
本页将简要介绍如何实现 Neural Networks API (NNAPI) 驱动程序。如需了解更多详细信息,请参阅 hardware/interfaces/neuralnetworks 中 HAL 定义文件中的相关文档。您可以在 frameworks/ml/nn/driver/sample 中找到驱动程序实现示例。
如需详细了解 Neural Networks API,请参阅 Neural Networks API。
神经网络 HAL
神经网络 (NN) HAL 定义了产品(例如手机或平板电脑)中各种设备的抽象概念,例如图形处理单元 (GPU) 和数字信号处理器 (DSP)。这些设备的驱动程序必须符合 NN HAL。接口在 hardware/interfaces/neuralnetworks 中的 HAL 定义文件中指定。
图 1 显示了框架和驱动程序之间的接口遵循的一般流程。
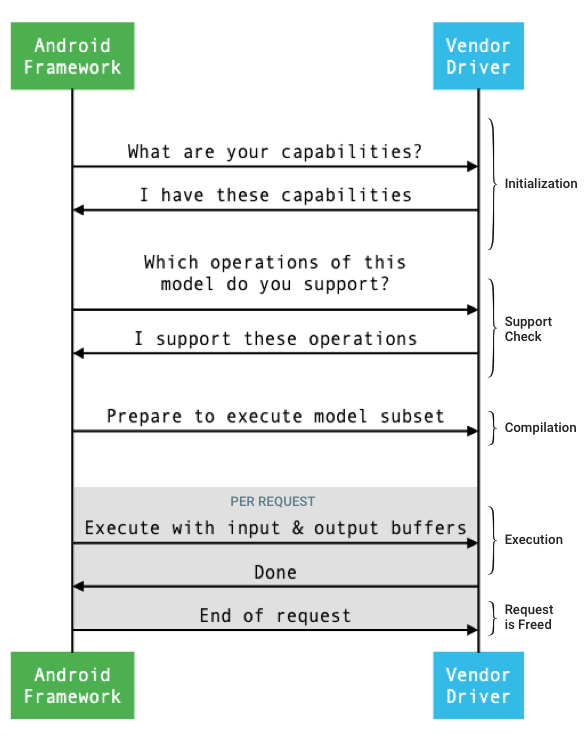
图 1. 神经网络流程
初始化
在进行初始化时,框架使用 IDevice::getCapabilities_1_3 向驱动程序查询其功能。@1.3::Capabilities 结构包括所有数据类型,并使用向量表示非放宽的性能。
为了确定如何将计算分配给可用设备,框架根据这些功能了解每个驱动程序的执行速度和执行能效。为了提供这些信息,驱动程序必须根据参考工作负载的执行情况提供标准化的性能值。
如需确定驱动程序响应 IDevice::getCapabilities_1_3 而返回的值,请使用 NNAPI 基准应用来衡量处理相应数据类型时的性能。建议使用 MobileNet v1 和 v2、asr_float 和 tts_float 模型来衡量处理 32 位浮点值时的性能,并建议使用 MobileNet v1 和 v2 量化模型来衡量处理 8 位量化值时的性能。如需了解详情,请参阅 Android 机器学习测试套件。
在 Android 9 及更低版本中,Capabilities 结构仅包含浮点和量化张量的驱动程序性能信息,不包含标量数据类型的驱动程序性能信息。
在初始化过程中,框架可能会使用 IDevice::getType、IDevice::getVersionString、IDevice:getSupportedExtensions 和 IDevice::getNumberOfCacheFilesNeeded 查询更多信息。
在产品重新启动之间,框架希望本部分中描述的所有查询始终针对指定驱动程序报告相同的值。否则,使用该驱动程序的应用可能会出现性能下降或行为不当的情况。
编译
在收到应用的请求时,框架会确定要使用的设备。在 Android 10 中,应用可以发现并指定设备,让框架从中进行选择。如需了解详情,请参阅设备发现和分配。
在模型编译过程中,框架通过调用 IDevice::getSupportedOperations_1_3 将模型发送到每个候选驱动程序。每个驱动程序都会返回一个布尔值数组,以指出可支持模型的哪些运算。驱动程序可以因为多种原因而决定其无法支持某一运算。例如:
- 驱动程序不支持相应数据类型。
- 驱动程序仅支持具有特定输入参数的运算。例如,驱动程序可能支持 3x3 和 5x5 卷积运算,但不支持 7x7 卷积运算。
- 驱动程序具有内存限制,导致无法处理大型图表或输入。
在编译期间,模型的输入、输出和内部运算数(如 OperandLifeTime 中所述)可能具有未知的维度或秩。如需了解详情,请参阅输出形状。
框架通过调用 IDevice::prepareModel_1_3 指示每个所选驱动程序做好执行模型一部分的准备。然后,每个驱动程序会编译自己负责的那一部分模型。例如,驱动程序可能会生成代码或创建重新排序的权重副本。由于编译模型和执行请求之间可能间隔很长时间,因此不应在编译期间分配诸如大块设备内存等资源。
编译成功后,驱动程序会返回 @1.3::IPreparedModel 句柄。如果驱动程序在准备自己的那一部分模型时返回失败代码,框架会在 CPU 上运行整个模型。
为了减少应用启动时编译所用的时间,驱动程序可以缓存编译工件。如需了解详情,请参阅编译缓存。
执行
