
Android bietet eine Referenzimplementierung aller Komponenten, die zum Implementieren des Android Virtualization Framework erforderlich sind. Derzeit ist diese Implementierung auf ARM64 beschränkt. Auf dieser Seite wird die Framework-Architektur erläutert.
Hintergrund
Die ARM-Architektur ermöglicht bis zu vier Ausnahmestufen, wobei Ausnahmestufe 0 (EL0) die am wenigsten privilegierte und Ausnahmestufe 3 (EL3) die am meisten privilegierte ist. Der größte Teil der Android-Codebasis (alle Userspace-Komponenten) wird auf EL0 ausgeführt. Der Rest von dem, was allgemein als „Android“ bezeichnet wird, ist der Linux-Kernel, der auf EL1 ausgeführt wird.
Die EL2-Ebene ermöglicht die Einführung eines Hypervisors, mit dem Speicher und Geräte auf EL1/EL0 in einzelnen pVMs isoliert werden können. Dabei werden strenge Vertraulichkeits- und Integritätsgarantien geboten.
Hypervisor
Die geschützte Kernel-basierte virtuelle Maschine (protected Kernel-based Virtual Machine, pKVM) basiert auf dem Linux-KVM-Hypervisor, der um die Möglichkeit erweitert wurde, den Zugriff auf die Nutzlasten einzuschränken, die in Gast-VMs ausgeführt werden, die zum Zeitpunkt der Erstellung als „geschützt“ gekennzeichnet sind.
KVM/arm64 unterstützt je nach Verfügbarkeit bestimmter CPU-Funktionen verschiedene Ausführungsmodi, insbesondere die Virtualization Host Extensions (VHE) (ARMv8.1 und höher). In einem dieser Modi, der allgemein als Nicht-VHE-Modus bezeichnet wird, wird der Hypervisor-Code während des Bootvorgangs aus dem Kernel-Image herausgelöst und auf EL2 installiert, während der Kernel selbst auf EL1 ausgeführt wird. Obwohl die EL2-Komponente von KVM Teil der Linux-Codebasis ist, ist sie eine kleine Komponente, die für den Wechsel zwischen mehreren EL1s zuständig ist. Die Hypervisor-Komponente wird mit Linux kompiliert, befindet sich aber in einem separaten, dedizierten Speicherbereich des vmlinux-Images. pKVM nutzt dieses Design, indem der Hypervisor-Code um neue Funktionen erweitert wird, die es ermöglichen, Einschränkungen für den Android-Host-Kernel und den Nutzerbereich festzulegen und den Host-Zugriff auf den Gast-Arbeitsspeicher und den Hypervisor zu beschränken.
pKVM-Anbietermodule
Ein pKVM-Anbietermodul ist ein hardwarespezifisches Modul, das gerätespezifische Funktionen wie IOMMU-Treiber (Input-Output Memory Management Unit) enthält. Mit diesen Modulen können Sie Sicherheitsfunktionen, für die der Zugriff auf Ausnahmeebene 2 (EL2) erforderlich ist, auf pKVM portieren.
Informationen zum Implementieren und Laden eines pKVM-Anbietermoduls finden Sie unter pKVM-Anbietermodul implementieren.
Bootvorgang
Die folgende Abbildung zeigt den pKVM-Bootvorgang:
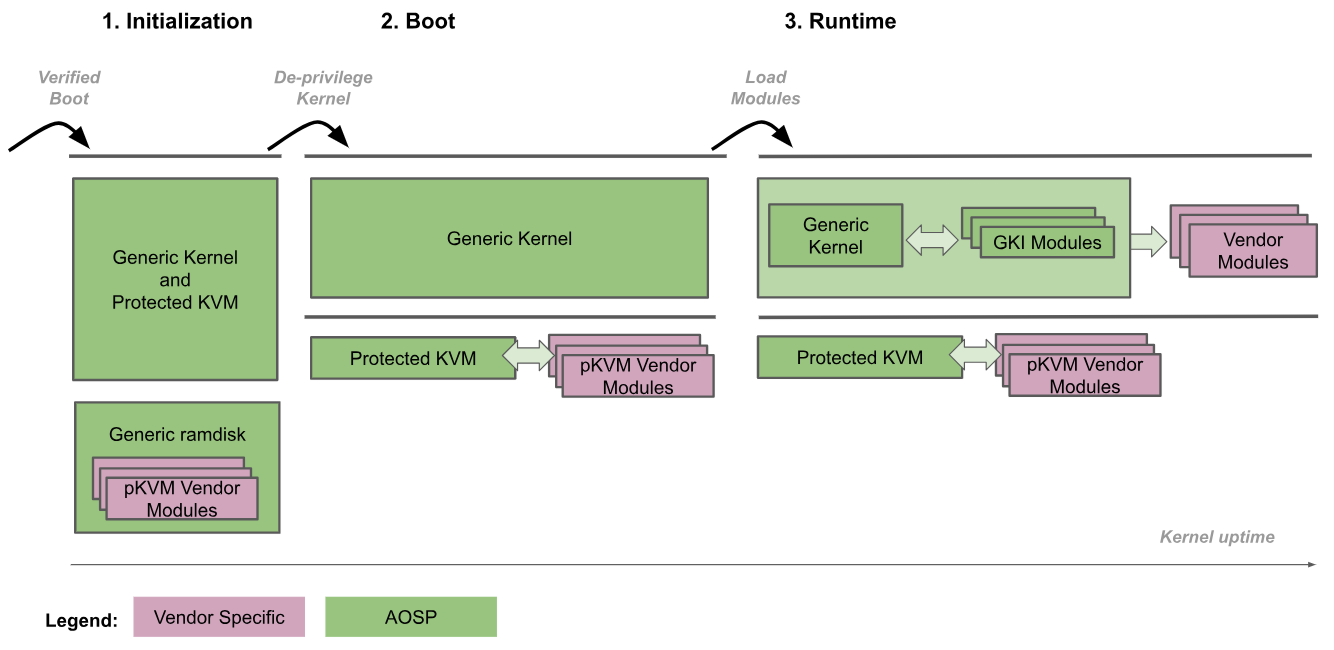
- Initialisierung:Der Bootloader ruft den generischen Kernel auf EL2 auf. Vertrauenswürdiger Kernelcode auf EL2- und EL1-Ebene initialisiert dann pKVM und seine Module. In dieser Phase wird EL1 von EL2 als vertrauenswürdig eingestuft, sodass kein nicht vertrauenswürdiger Code ausgeführt wird.
