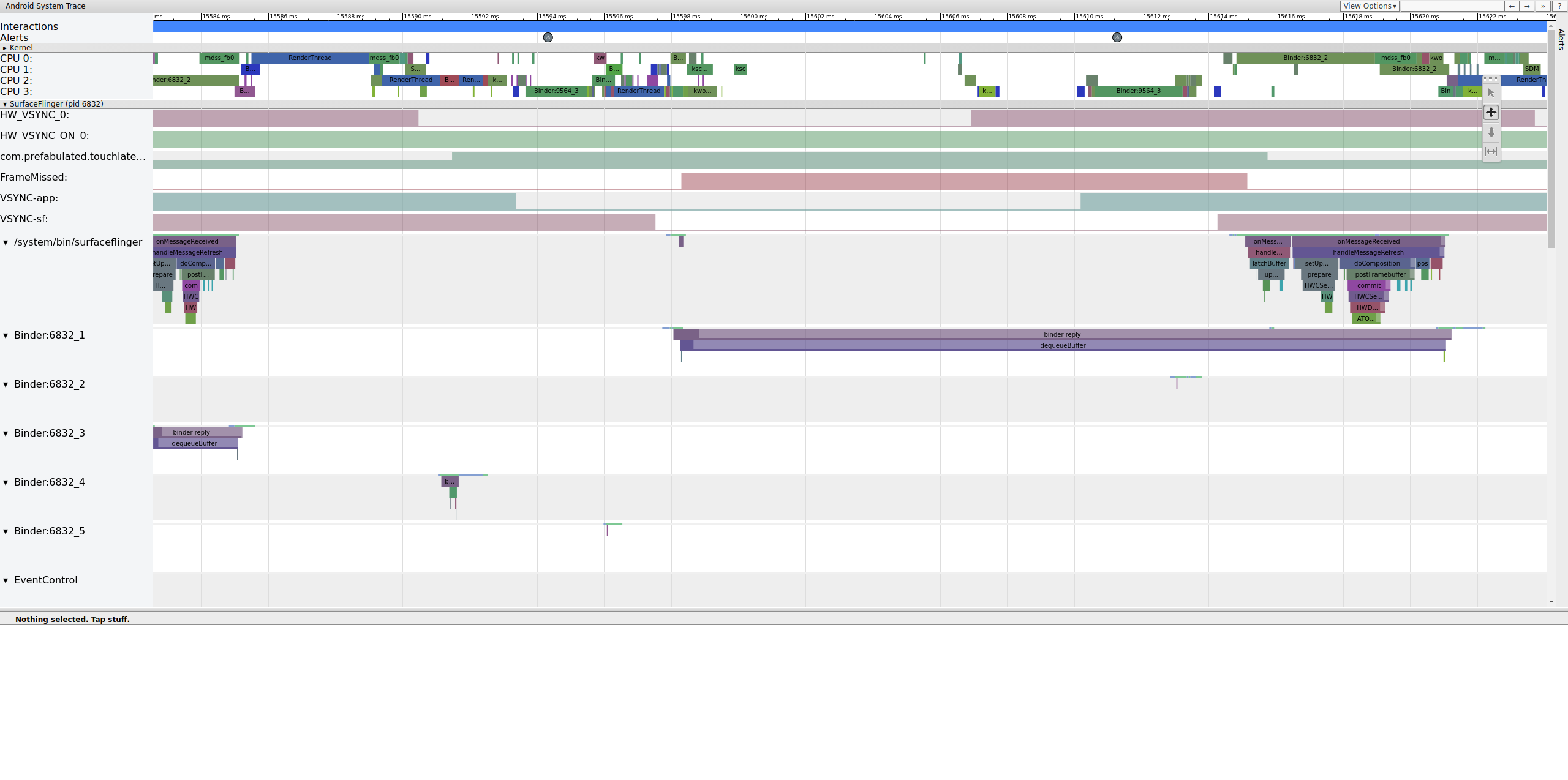
Рисунок 12. SurfaceFlinger просыпается и тут же засыпает.
