
Android 8.0 zawiera testy wydajności bindera i hwbindera dotyczące przepustowości i opóźnienia. Istnieje wiele scenariuszy wykrywania zauważalnych problemów z wydajnością, ale ich uruchamianie może być czasochłonne, a wyniki często są dostępne dopiero po integracji systemu. Wykorzystanie dostępnych testów wydajności ułatwia testowanie podczas tworzenia aplikacji, pozwala wcześniej wykrywać poważne problemy i poprawia wrażenia użytkowników.
Testy wydajności obejmują 4 kategorie:
- przepustowość binder (dostępna w
system/libhwbinder/vts/performance/Benchmark_binder.cpp), - opóźnienie Bindera (dostępne w
frameworks/native/libs/binder/tests/schd-dbg.cpp), - Przepustowość hwbinder (dostępna w
system/libhwbinder/vts/performance/Benchmark.cpp) - opóźnienie hwbinder (dostępne w
system/libhwbinder/vts/performance/Latency.cpp);
Informacje o binder i hwbinder
Binder i hwbinder to infrastruktury komunikacji międzyprocesowej (IPC) Androida, które korzystają z tego samego sterownika Linuxa, ale różnią się od siebie w następujący sposób:
| Proporcje | segregator | hwbinder |
|---|---|---|
| Cel | Przekazanie ogólnego schematu IPC dla frameworku | Komunikacja ze sprzętem |
| Właściwość | Optymalizacja pod kątem używania frameworka Androida | Minimalne opóźnienie |
| Zmiana zasad harmonogramu dla pierwszego planu i tła | Tak | Nie |
| Przekazywanie argumentów | Używa serializacji obsługiwanej przez obiekt Parcel | Używa buforów rozproszonych i unika narzutu związanego z kopiowaniem danych wymaganych do serializacji pakietu. |
| Dziedziczenie priorytetów | Nie | Tak |
Procesy Binder i hwbinder
Wizualizacja systrace przedstawia transakcje w ten sposób:
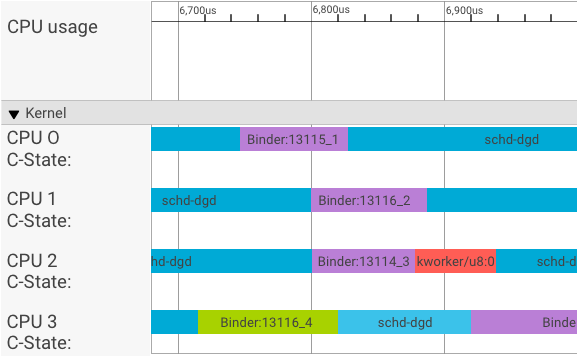
W tym przykładzie:
- Cztery (4) procesy schd-dbg to procesy klienta.
- Cztery (4) procesy bindera to procesy serwera (nazwa zaczyna się od Binder i kończy numerem sekwencji).
- Proces klienta jest zawsze sparowany z procesem serwera, który jest dedykowany dla tego klienta.
- Wszystkie pary procesów klient-serwer są planowane niezależnie przez jądro.
W procesorze CPU 1 jądro systemu operacyjnego wykonuje klienta, aby wysłać żądanie. Następnie, gdy tylko to możliwe, używa tego samego procesora, aby obudzić proces serwera, obsłużyć żądanie i po jego zakończeniu przełączyć kontekst z powrotem.
Przepustowość a opóźnienie
W idealnej transakcji, w której procesy klienta i serwera są przełączane płynnie, testy przepustowości i opóźnienia nie dają znacznie różnych wyników. Jednak gdy jądro systemu operacyjnego obsługuje żądanie przerwania (IRQ) z urządzenia, czeka na blokady lub po prostu nie obsługuje od razu wiadomości, może powstać bufor opóźnienia.