- Kernel ohne Berechtigungen: Der generische Kernel erkennt, dass er auf EL2 ausgeführt wird, und reduziert seine Berechtigungen auf EL1. pKVM und seine Module werden weiterhin auf EL2 ausgeführt.
- Laufzeit: Der generische Kernel wird normal hochgefahren und lädt alle erforderlichen Gerätetreiber, bis der Userspace erreicht ist. Zu diesem Zeitpunkt ist pKVM vorhanden und verarbeitet die Seitentabellen der zweiten Phase.
Beim Bootvorgang wird dem Bootloader vertraut, dass er die Integrität des Kernel-Images für die Initialisierungsphase überprüft und aufrechterhält. Nachdem die Berechtigungen des Kernels eingeschränkt wurden, wird er vom Hypervisor nicht mehr als vertrauenswürdig eingestuft. Der Hypervisor ist dann dafür verantwortlich, sich selbst zu schützen, auch wenn der Kernel manipuliert wurde.
Da sich der Android-Kernel und der Hypervisor im selben binären Image befinden, können sie sehr eng miteinander kommunizieren. Diese enge Kopplung garantiert atomare Updates der beiden Komponenten, wodurch die Notwendigkeit entfällt, die Schnittstelle zwischen ihnen stabil zu halten. Außerdem bietet sie viel Flexibilität, ohne die langfristige Wartbarkeit zu beeinträchtigen. Die enge Kopplung ermöglicht auch Leistungsoptimierungen, wenn beide Komponenten zusammenarbeiten können, ohne die vom Hypervisor bereitgestellten Sicherheitsgarantien zu beeinträchtigen.
Außerdem ermöglicht die Einführung von GKI im Android-Ökosystem automatisch, dass der pKVM-Hypervisor auf Android-Geräten im selben Binärformat wie der Kernel bereitgestellt wird.
Schutz des CPU-Arbeitsspeicherzugriffs
Die Arm-Architektur sieht eine Memory Management Unit (MMU) vor, die in zwei unabhängige Phasen unterteilt ist. Beide können verwendet werden, um die Adressübersetzung und die Zugriffssteuerung für verschiedene Speicherbereiche zu implementieren. Die MMU der ersten Stufe wird von EL1 gesteuert und ermöglicht eine erste Ebene der Adressübersetzung. Die MMU der ersten Stufe wird von Linux verwendet, um den virtuellen Adressraum zu verwalten, der jedem Userspace-Prozess und dem eigenen virtuellen Adressraum zur Verfügung gestellt wird.
Die MMU der zweiten Phase wird von EL2 gesteuert und ermöglicht die Anwendung einer zweiten Adressübersetzung auf die Ausgabeadresse der MMU der ersten Phase, was zu einer physischen Adresse (Physical Address, PA) führt. Die Übersetzung der zweiten Phase kann von Hypervisoren verwendet werden, um Speicherzugriffe von allen Gast-VMs zu steuern und zu übersetzen. Wie in Abbildung 2 dargestellt, wird die Ausgabeadresse der ersten Phase als physische Zwischenadresse (Intermediate Physical Address, IPA) bezeichnet, wenn beide Phasen der Übersetzung aktiviert sind. Hinweis: Die virtuelle Adresse (Virtual Address, VA) wird in eine IPA und dann in eine PA übersetzt.