Поскольку в SurfaceFlinger есть кадры, это не проблема приложения. Кроме того, SurfaceFlinger просыпается в правильное время, так что это не проблема SurfaceFlinger. Если SurfaceFlinger и приложение выглядят нормально, это, вероятно, проблема с драйвером.
Поскольку mdss и sync tracepoints включены, вы можете получить информацию о границах (общих для драйвера дисплея и SurfaceFlinger), которые управляют отправкой кадров на дисплей. Эти границы перечислены в mdss_fb0_retire , что обозначает, когда кадр находится на дисплее. Эти границы предоставляются как часть категории sync trace. Какие границы соответствуют определенным событиям в SurfaceFlinger, зависит от вашего SOC и стека драйверов, поэтому обратитесь к поставщику SOC, чтобы понять значение категорий границ в ваших трассировках.
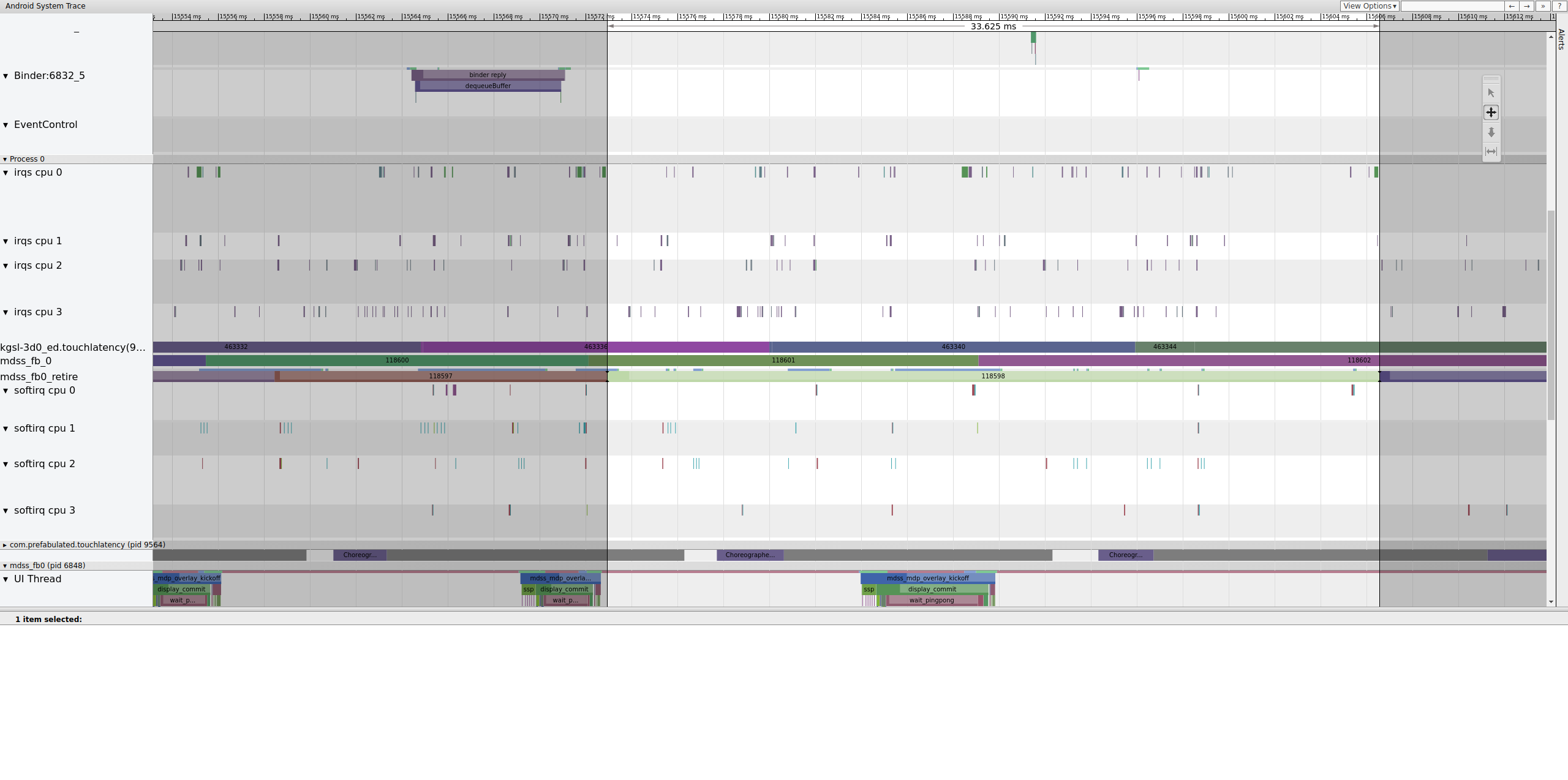
Рисунок 13. Заборы mdss_fb0_retire.