当应用要求框架执行请求时,框架会默认调用 IPreparedModel::executeSynchronously_1_3 HAL 方法,以在准备好的模型上同步执行请求。也可以使用 execute_1_3 方法和 executeFenced 方法(请参阅围栏执行) 来异步执行请求,或者使用爆发执行方法来执行请求。
与异步调用相比,同步执行调用可提高性能并减少线程开销,因为只有在执行完成后才将控制权返还给应用进程。这意味着驱动程序不需要单独的机制来通知应用进程执行已完成。
如果使用异步 execute_1_3 方法,控制权在执行开始后便返还给应用进程,并且驱动程序必须在执行完成时使用 @1.3::IExecutionCallback 通知框架。
传递给 execute 方法的 Request 参数列出了用于执行的输入和输出运算数。存储运算数数据的内存必须使用行主序,第一维度的迭代速度最慢,并且在任何行的末尾都没有填充。如需详细了解运算数类型,请参阅运算数。
对于使用 NN HAL 1.2 或更高版本的驱动程序,当请求完成时,错误状态、输出形状和时间信息会返回到框架。在执行期间,模型的输出或内部运算数可具有一个或多个未知维度或未知秩。当至少一个输出运算数具有一个未知维度或秩时,驱动程序必须返回大小动态变化的输出信息。
对于使用 NN HAL 1.1 或更低版本的驱动程序,在请求完成时仅返回错误状态。必须完全指定输入和输出运算数的维度,才能成功完成执行。内部运算数可具有一个或多个未知维度,但它们必须具有指定的秩。
对于涉及多个驱动程序的用户请求,框架负责预留中间内存,并按顺序执行对每个驱动程序的调用。
可以在同一个 @1.3::IPreparedModel 上并行发起多个请求。驱动程序可以并行执行这些请求,也可以按顺序执行。
框架可以要求驱动程序保留多个准备好的模型。例如,准备模型 m1,准备 m2,在 m1 上执行请求 r1,在 m2 上执行 r2,在 m1 上执行 r3,在 m2 上执行 r4,释放(如清理中所述)m1,以及释放 m2。
为了避免首次执行速度缓慢(这可能会导致糟糕的用户体验,比如第一帧卡顿),驱动程序应在编译阶段执行大部分初始化工作。首次执行时的初始化应仅限于过早执行会对系统运行状况产生负面影响的操作,例如预留较大的临时缓冲区或提高设备的时钟频率。只能准备有限数量的并发模型的驱动程序可能必须在首次执行时进行初始化。
在 Android 10 或更高版本中,如果快速连续地执行针对准备好的同一个模型的多个执行请求,客户端可以选择使用执行爆发对象在应用和驱动程序进程之间进行通信。如需了解详情,请参阅爆发执行和快速消息队列。
为了提高多次快速连续执行的性能,驱动程序可以保留临时缓冲区或提高时钟频率。建议创建一个监控线程,在经过固定的一段时间后未创建任何新请求时释放资源。
输出形状
对于有一个或多个输出运算数未指定所有维度的请求,驱动程序必须提供一个输出形状列表,其中包含执行后每个输出运算数的维度信息。如需详细了解维度,请参阅 OutputShape。
如果执行由于输出缓冲区大小不足而失败,驱动程序必须在输出形状列表中指出哪些输出运算数的缓冲区大小不足,并应尽可能报告更多维度信息,使用零表示未知的维度。
计时
在 Android 10 中,如果应用指定了在编译过程中使用的单个设备,则应用可以询问执行时间。如需了解详情,请参阅 MeasureTiming 和设备发现和分配。在这种情况下,使用 NN HAL 1.2 的驱动程序必须在执行请求时测量执行时长或报告 UINT64_MAX(表示无法提供时长)。驱动程序应尽可能减少测量执行时长导致的性能损失。
驱动程序在 Timing 结构中报告以下时长(以微秒为单位):
- 设备上的执行时间:不包括在主机处理器上运行的驱动程序中的执行时间。
- 驱动程序中的执行时间:包括设备上的执行时间。
这些时长必须包括暂停执行(例如当执行被其他任务抢占或等待某资源可用时)的时间。
如果未要求驱动程序测量执行时长,或者存在执行错误,驱动程序必须将时长报告为 UINT64_MAX。即使已要求驱动程序测量执行时长,也可以针对设备上的执行时间和/或驱动程序中的执行时间报告 UINT64_MAX。当驱动程序将两个时长报告为 UINT64_MAX 以外的值时,驱动程序中的执行时间必须等于或超过设备上的执行时间。
围栏执行