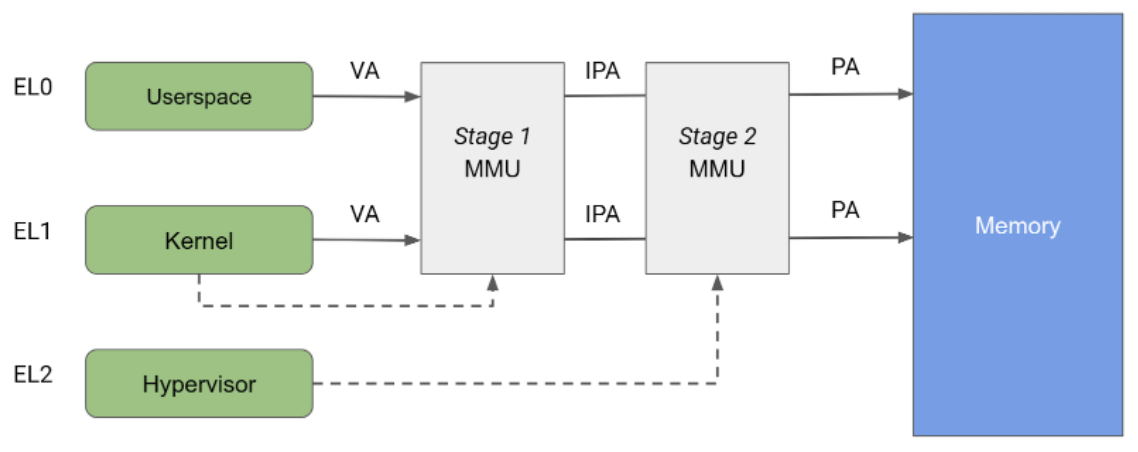
Bisher wurde KVM mit aktivierter Übersetzung der Stufe 2 ausgeführt, wenn Gäste ausgeführt wurden, und mit deaktivierter Übersetzung der Stufe 2, wenn der Host-Linux-Kernel ausgeführt wurde. Diese Architektur ermöglicht es, dass Speicherzugriffe von der Stage 1-MMU des Hosts die Stage 2-MMU durchlaufen. Dadurch ist ein uneingeschränkter Zugriff vom Host auf die Gastspeicherseiten möglich. pKVM ermöglicht dagegen den Schutz der zweiten Stufe auch im Hostkontext und überträgt dem Hypervisor die Aufgabe, Gastspeicherseiten zu schützen, anstatt dem Host.
KVM nutzt die Adressübersetzung in Phase 2 vollständig, um komplexe IPA/PA-Zuordnungen für Gäste zu implementieren. Dadurch wird für Gäste trotz physischer Fragmentierung der Eindruck eines zusammenhängenden Speichers erweckt. Die Verwendung der MMU der Stufe 2 für den Host ist jedoch auf die Zugriffssteuerung beschränkt. Die Hostphase 2 wird identitätszugeordnet, sodass zusammenhängender Speicherplatz im Host-IPA-Bereich im PA-Bereich zusammenhängend ist. Diese Architektur ermöglicht die Verwendung großer Zuordnungen in der Seitentabelle und reduziert so die Belastung des Translation Lookaside Buffer (TLB). Da eine Identitätszuordnung nach PA indexiert werden kann, wird die Host-Phase 2 auch verwendet, um die Seiteninhaberschaft direkt in der Seitentabelle zu erfassen.
Schutz vor Direct Memory Access (DMA)
Wie bereits beschrieben, ist das Aufheben der Zuordnung von Gastseiten vom Linux-Host in den CPU-Seitentabellen ein notwendiger, aber unzureichender Schritt zum Schutz des Gastarbeitsspeichers. pKVM muss auch vor Speicherzugriffen durch DMA-fähige Geräte unter der Kontrolle des Host-Kernels und vor der Möglichkeit eines DMA-Angriffs durch einen schädlichen Host schützen. Damit ein solches Gerät nicht auf den Gastarbeitsspeicher zugreifen kann, ist für pKVM für jedes DMA-fähige Gerät im System eine IOMMU-Hardware (Input-Output Memory Management Unit) erforderlich, wie in Abbildung 3 dargestellt.
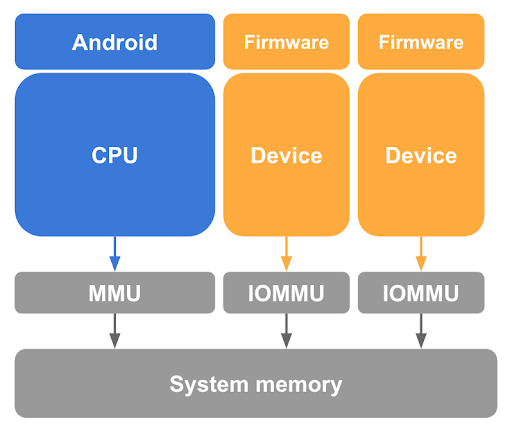
IOMMU-Hardware bietet mindestens die Möglichkeit, Lese-/Schreibzugriff für ein Gerät auf den physischen Speicher auf Seitenebene zu gewähren und zu widerrufen. Diese IOMMU-Hardware schränkt jedoch die Verwendung von Geräten in pVMs ein, da sie von einer identitätszugeordneten Phase 2 ausgeht.
Um die Isolation zwischen virtuellen Maschinen zu gewährleisten, müssen Speichertransaktionen, die im Namen verschiedener Entitäten generiert werden, von der IOMMU unterschieden werden können, damit der entsprechende Satz von Seitentabellen für die Übersetzung verwendet werden kann.
Außerdem ist die Reduzierung der Menge an SoC-spezifischem Code auf EL2 eine wichtige Strategie zur Verkleinerung der gesamten Trusted Computing Base (TCB) von pKVM. Dies widerspricht der Einbeziehung von IOMMU-Treibern in den Hypervisor. Zur Behebung dieses Problems ist der Host auf EL1 für zusätzliche IOMMU-Verwaltungsaufgaben wie Energieverwaltung, Initialisierung und gegebenenfalls Interrupt-Verarbeitung verantwortlich.
Wenn der Host jedoch die Kontrolle über den Gerätestatus hat, werden zusätzliche Anforderungen an die Programmierschnittstelle der IOMMU-Hardware gestellt, um sicherzustellen, dass Berechtigungsprüfungen nicht auf andere Weise umgangen werden können, z. B. nach einem Zurücksetzen des Geräts.