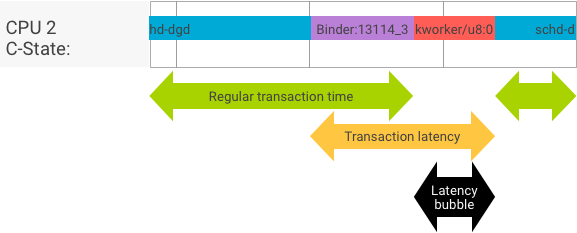
Test przepustowości generuje dużą liczbę transakcji o różnych rozmiarach danych, co pozwala uzyskać dobrą estymację zwykłego czasu transakcji (w najlepszym przypadku) i maksymalnej przepustowości, jakiej może dokonać binder.
Test opóźnienia nie wykonuje żadnych działań na ładunku, aby zminimalizować czas trwania zwykłej transakcji. Czas transakcji pozwala nam oszacować nakład na binder, tworzyć statystyki dla najgorszego przypadku i obliczać współczynnik transakcji, których opóźnienie mieści się w określonym terminie.
Obsługa odwrócenia priorytetów
Odwrócenie priorytetów ma miejsce, gdy wątek o wyższym priorytecie oczekuje logicznie na wątek o niższym priorytecie. Aplikacje działające w czasie rzeczywistym mają problem z odwróceniem priorytetów:
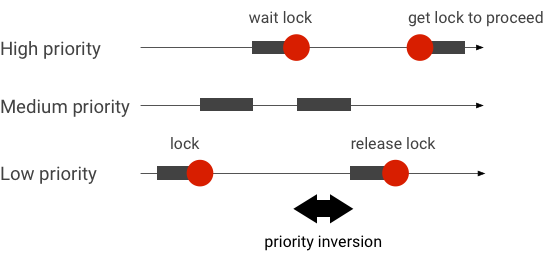
Gdy używasz planowania Linux Completely Fair Scheduler (CFS), wątek zawsze ma szansę na uruchomienie, nawet jeśli inne wątki mają wyższy priorytet. W rezultacie aplikacje z harmonogramem CFS obsługują odwrócenie priorytetów zgodnie z oczekiwaniami, a nie jako problem. W przypadkach, gdy platforma Android musi korzystać z planowania RT, aby zagwarantować uprawnienia wątków o wysokim priorytecie, odwrócenie priorytetów musi zostać rozwiązane.
Przykład odwrócenia priorytetu podczas transakcji bindera (wątek RT jest logicznie zablokowany przez inne wątki CFS, gdy oczekuje na obsługę przez wątek bindera):
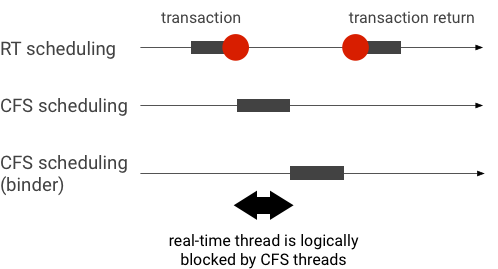
Aby uniknąć blokad, możesz użyć dziedziczenia priorytetów, aby tymczasowo przekazać wątek Binder do wątku RT, gdy obsługuje żądanie od klienta RT. Pamiętaj, że harmonogramowanie w czasie rzeczywistym ma ograniczone zasoby i należy używać go ostrożnie. W systemie z n procesorami maksymalna liczba bieżących wątków RT wynosi również n; dodatkowe wątki RT mogą musieć poczekać (i w ten sposób przekroczyć terminy), jeśli wszystkie procesory są zajęte przez inne wątki RT.
Aby rozwiązać wszystkie możliwe odwrócenia priorytetów, możesz użyć dziedziczenia priorytetów zarówno w binder, jak i hwbinder. Jednak binder jest szeroko stosowany w systemie, a włączenie dziedziczenia priorytetów w przypadku transakcji bindera może spowodować, że system będzie spamować więcej wątków RT, niż jest w stanie obsłużyć.