在 Android 11 中,NNAPI 允许执行等待出现 sync_fence 手柄列表,并选择性地返回 sync_fence 对象,系统会在执行完成时发出信号。这样可以降低小序列模型和流式传输用例的开销。此外,围栏执行还提高了与其他组件的互操作性效率,这些组件能够发出信号或等待 sync_fence。如需详细了解 sync_fence,请参阅同步框架。
在围栏执行中,框架调用 IPreparedModel::executeFenced 方法,以在准备好的模型上启动异步围栏执行,让同步围栏的向量等待。如果异步任务在调用返回之前完成,可以为 sync_fence 返回一个空句柄。此外,还必须返回一个 IFencedExecutionCallback 对象,以便框架能够查询错误状态和时长信息。
执行完成后,可以通过 IFencedExecutionCallback::getExecutionInfo 查询以下两个用于测量执行时长的时间值。
timingLaunched:从调用executeFenced时到executeFenced通知已返回syncFence时的时长。timingFenced:从向执行所等待的所有同步围栏发出信号时到executeFenced通知已返回syncFence时的时长。
控制流
对于搭载 Android 11 或更高版本的设备,NNAPI 包含两个控制流运算(IF 和 WHILE),它们使用其他模型作为参数,并有条件地执行这些运算 (IF) 或重复执行这些运算 (WHILE)。如需详细了解如何实现此运算,请参阅控制流。
服务质量
在 Android 11 中,NNAPI 允许应用指示模型的相对优先级、准备模型的预计最长时间以及完成执行的预计最长时间,从而改进服务质量 (QoS)。如需了解详情,请参阅服务质量。
清理
当应用使用完准备的模型后,框架会释放对 @1.3::IPreparedModel 对象的引用。当 IPreparedModel 对象不再被引用时,它会在创建它的驱动程序服务中自动销毁。此时,在驱动程序的析构函数实现中,可以重新获取模型专用的资源。如果驱动程序服务希望 IPreparedModel 对象在客户端不再需要时自动销毁,那么在通过 IPreparedModelCallback::notify_1_3 返回 IPreparedeModel 对象后,它不得保留对 IPreparedModel 对象的任何引用。
CPU 使用率
驱动程序应该使用 CPU 来设置计算。驱动程序不应使用 CPU 来执行图计算,因为这会导致框架无法正确分配工作。驱动程序应向框架报告其无法处理的部分,并让框架处理其余部分。
框架为所有 NNAPI 运算(供应商定义的运算除外)提供了 CPU 实现。如需了解详情,请参阅供应商扩展。
Android 10 中引入的运算(API 级别 29)仅具有参考 CPU 实现,以验证 CTS 和 VTS 测试是否正确。移动机器学习框架中包含的优化实现优于 NNAPI CPU 实现。
实用函数
NNAPI 代码库包含可供驱动程序服务使用的实用函数。
frameworks/ml/nn/common/include/Utils.h 文件包含各种实用函数,例如用于日志记录的函数以及在不同 NN HAL 版本之间进行转换的函数。
VLogging:
VLOG是 AndroidLOG的封装容器宏,只有在debug.nn.vlog属性中设置了相应标记时才会输出日志消息。必须在调用VLOG之前调用initVLogMask()。VLOG_IS_ON宏可用于检查当前是否启用了VLOG,如果不需要,可以跳过复杂的日志记录代码。属性值必须是以下某个值:- 一个空字符串,表示不进行日志记录。
- 令牌
1或all,表示要完成所有日志记录。 - 由空格、英文逗号或冒号分隔的标记列表,指示要完成的日志记录。标记是
compilation、cpuexe、driver、execution、manager和model。
compliantWithV1_*:如果 NN HAL 对象可以转换为相同类型的不同 HAL 版本而不丢失信息,就会返回true。例如,如果模型包含 NN HAL 1.1 或 NN HAL 1.2 中引入的运算类型,那么对V1_2::Model调用compliantWithV1_0就会返回false。convertToV1_*:将 NN HAL 对象从一个版本转换为另一个版本。如果转换导致信息丢失(即如果该类型的新版本无法完全表示该值),就会发出警告日志消息。功能:可以使用