Eine standardmäßige und gut unterstützte IOMMU für Arm-Geräte, die sowohl die Isolation als auch die direkte Zuweisung ermöglicht, ist die Arm System Memory Management Unit (SMMU)-Architektur. Diese Architektur ist die empfohlene Referenzlösung.
Eigentum an Erinnerungen
Beim Start wird davon ausgegangen, dass der Host den gesamten Nicht-Hypervisor-Arbeitsspeicher besitzt. Der Hypervisor verfolgt ihn entsprechend. Wenn eine pVM erstellt wird, stellt der Host Arbeitsspeicherseiten zur Verfügung, damit sie gestartet werden kann. Der Hypervisor überträgt die Eigentümerschaft dieser Seiten vom Host auf die pVM. Der Hypervisor richtet also Zugriffsbeschränkungen in der Seitentabelle der Phase 2 des Hosts ein, um zu verhindern, dass er wieder auf die Seiten zugreift, und so die Vertraulichkeit des Gastes zu gewährleisten.
Die Kommunikation zwischen dem Host und den Gästen wird durch die kontrollierte gemeinsame Nutzung des Speichers zwischen ihnen ermöglicht. Gäste dürfen einige ihrer Seiten über einen Hypercall an den Host zurückgeben. Dadurch wird der Hypervisor angewiesen, diese Seiten in der Host-Seitentabelle der Stufe 2 neu zuzuordnen. Ebenso wird die Kommunikation des Hosts mit TrustZone durch das gemeinsame Nutzen von Arbeitsspeicher und/oder durch Leihvorgänge ermöglicht. Alle diese Vorgänge werden von pKVM mithilfe der Firmware Framework for Arm (FF-A) specification genau überwacht und gesteuert.
Da sich die Speicheranforderungen einer pVM im Laufe der Zeit ändern können, wird ein Hypercall bereitgestellt, mit dem die Inhaberschaft bestimmter Seiten, die dem Aufrufer gehören, an den Host zurückgegeben werden kann. In der Praxis wird dieser Hypercall mit dem Virtio-Balloon-Protokoll verwendet, damit der VMM Speicher vom pVM anfordern und der pVM den VMM über freigegebene Seiten informieren kann.
Der Hypervisor ist dafür verantwortlich, den Besitz aller Speicherseiten im System zu verfolgen und zu prüfen, ob sie für andere Einheiten freigegeben oder an diese ausgeliehen werden. Der Großteil dieser Statusverfolgung erfolgt mithilfe von Metadaten, die an die Seitenübersichten der Phase 2 des Hosts und der Gäste angehängt werden. Dabei werden reservierte Bits in den Seitentabelleneinträgen (Page Table Entries, PTEs) verwendet, die, wie der Name schon sagt, für die Softwarenutzung reserviert sind.
Der Host muss dafür sorgen, dass er nicht versucht, auf Seiten zuzugreifen, die vom Hypervisor unzugänglich gemacht wurden. Ein illegaler Hostzugriff führt dazu, dass der Hypervisor eine synchrone Ausnahme in den Host einfügt, was entweder dazu führt, dass die verantwortliche Userspace-Aufgabe ein SEGV-Signal empfängt, oder der Host-Kernel abstürzt. Um versehentliche Zugriffe zu verhindern, können vom Host-Kernel keine Seiten, die Gästen zugewiesen wurden, getauscht oder zusammengeführt werden.
Unterbrechungsbehandlung und Timer
Unterbrechungen sind ein wesentlicher Bestandteil der Interaktion eines Gastbetriebssystems mit Geräten und der Kommunikation zwischen CPUs, wobei Interprocessor Interrupts (IPIs) der wichtigste Kommunikationsmechanismus sind. Beim KVM-Modell wird die gesamte Verwaltung virtueller Interrupts an den Host in EL1 delegiert, der sich zu diesem Zweck als nicht vertrauenswürdiger Teil des Hypervisors verhält.
pKVM bietet eine vollständige Emulation des Generic Interrupt Controller Version 3 (GICv3) basierend auf dem vorhandenen KVM-Code. Timer und IPIs werden als Teil dieses nicht vertrauenswürdigen Emulationscodes verarbeitet.
GICv3-Unterstützung
Die Schnittstelle zwischen EL1 und EL2 muss dafür sorgen, dass der vollständige Interrupt-Status für den EL1-Host sichtbar ist, einschließlich Kopien der Hypervisor-Register, die sich auf Interrupts beziehen. Diese Sichtbarkeit wird in der Regel durch gemeinsam genutzte Speicherbereiche erreicht, einen pro virtueller CPU (vCPU).
Der Laufzeit-Supportcode für Systemregister kann vereinfacht werden, sodass nur das Abfangen von Software Generated Interrupt Register (SGIR) und Deactivate Interrupt Register (DIR) unterstützt wird. Die Architektur schreibt vor, dass diese Register immer in EL2 abgefangen werden, während die anderen Traps bisher nur zur Behebung von Errata nützlich waren. Alles andere wird in der Hardware erledigt.
Auf der MMIO-Seite wird alles auf EL1 emuliert und die gesamte aktuelle Infrastruktur in KVM wiederverwendet. Schließlich wird Wait for Interrupt (WFI) immer an EL1 weitergeleitet, da dies eine der grundlegenden Scheduling-Primitiven ist, die KVM verwendet.
Timerunterstützung
Der Vergleichswert für den virtuellen Timer muss bei jedem Trapping-WFI für EL1 verfügbar sein, damit EL1 Timer-Unterbrechungen einschleusen kann, während die vCPU blockiert ist. Der physische Timer wird vollständig emuliert und alle Traps werden an EL1 weitergeleitet.