Przeprowadzanie testów przepustowości
Test przepustowości jest przeprowadzany na podstawie przepustowości transakcji bindera/hwbindera. W systemie, który nie jest przeciążony, bańki opóźnień występują rzadko, a ich wpływ można wyeliminować, o ile liczba iteracji jest wystarczająco wysoka.
- Test przepustowości bindera jest w fazie
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Test przepustowości hwbinder jest w fazie
system/libhwbinder/vts/performance/Benchmark.cpp.
Wyniki testu
Przykładowe wyniki testu przepustowości dla transakcji korzystających z różnych rozmiarów ładunku:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Czas wskazuje opóźnienie w obie strony mierzone w czasie rzeczywistym.
- CPU wskazuje skumulowany czas, w którym procesory są zaplanowane do testu.
- Iteracje wskazują, ile razy została wykonana funkcja testowa.
Na przykład w przypadku ładunku 8-bajtowego:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… maksymalna przepustowość, jaką może osiągnąć binder, jest obliczana w ten sposób:
Maksymalna przepustowość przy 8-bajtowym ładunku użytecznym = (8 * 21296)/69974 ≈ 2,423 b/ns ≈ 2,268 Gb/s
Opcje testowania
Aby uzyskać wyniki w formacie .json, uruchom test z argumentem --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Przeprowadzanie testów opóźnień
Test opóźnienia mierzy czas potrzebny klientowi na zainicjowanie transakcji, przełączenie na proces serwera w celu jego przetworzenia i otrzymanie wyniku. Test sprawdza też znane złe zachowania harmonogramu, które mogą negatywnie wpływać na opóźnienie transakcji, np. harmonogram, który nie obsługuje dziedziczenia priorytetów lub nie respektuje flagi synchronizacji.
- Test opóźnienia w binderze jest w fazie
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Test opóźnienia hwbindera jest w
system/libhwbinder/vts/performance/Latency.cpp.
Wyniki testu
Wyniki (w formacie .json) zawierają statystyki dotyczące średniego/najlepszego/najgorszego opóźnienia oraz liczby przekroczonych terminów.
Opcje testowania
Testy opóźnień mają te opcje:
| Polecenie | Opis |
|---|---|
-i value |
Określ liczbę iteracji. |
-pair value |
Podaj liczbę par procesów. |
-deadline_us 2500 |
Podaj termin w godzinach czasu UTC. |
-v |
wyświetlić szczegółowy (debugujący) wynik. |
-trace |
Zatrzymanie śledzenia po osiągnięciu limitu czasu. |
W sekcjach poniżej znajdziesz szczegółowe informacje o każdej opcji, opis sposobu jej użycia oraz przykładowe wyniki.
Określanie iteracji
Przykład z dużą liczbą iteracji i wyłączonym szczegółowym wyjściem:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Wyniki testu zawierają:
"pair":3- Tworzy jedną parę klienta i serwera.
"iterations": 5000- Obejmuje 5000 iteracji.
"deadline_us":2500- Limit czasu to 2500 μs (2,5 ms); większość transakcji powinna się zmieścić w tym zakresie.
"I": 10000- Pojedyncza iteracja testu obejmuje 2 transakcje:
- Jedna transakcja o normalnym priorytecie (
CFS other) - Jedna transakcja według priorytetu w czasie rzeczywistym (
RT-fifo)
- Jedna transakcja o normalnym priorytecie (
"S": 9352- 9352 transakcji jest synchronizowanych na tym samym procesorze.
"R": 0.9352- Wskazuje współczynnik synchronizacji klienta i serwera na tym samym procesorze.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Średni (
avg), najgorszy (wst) i najlepszy (bst) przypadek wszystkich transakcji wywołanych przez normalnego wywołującego o priorytecie normalnym. 2 transakcjemisstermin, co daje współczynnik zgodności (meetR) 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Podobna do
other_ms, ale dotyczy transakcji zleconych przez klienta z priorytetemrt_fifo. Prawdopodobnie (ale nie jest to wymagane), żefifo_msma lepszy wynik niżother_ms, z niższymi wartościamiavgiwstoraz wyższą wartościąmeetR(różnica może być jeszcze większa przy wczytywaniu w tle).