nonExtensionOperandPerformance和update函数来帮助构建Capabilities::operandPerformance字段。查询类型的属性:
isExtensionOperandType、isExtensionOperationType、nonExtensionSizeOfData、nonExtensionOperandSizeOfData、nonExtensionOperandTypeIsScalar、tensorHasUnspecifiedDimensions。
frameworks/ml/nn/common/include/ValidateHal.h 文件包含根据对应 HAL 版本的规范来验证 NN HAL 对象是否有效的实用函数。
validate*:如果根据对应 HAL 版本的规范确认 NN HAL 对象有效,就会返回true。不会验证 OEM 类型和扩展类型。例如,如果模型包含引用不存在的运算数索引的运算,或者包含该 HAL 版本不支持的运算,validateModel就会返回false。
frameworks/ml/nn/common/include/Tracing.h 文件包含用于简化将系统跟踪信息添加到神经网络代码的宏。如需查看示例,请参阅驱动程序示例中的 NNTRACE_* 宏调用。
frameworks/ml/nn/common/include/GraphDump.h 文件包含一个以图形形式转储 Model 的内容以进行调试的实用函数。
graphDump:将 Graphviz (.dot) 格式的模型表示写入指定的信息流(如果提供)或 logcat(如果没有提供信息流)。
验证
若要测试 NNAPI 的实现,请使用 Android 框架中包含的 VTS 和 CTS 测试。VTS 直接执行驱动程序(不使用框架),而 CTS 通过框架间接执行驱动程序。它们会测试每个 API 方法并验证驱动程序支持的所有运算是否正常工作,并提供满足精度要求的结果。
CTS 和 VTS 对 NNAPI 的精度要求如下:
浮点:abs(expected - actual) <= atol + rtol * abs(expected);其中:
- 对于 fp32,atol = 1e-5f,rtol = 5.0f * 1.1920928955078125e-7
- 对于 fp16,atol = rtol = 5.0f * 0.0009765625f
量化:差一误差(除了
mobilenet_quantized,它是差三误差)布尔值:完全匹配
CTS 测试 NNAPI 的一种方式是生成固定的伪随机图,用于测试和比较每个驱动程序的执行结果与采用 NNAPI 参考实现的执行结果。对于使用 NN HAL 1.2 或更高版本的驱动程序,如果结果不符合精度标准,CTS 会报告错误并在 /data/local/tmp 下转储失败模型的规范文件以进行调试。如需详细了解精度标准,请参阅 TestRandomGraph.cpp 和 TestHarness.h。
模糊测试
模糊测试的目的是在被测代码中查找因意外输入等因素而造成的崩溃、断言、内存违规或一般未定义行为。对于 NNAPI 模糊测试,Android 使用基于 libFuzzer 的测试,这些测试使用以前的测试用例的代码行覆盖范围来生成新的随机输入,因此能够有效地进行模糊测试。例如,libFuzzer 更倾向于在新的代码行上运行的测试用例。这可以显著减少测试查找有问题的代码所需的时间。
如需执行模糊测试以验证您的驱动程序实现,请在 AOSP 中的 libneuralnetworks_driver_fuzzer 测试实用程序中修改 frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp 以包含您的驱动程序代码。如需详细了解 NNAPI 模糊测试,请参阅 frameworks/ml/nn/runtime/test/android_fuzzing/README.md。
安全
由于应用进程直接与驱动程序的进程通信,因此驱动程序必须验证所收到的调用的参数。此验证由 VTS 完成。验证代码位于 frameworks/ml/nn/common/include/ValidateHal.h 中。