MMIO-Verarbeitung
Um mit dem Virtual Machine Monitor (VMM) zu kommunizieren und die GIC-Emulation durchzuführen, müssen MMIO-Traps zur weiteren Analyse an den Host in EL1 weitergeleitet werden. pKVM erfordert Folgendes:
- IPA und Größe des Zugriffs
- Daten im Fall eines Schreibvorgangs
- Endianness der CPU zum Zeitpunkt des Trappings
Außerdem werden Traps mit einem GPR (General Purpose Register) als Quelle/Ziel über ein abstraktes Transfer-Pseudoregister weitergeleitet.
Gastschnittstellen
Ein Gast kann mit einem geschützten Gast über eine Kombination aus Hypercalls und Speicherzugriff auf abgefangene Regionen kommunizieren. Hypercalls werden gemäß dem SMCCC-Standard bereitgestellt. Ein Bereich ist für eine Anbieterzuweisung durch KVM reserviert. Die folgenden Hypercalls sind für pKVM-Gäste von besonderer Bedeutung.
Generische Hypercalls
- PSCI bietet einen Standardmechanismus für den Gast, um den Lebenszyklus seiner vCPUs zu steuern, einschließlich Onlining, Offlining und Herunterfahren des Systems.
- TRNG bietet einen Standardmechanismus, mit dem der Gast Entropie vom pKVM anfordern kann, der den Aufruf an EL3 weiterleitet. Dieser Mechanismus ist besonders nützlich, wenn der Host nicht vertrauenswürdig genug ist, um einen Hardware-Zufallszahlengenerator (RNG) zu virtualisieren.
pKVM-Hypercalls
- Speicherfreigabe mit dem Host Der gesamte Gastarbeitsspeicher ist anfangs für den Host nicht zugänglich. Der Hostzugriff ist jedoch für die Kommunikation über den gemeinsam genutzten Arbeitsspeicher und für paravirtualisierte Geräte erforderlich, die auf gemeinsam genutzte Puffer angewiesen sind. Hypercalls zum Freigeben und Aufheben der Freigabe von Seiten für den Host ermöglichen es dem Gast, genau festzulegen, welche Teile des Speichers für den Rest von Android zugänglich gemacht werden, ohne dass ein Handshake erforderlich ist.
- Arbeitsspeicher, der an den Host zurückgegeben wird. Der gesamte Gastspeicher gehört in der Regel dem Gast, bis er zerstört wird. Dieser Zustand kann für langlebige VMs mit sich im Laufe der Zeit ändernden Speicheranforderungen unzureichend sein. Mit dem
relinquish-Hypercall kann ein Gast die Inhaberschaft von Seiten explizit an den Host zurückgeben, ohne dass der Gast beendet werden muss. - Speicherzugriff auf den Host umleiten. Wenn ein KVM-Gast auf eine Adresse zugreift, die keiner gültigen Speicherregion entspricht, wird der vCPU-Thread normalerweise beendet und der Zugriff wird in der Regel für MMIO verwendet und vom VMM im Nutzerbereich emuliert. Um diese Verarbeitung zu ermöglichen, muss pKVM Details zur fehlerhaften Anweisung wie ihre Adresse, Registerparameter und möglicherweise deren Inhalt an den Host zurückgeben. Dadurch könnten unbeabsichtigt vertrauliche Daten aus einem geschützten Gast offengelegt werden, wenn die Trap nicht erwartet wurde. pKVM löst dieses Problem, indem diese Fehler als schwerwiegend behandelt werden, es sei denn, der Gast hat zuvor einen Hypercall ausgegeben, um den fehlerhaften IPA-Bereich als einen zu identifizieren, für den Zugriffe zulässig sind, um zum Host zurückzukehren. Diese Lösung wird als MMIO-Schutz bezeichnet.
Virtuelles E/A-Gerät (virtio)
Virtio ist ein beliebter, portabler und ausgereifter Standard für die Implementierung und Interaktion mit paravirtualisierten Geräten. Die meisten Geräte, die geschützten Gästen zur Verfügung gestellt werden, sind mit virtio implementiert. Virtio ist auch die Grundlage für die vsock-Implementierung, die für die Kommunikation zwischen einem geschützten Gast und dem Rest von Android verwendet wird.