Uwaga: obciążenie w tle może wpływać na wynik przepływu danych i other_ms w teście opóźnienia. Tylko fifo_ms może wyświetlać podobne wyniki, o ile wczytywanie w tle ma niższy priorytet niż RT-fifo.
Określanie wartości par
Każdy proces klienta jest sparowany z odpowiednim procesem serwera, a każda para może być zaplanowana niezależnie od dowolnego procesora. Jednak przenoszenie procesora nie powinno mieć miejsca podczas transakcji, o ile flaga SYNC jest ustawiona na wartośćhonor.
Upewnij się, że system nie jest przeciążony. Oczekuje się, że w przypadku przeciążonego systemu czas oczekiwania będzie długi, a wyniki testów w takim przypadku nie dostarczą przydatnych informacji. Aby przetestować system przy wyższym ciśnieniu, użyj -pair
#cpu-1 (lub -pair #cpu z ostrożnością). Testowanie za pomocą
-pair n z
n > #cpu przeciąża system i generuje bezużyteczne informacje.
Określanie wartości terminów
Po przeprowadzeniu obszernych testów scenariuszy użytkownika (test opóźnienia w kwalifikowanym produkcie) ustaliliśmy, że maksymalny dopuszczalny czas to 2,5 ms. W przypadku nowych aplikacji o wyższych wymaganiach (np. 1000 zdjęć na sekundę) ta wartość terminu ulegnie zmianie.
Określanie szczegółowych danych wyjściowych
Opcja -v wyświetla szczegółowy wynik. Przykład:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Wątek usługi jest tworzony z priorytetem
SCHED_OTHERi uruchamiany w procesieCPU:1z poziomempid 8674. fifo-calleruruchamia pierwszą transakcję. Aby obsłużyć tę transakcję, hwbinder podnosi priorytet serwera (pid: 8674 tid: 8676) do 99, a także oznacza go klasą planowania przejściowego (wydrukowaną jako???). Następnie planista umieszcza proces serwera wCPU:0, aby go uruchomić, i zsynchronizuje go z tym samym procesorem co klient.- Wywołujący drugiej transakcji ma priorytet
SCHED_OTHER. Serwer obniża priorytet i obsługuje wywołanie z priorytetemSCHED_OTHER.
Korzystanie z śledzenia do debugowania
Aby debugować problemy z opóźnieniami, możesz użyć opcji -trace. Gdy jest używany, test opóźnienia zatrzymuje rejestrowanie pliku dziennika w momencie wykrycia dużego opóźnienia. Przykład:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Na opóźnienie mogą mieć wpływ te komponenty:
- Tryb kompilacji Androida. Tryb inżyniera jest zwykle wolniejszy niż tryb debugowania użytkownika.
- Framework. Jak usługa framework używa
ioctldo konfigurowania bindera? - Napęd silnika. Czy sterownik obsługuje szczegółowe blokowanie? Czy zawiera wszystkie poprawki dotyczące wydajności?
- Wersja jądra. Im lepsze możliwości w czasie rzeczywistym ma jądro, tym lepsze wyniki.
- Konfiguracja jądra. Czy konfiguracja jądra zawiera konfiguracje
DEBUG, takie jakDEBUG_PREEMPTiDEBUG_SPIN_LOCK? - Harmonogram jądra. Czy jądro ma planista oszczędzający energię (EAS) czy planista heterogenicznej wieloprocesorowości (HMP)? Czy jakieś sterowniki jądra (
cpu-freq,cpu-idle,cpu-hotplugitp.) wpływają na harmonogramistę?