驱动程序还应确保应用在使用同一设备时不会相互干扰。
Android 机器学习测试套件
Android 机器学习测试套件 (MLTS) 是 CTS 和 VTS 中包含的 NNAPI 基准,用于验证供应商设备上真实模型的准确性。该基准会评估延迟性和准确性,并针对相同的模型和数据集,将驱动程序的结果与使用 CPU 上运行的 TF Lite 的结果进行比较。这样可确保驱动程序的准确性不会低于 CPU 参考实现的准确性。
Android 平台开发者还使用 MLTS 评估驱动程序的延迟行和准确性。
可以在 AOSP 的两个项目中找到 NNAPI 基准:
platform/test/mlts/benchmark(基准应用)platform/test/mlts/models(模型和数据集)
模型和数据集
NNAPI 基准使用以下模型和数据集。
- MobileNetV1 float 和 u8 以不同大小进行量化,针对 Open Images Dataset v4 的一小部分(1500 张图片)运行。
- MobileNetV2 float 和 u8 以不同大小进行量化,针对 Open Images Dataset v4 的一小部分(1500 张图片)运行。
- 基于长短期记忆 (LSTM) 的文字转语音声学模型,针对 CMU Arctic 集合的一小部分运行。
- 基于 LSTM 的自动语音识别声学模型,针对 LibriSpeech 数据集的一小部分运行。
如需了解详情,请参阅 platform/test/mlts/models。
压力测试
Android 机器学习测试套件包含一系列崩溃测试,用于验证在高负荷使用情况下或客户端行为的极端情况下驱动程序的弹性。
所有崩溃测试都具有以下功能:
- 挂起检测:如果 NNAPI 客户端在测试期间挂起,测试就会失败,且失败原因为
HANG,然后测试套件将转到下一项测试。 - NNAPI 客户端崩溃检测:测试在客户端崩溃后仍然有效,测试失败时会显示失败原因
CRASH。 - 驱动程序崩溃检测:测试可以检测导致 NNAPI 调用失败的驱动程序崩溃。请注意,驱动程序进程中可能存在不会导致 NNAPI 故障也不会导致测试失败的崩溃。为了将此类故障也纳入检测范围,建议您对系统日志运行
tail命令以检测与驱动程序相关的错误或崩溃。 - 以所有可用加速器为目标:针对所有可用的驱动程序运行测试。
所有崩溃测试都可能得出以下四种结果:
SUCCESS:执行完成,没有出现错误。FAILURE:执行失败。此结果通常由测试模型时的失败所导致,表示驱动程序无法编译或执行模型。HANG:测试进程无响应。CRASH:测试进程崩溃。
如需详细了解压力测试并查看崩溃测试的完整列表,请参阅 platform/test/mlts/benchmark/README.txt。
使用 MLTS
如需使用 MLTS,请执行以下操作:
- 将目标设备连接到工作站,并确保其可以通过 adb 进行访问。如果连接了多个设备,请导出目标设备的
ANDROID_SERIAL环境变量。 cd到 Android 的顶级源代码目录。source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.sh在基准运行结束时,系统会将结果显示为 HTML 页面并传递给
xdg-open。
如需了解详情,请参阅 platform/test/mlts/benchmark/README.txt。
神经网络 HAL 版本
本部分将介绍 Android 和神经网络 HAL 版本中引入的更改。
Android 11
Android 11 引入了 NN HAL 1.3,其中包括以下主要更改。
- 支持 NNAPI 中的 8 位有符号量化。添加了
TENSOR_QUANT8_ASYMM_SIGNED运算数类型。使用 NN HAL 1.3 的驱动程序如果支持无符号量化运算,还必须支持这些运算的签名变体。在运行大多数量化运算的有符号和无符号版本时,驱动程序必须得出相同的结果,最大偏移量为 128。此项要求有五个例外:CAST、HASHTABLE_LOOKUP、LSH_PROJECTION、PAD_V2和QUANTIZED_16BIT_LSTM。QUANTIZED_16BIT_LSTM运算不支持有符号运算数,其他四个运算支持有符号量化但不要求结果相同。 - 支持围栏执行。在围栏执行中,框架调用