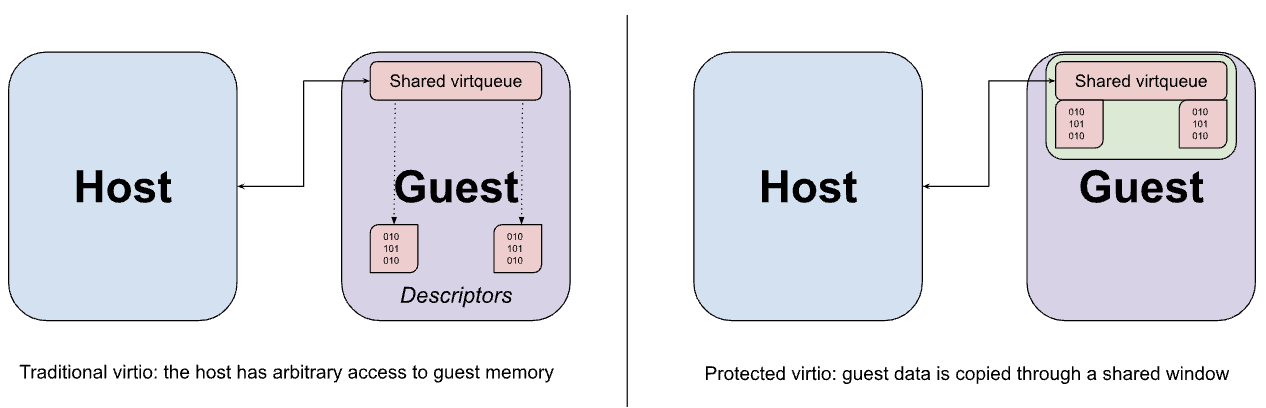
Virtio-Geräte werden in der Regel vom VMM im Userspace des Hosts implementiert. Der VMM fängt die abgefangenen Speicherzugriffe des Gastes auf die MMIO-Schnittstelle des Virtio-Geräts ab und emuliert das erwartete Verhalten. Der MMIO-Zugriff ist relativ teuer, da für jeden Zugriff auf das Gerät ein Roundtrip zum VMM und zurück erforderlich ist. Daher erfolgt der Großteil der tatsächlichen Datenübertragung zwischen dem Gerät und dem Gast über eine Reihe von Virtqueues im Arbeitsspeicher. Eine wichtige Annahme von virtio ist, dass der Host beliebig auf den Gastspeicher zugreifen kann. Diese Annahme ist im Design der virtqueue ersichtlich, die möglicherweise Zeiger auf Puffer im Gast enthält, auf die die Geräteemulation direkt zugreifen soll.
Obwohl die zuvor beschriebenen Memory-Sharing-Hypercalls verwendet werden könnten, um Virtio-Datenpuffer vom Gast zum Host freizugeben, erfolgt diese Freigabe notwendigerweise auf Seitenebene und könnte mehr Daten als erforderlich freigeben, wenn die Puffergröße kleiner als die einer Seite ist. Stattdessen ist der Gast so konfiguriert, dass sowohl die Virtqueues als auch die entsprechenden Datenpuffer aus einem festen Fenster des gemeinsam genutzten Speichers zugewiesen werden. Die Daten werden nach Bedarf in das Fenster kopiert (bounced) und aus dem Fenster kopiert.
Interaktion mit TrustZone
Gäste können zwar nicht direkt mit TrustZone interagieren, der Host muss aber weiterhin SMC-Aufrufe in die sichere Welt ausgeben können. Bei diesen Aufrufen können physisch adressierte Speicherpuffer angegeben werden, auf die der Host nicht zugreifen kann. Da die sichere Software in der Regel nicht weiß, ob der Puffer zugänglich ist, könnte ein schädlicher Host diesen Puffer für einen Confused-Deputy-Angriff (analog zu einem DMA-Angriff) verwenden. Um solche Angriffe zu verhindern, fängt pKVM alle Host-SMC-Aufrufe an EL2 ab und fungiert als Proxy zwischen dem Host und dem sicheren Monitor auf EL3.
PSCI-Aufrufe vom Host werden mit minimalen Änderungen an die EL3-Firmware weitergeleitet. Insbesondere wird der Einstiegspunkt für eine CPU, die online geht oder aus dem Ruhezustand reaktiviert wird, so umgeschrieben, dass die Seitentabelle der zweiten Phase auf EL2 installiert wird, bevor zum Host auf EL1 zurückgekehrt wird. Während des Bootvorgangs wird dieser Schutz von pKVM erzwungen.
Diese Architektur basiert darauf, dass das SoC PSCI unterstützt, vorzugsweise durch die Verwendung einer aktuellen Version von TF-A als EL3-Firmware.
Der FF-A-Standard (Firmware Framework for Arm) standardisiert Interaktionen zwischen der normalen und der sicheren Welt, insbesondere bei einem sicheren Hypervisor. Ein wichtiger Teil der Spezifikation definiert einen Mechanismus zum Freigeben von Arbeitsspeicher für die sichere Welt, wobei sowohl ein gemeinsames Nachrichtenformat als auch ein genau definiertes Berechtigungsmodell für die zugrunde liegenden Seiten verwendet werden. pKVM leitet FF-A-Nachrichten weiter, um sicherzustellen, dass der Host nicht versucht, Arbeitsspeicher für die sichere Seite freizugeben, für die er nicht über ausreichende Berechtigungen verfügt.
Diese Architektur basiert darauf, dass die Software der sicheren Welt das Speichermodell erzwingt, um sicherzustellen, dass vertrauenswürdige Apps und andere Software, die in der sicheren Welt ausgeführt wird, nur dann auf den Speicher zugreifen können, wenn er entweder ausschließlich der sicheren Welt gehört oder explizit über FF-A für sie freigegeben wurde. Auf einem System mit S-EL2 sollte die Durchsetzung des Speicherzugriffsmodells durch einen Secure Partition Manager Core (SPMC) wie Hafnium erfolgen, der Stage 2-Seitentabellen für die sichere Welt verwaltet. Auf einem System ohne S-EL2 kann das TEE stattdessen ein Speichermodell über seine Stage 1-Seitentabellen erzwingen.
Wenn der SMC-Aufruf an EL2 kein PSCI-Aufruf oder keine von FF-A definierte Nachricht ist, werden nicht verarbeitete SMCs an EL3 weitergeleitet. Es wird davon ausgegangen, dass die (notwendigerweise vertrauenswürdige) sichere Firmware nicht behandelte SMCs sicher verarbeiten kann, da die Firmware die Vorsichtsmaßnahmen kennt, die zur Aufrechterhaltung der pVM-Isolation erforderlich sind.