На рисунке 13 показан кадр, который отображался в течение 33 мс, а не 16,7 мс, как ожидалось. На полпути через этот срез этот кадр должен был быть заменен новым, но этого не произошло. Просмотрите предыдущий кадр и поищите что-нибудь.
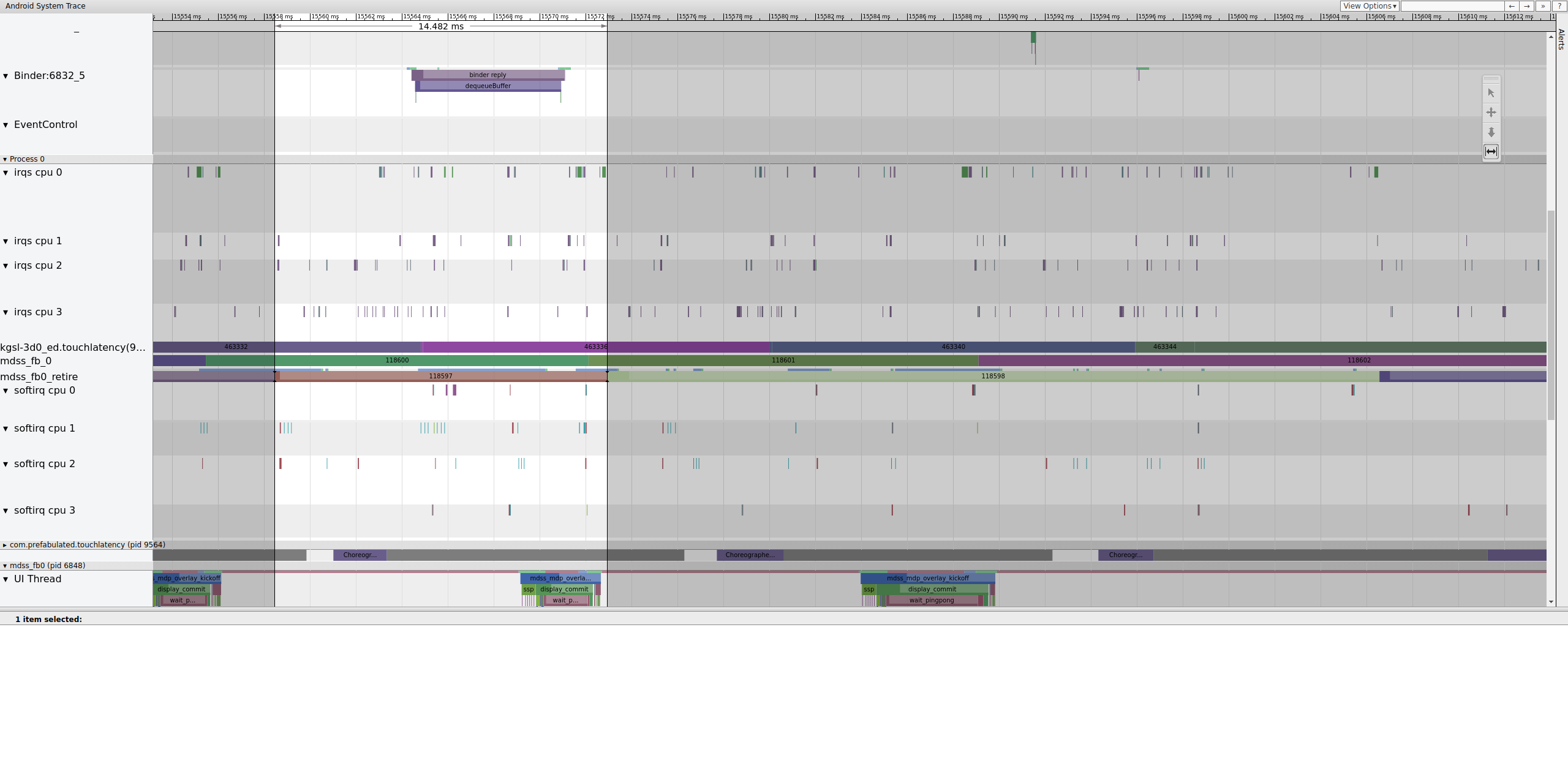
Рисунок 14. Кадр, предшествующий разрушенному кадру.
На рисунке 14 показан кадр длительностью 14,482 мс. Сломанный двухкадровый сегмент составил 33,6 мс, что примерно соответствует ожидаемому значению для двух кадров (рендеринг на частоте 60 Гц, 16,7 мс на кадр, что близко). Но 14,482 мс не близко к 16,7 мс, что говорит о том, что что-то не так с конвейером дисплея.
Выясните, где именно заканчивается этот забор, чтобы определить, кто его контролирует:
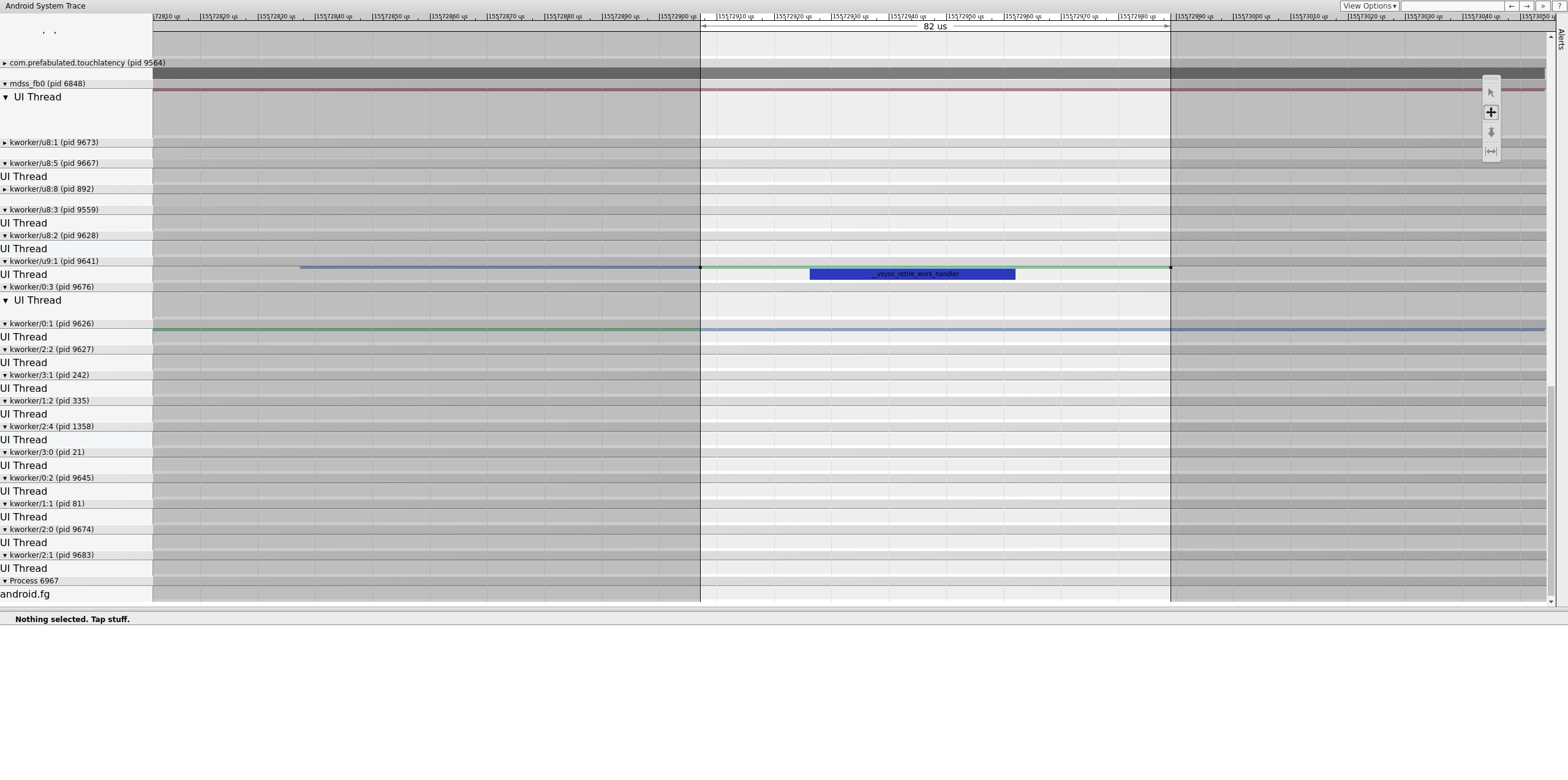
Рисунок 15. Осмотрите конец забора.
Очередь задач содержит __vsync_retire_work_handler , который запускается при изменении ограждения. Просматривая исходный код ядра, можно увидеть, что это часть драйвера дисплея. Похоже, он находится на критическом пути для конвейера дисплея, поэтому он должен работать как можно быстрее. Он может работать около 70 мкс (не слишком большая задержка планирования), но это очередь задач и может быть запланирован неточно.
Проверьте предыдущий кадр, чтобы определить, повлияло ли это; иногда со временем дрожание может накапливаться и в конечном итоге привести к пропущенному сроку:
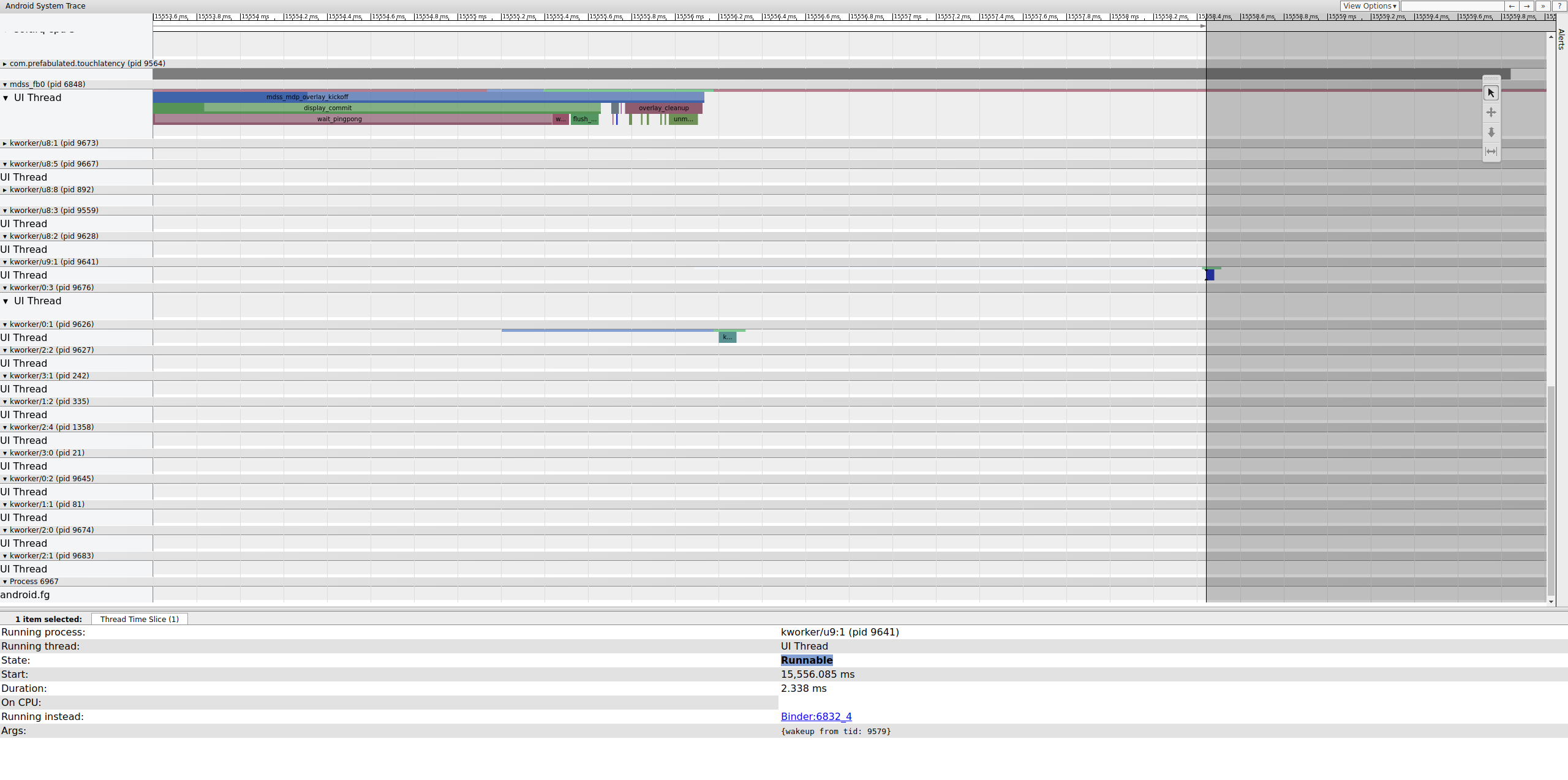
Рисунок 16. Предыдущий кадр.
Строка runnable на kworker не видна, потому что средство просмотра делает ее белой при выборе, но статистика говорит сама за себя: 2,3 мс задержки планировщика для части критического пути конвейера отображения — это плохо . Прежде чем продолжить, исправьте задержку, переместив эту часть критического пути конвейера отображения из рабочей очереди (которая работает как поток CFS SCHED_OTHER ) в выделенный поток kthread SCHED_FIFO . Эта функция требует гарантий синхронизации, которые рабочие очереди не могут (и не предназначены) предоставить.
Неясно, что является причиной рывка. За исключением случаев, которые легко диагностировать, таких как конфликт блокировки ядра, приводящий к засыпанию критически важных для отображения потоков, трассировки обычно не указывают на проблему. Этот джиттер мог быть причиной потери кадра. Время забора должно быть 16,7 мс, но оно совсем не близко к этому в кадрах, ведущих к потерянному кадру. Учитывая, насколько тесно связан конвейер отображения, возможно, что джиттер вокруг таймингов забора привел к потере кадра.
В этом примере решение включает преобразование __vsync_retire_work_handler из workqueue в выделенный kthread. Это приводит к заметным улучшениям джиттера и уменьшению рывков в тесте с прыгающим мячом. Последующие трассировки показывают время забора, которое колеблется очень близко к 16,7 мс.