IPreparedModel::executeFenced方法,以在准备好的模型上启动异步围栏执行,让同步围栏的向量等待。如需了解详情,请参阅围栏执行。 - 支持控制流。添加了
IF和WHILE运算,它们使用其他模型作为参数,并有条件地执行这些运算 (IF) 或重复执行这些运算 (WHILE)。如需了解详情,请参阅控制流。 - 改进了服务质量 (QoS),因为应用可以指示模型的相对优先级、准备模型的预计最长时间以及完成执行的预计最长时间。如需了解详情,请参阅服务质量。
- 支持为驱动程序管理的缓冲区提供分配器接口的内存域。这样可以跨执行传递设备原生内存,从而抑制在同一驱动程序的连续执行之间进行不必要的数据复制和转换。如需了解详情,请参阅内存域。
Android 10
Android 10 引入了 NN HAL 1.2,其中包括以下主要更改。
Capabilities结构体包括所有数据类型(包括标量数据类型),并使用向量(而不是命名字段)表示非放宽的性能。getVersionString和getType方法允许框架检索设备类型 (DeviceType) 和版本信息。请参阅设备发现和分配。- 默认情况下,调用
executeSynchronously方法以同步执行。execute_1_2方法告知框架异步执行。请参阅执行部分。 executeSynchronously、execute_1_2和爆发执行的MeasureTiming参数指定驱动程序是否要测量执行时长。系统会在Timing结构中报告结果。请参阅时间部分。- 支持一个或多个输出运算数具有未知维度或秩的执行。请参阅输出形状部分。
- 支持供应商扩展,即供应商定义的运算和数据类型的集合。驱动程序通过
IDevice::getSupportedExtensions方法报告支持的扩展。请参阅供应商扩展。 - 爆发对象能够使用快速消息队列 (FMQ) 控制一组爆发执行,以在应用和驱动程序进程之间进行通信,从而缩短延迟。请参阅爆发执行和快速消息队列。
- 支持 AHardwareBuffer,以允许驱动程序在不复制数据的情况下完成执行。请参阅 AHardwareBuffer。
- 改进了对缓存编译工件的支持,以减少应用启动时编译所用的时间。请参阅编译缓存。
Android 10 引入了以下运算数类型和运算。
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 更新了很多现有运算。更新主要与以下方面有关:
- 支持 NCHW 内存布局
- 支持 softmax 和归一化运算中秩不为 4 的张量
- 支持扩张的卷积
- 支持在
ANEURALNETWORKS_CONCATENATION中包含混合量化的输入
下表列出了在 Android 10 中修改的运算。如需了解有关更改的完整详情,请参阅 NNAPI 参考文档中的 OperationCode。
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
Android 9 引入了 NN HAL 1.1,并且包括以下主要更改。
IDevice::prepareModel_1_1包含一个ExecutionPreference参数。驱动程序可以通过该参数了解应用是倾向于节约电量,还是将在快速连续调用中执行模型,从而调整其准备工作。- 新增了 9 个运算:
BATCH_TO_SPACE_ND、DIV、MEAN、PAD、SPACE_TO_BATCH_ND、SQUEEZE、STRIDED_SLICE、SUB、TRANSPOSE。 - 通过将
Model.relaxComputationFloat32toFloat16设为true,应用可以指定可使用 16 位浮点范围和/或精度运行 32 位浮点运算。Capabilities结构体具有附加字段relaxedFloat32toFloat16Performance,因此驱动程序可以向框架报告其放宽的性能。
Android 8.1
Android 8.1 发布了最初的神经网络 HAL (1.0)。如需了解详情,请参阅 /neuralnetworks/1.0/。