Virtual Machine Monitor
crosvm ist ein Virtual Machine Monitor (VMM), der virtuelle Maschinen über die KVM-Schnittstelle von Linux ausführt. Crosvm zeichnet sich durch seinen Fokus auf Sicherheit aus. Es wird die Programmiersprache Rust verwendet und virtuelle Geräte werden in einer Sandbox ausgeführt, um den Hostkernel zu schützen. Weitere Informationen zu crosvm finden Sie in der offiziellen Dokumentation.
Dateideskriptoren und ioctls
KVM stellt das /dev/kvm-Zeichengerät für den Nutzerbereich mit ioctls bereit, aus denen die KVM API besteht. Die ioctls gehören zu den folgenden Kategorien:
- Mit System-Ioctls werden globale Attribute abgefragt und festgelegt, die sich auf das gesamte KVM-Subsystem auswirken, und pVMs erstellt.
- Mit VM-Ioctls werden Attribute abgefragt und festgelegt, die virtuelle CPUs (vCPUs) und Geräte erstellen und sich auf eine gesamte pVM auswirken, z. B. auf das Speicherlayout und die Anzahl der virtuellen CPUs (vCPUs) und Geräte.
- Mit vCPU-ioctls werden Attribute abgefragt und festgelegt, die den Betrieb einer einzelnen virtuellen CPU steuern.
- Mit Geräte-Ioctls werden Attribute abgefragt und festgelegt, die den Betrieb eines einzelnen virtuellen Geräts steuern.
In jedem „crosvm“-Prozess wird genau eine Instanz einer virtuellen Maschine ausgeführt. Bei diesem Vorgang wird der KVM_CREATE_VM-System-ioctl verwendet, um einen VM-Dateideskriptor zu erstellen, mit dem pVM-ioctls ausgegeben werden können. Ein KVM_CREATE_VCPU- oder KVM_CREATE_DEVICE-ioctl für einen VM-FD erstellt eine vCPU/ein Gerät und gibt einen Dateideskriptor zurück, der auf die neue Ressource verweist. ioctls für einen vCPU- oder Geräte-FD können verwendet werden, um das Gerät zu steuern, das mit dem ioctl für einen VM-FD erstellt wurde. Bei vCPUs umfasst dies die wichtige Aufgabe, Gastcode auszuführen.
Intern registriert crosvm die Dateideskriptoren der VM mit dem Kernel über die edge-getriggerte epoll-Schnittstelle. Der Kernel benachrichtigt crosvm dann, wenn in einem der Dateideskriptoren ein neues Ereignis ansteht.
pKVM fügt eine neue Funktion hinzu, KVM_CAP_ARM_PROTECTED_VM, mit der Informationen zur pVM-Umgebung abgerufen und der geschützte Modus für eine VM eingerichtet werden kann. crosvm verwendet diese Funktion während der pVM-Erstellung, wenn das Flag --protected-vm übergeben wird, um die entsprechende Menge an Arbeitsspeicher für die pVM-Firmware abzufragen und zu reservieren und dann den geschützten Modus zu aktivieren.
Arbeitsspeicherzuweisung
Eine der Hauptaufgaben eines VMM ist die Zuweisung des VM-Speichers und die Verwaltung des Speicherlayouts. crosvm generiert ein festes Speicherlayout, das in der Tabelle unten grob beschrieben wird.
| FDT im normalen Modus | PHYS_MEMORY_END - 0x200000
|
| Freier Speicherplatz | ...
|
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Kernel | 0x80080000
|
| Bootloader | 0x80200000
|
| FDT im BIOS-Modus | 0x80000000
|
| Basis des physischen Speichers | 0x80000000
|
| pVM-Firmware | 0x7FE00000
|
| Gerätespeicher | 0x10000 - 0x40000000
|
Der physische Arbeitsspeicher wird mit mmap zugewiesen und der VM zur Verfügung gestellt, um ihre Speicherbereiche, die als memslots bezeichnet werden, mit dem KVM_SET_USER_MEMORY_REGION-ioctl zu füllen. Der gesamte Arbeitsspeicher der Gast-pVM wird daher der crosvm-Instanz zugewiesen, die ihn verwaltet. Wenn der Host nicht mehr über genügend kostenlosen Arbeitsspeicher verfügt, kann dies dazu führen, dass der Prozess beendet wird und die VM damit beendet wird. Wenn eine VM beendet wird, wird der Arbeitsspeicher automatisch vom Hypervisor gelöscht und an den Hostkernel zurückgegeben.
Bei regulärem KVM behält der VMM den Zugriff auf den gesamten Gastarbeitsspeicher. Bei pKVM wird der Gastarbeitsspeicher aus dem physischen Adressraum des Hosts entfernt, wenn er an den Gast übergeben wird. Die einzige Ausnahme ist Speicher, der explizit vom Gast freigegeben wird, z. B. für Virtio-Geräte.
MMIO-Bereiche im Adressraum des Gastbetriebssystems bleiben nicht zugeordnet. Der Zugriff des Gastes auf diese Regionen wird abgefangen und führt zu einem E/A-Ereignis auf dem VM-FD. Dieser Mechanismus wird verwendet, um virtuelle Geräte zu implementieren. Im geschützten Modus muss der Gast über einen Hypercall bestätigen, dass ein Bereich seines Adressraums für MMIO verwendet wird, um das Risiko eines versehentlichen Informationslecks zu verringern.
Wird geplant
Jede virtuelle CPU wird durch einen POSIX-Thread dargestellt und vom Host-Linux-Scheduler geplant. Der Thread ruft den KVM_RUN-ioctl für den vCPU-FD auf. Dadurch wechselt der Hypervisor zum Gast-vCPU-Kontext. Der Host-Scheduler berücksichtigt die Zeit, die in einem Gastkontext verbracht wird, als Zeit, die vom entsprechenden vCPU-Thread verwendet wird. KVM_RUN wird zurückgegeben, wenn ein Ereignis eintritt, das vom VMM verarbeitet werden muss, z. B. E/A, Ende des Interrupts oder die vCPU wurde angehalten. Der VMM verarbeitet das Ereignis und ruft KVM_RUN noch einmal auf.
Während KVM_RUN bleibt der Thread für den Host-Scheduler unterbrechbar, mit Ausnahme der Ausführung des EL2-Hypervisor-Codes, der nicht unterbrechbar ist. Die Gast-pVM selbst bietet keine Möglichkeit, dieses Verhalten zu steuern.
Da alle vCPU-Threads wie alle anderen Userspace-Aufgaben geplant werden, unterliegen sie allen Standard-QoS-Mechanismen. Konkret kann jeder vCPU-Thread an physische CPUs gebunden, in CPU-Sets platziert, durch die Nutzungsklemmung verstärkt oder begrenzt und seine Priorität/Scheduling-Richtlinie geändert werden.
Virtuelle Geräte
crosvm unterstützt eine Reihe von Geräten, darunter:
- virtio-blk für zusammengesetzte Laufwerk-Images, schreibgeschützt oder Lese-/Schreibzugriff
- vhost-vsock für die Kommunikation mit dem Host
- virtio-pci als virtio-Transport
- pl030 Echtzeituhr (RTC)
- 16550A-UART für die serielle Kommunikation
pVM-Firmware
Die pVM-Firmware (pvmfw) ist der erste Code, der von einer pVM ausgeführt wird, ähnlich dem Boot-ROM eines physischen Geräts. Das primäre Ziel von pvmfw ist es, Secure Boot zu starten und das eindeutige Geheimnis der pVM abzuleiten. pvmfw ist nicht auf die Verwendung mit einem bestimmten Betriebssystem wie Microdroid beschränkt, solange das Betriebssystem von crosvm unterstützt wird und ordnungsgemäß signiert wurde.
Die binäre Datei „pvmfw“ wird in einer Flash-Partition mit demselben Namen gespeichert und über OTA aktualisiert.
Gerät startet
Dem Bootvorgang eines pKVM-fähigen Geräts wird die folgende Abfolge von Schritten hinzugefügt:
- Der Android-Bootloader (ABL) lädt pvmfw aus seiner Partition in den Arbeitsspeicher und prüft das Image.
- Der ABL bezieht seine DICE-Secrets (Device Identifier Composition Engine) (Compound Device Identifiers, CDIs, und DICE-Zertifikatskette) von einem Root of Trust.
- Die ABL leitet die erforderlichen CDIs für pvmfw ab und hängt sie an die pvmfw-Binärdatei an.
- Der ABL fügt dem Gerätebaum einen Knoten für den reservierten Speicherbereich
linux,pkvm-guest-firmware-memoryhinzu, der den Speicherort und die Größe des pvmfw-Binärprogramms und der im vorherigen Schritt abgeleiteten Secrets beschreibt. - ABL übergibt die Steuerung an Linux und Linux initialisiert pKVM.
- pKVM hebt die Zuordnung des pvmfw-Arbeitsspeicherbereichs aus den Stage-2-Seitentabellen des Hosts auf und schützt ihn während der gesamten Betriebszeit des Geräts vor dem Host (und den Gästen).
Nach dem Start des Geräts wird Microdroid gemäß den Schritten im Abschnitt Boot-Sequenz des Dokuments Microdroid gestartet.
pVM-Boot
Beim Erstellen einer pVM muss crosvm (oder ein anderer VMM) einen ausreichend großen memslot erstellen, der vom Hypervisor mit dem pvmfw-Image gefüllt wird. Der VMM ist auch auf die Liste der Register beschränkt, deren Anfangswert er festlegen kann (x0–x14 für die primäre vCPU, keine für sekundäre vCPUs). Die verbleibenden Register sind reserviert und Teil des Hypervisor-pvmfw-ABI.
Wenn die pVM ausgeführt wird, übergibt der Hypervisor zuerst die Steuerung der primären vCPU an pvmfw. Die Firmware erwartet, dass crosvm einen AVB-signierten Kernel geladen hat, der ein Bootloader oder ein anderes Image sein kann, und ein unsigniertes FDT in den Arbeitsspeicher an bekannten Offsets. pvmfw validiert die AVB-Signatur und generiert bei Erfolg einen vertrauenswürdigen Gerätebaum aus dem empfangenen FDT, löscht seine Geheimnisse aus dem Arbeitsspeicher und verzweigt zum Einstiegspunkt der Nutzlast. Wenn einer der Überprüfungsschritte fehlschlägt, gibt die Firmware einen PSCI-Hypercall SYSTEM_RESET aus.
Zwischen den Starts werden Informationen zur pVM-Instanz in einer Partition (virtio-blk-Gerät) gespeichert und mit dem Secret von pvmfw verschlüsselt, damit das Secret nach einem Neustart für die richtige Instanz bereitgestellt wird.