
Android 8.0 inclut des tests de performances de liaison et de hwbinder pour le débit et la latence. Bien que de nombreux scénarios existent pour détecter les problèmes de performances perceptibles, leur exécution peut prendre du temps et les résultats ne sont souvent disponibles qu'après l'intégration d'un système. L'utilisation des tests de performances fournis facilite les tests pendant le développement, permet de détecter plus tôt les problèmes graves et d'améliorer l'expérience utilisateur.
Les tests de performances incluent les quatre catégories suivantes:
- Débit du liaisonneur (disponible dans
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - Latence de liaison (disponible dans
frameworks/native/libs/binder/tests/schd-dbg.cpp) - Débit hwbinder (disponible dans
system/libhwbinder/vts/performance/Benchmark.cpp) - Latence hwbinder (disponible dans
system/libhwbinder/vts/performance/Latency.cpp)
À propos de binder et de hwbinder
Binder et hwbinder sont des infrastructures de communication inter-processus (IPC) Android qui partagent le même pilote Linux, mais présentent les différences qualitatives suivantes:
| Aspect | classeur | hwbinder |
|---|---|---|
| Objectif | Fournir un schéma d'IPC à usage général pour le framework | Communiquer avec le matériel |
| Propriété | Optimisé pour l'utilisation du framework Android | Faible latence avec un coût minimal |
| Modifier la stratégie de planification pour le premier plan/l'arrière-plan | Oui | Non |
| Transmission d'arguments | Utilise la sérialisation compatible avec l'objet Parcel | Utilise des tampons de dispersion et évite les frais généraux liés à la copie des données requises pour la sérialisation des parcelles. |
| Héritage de priorité | Non | Oui |
Processus de liaison et hwbinder
Un visualiseur systrace affiche les transactions comme suit:
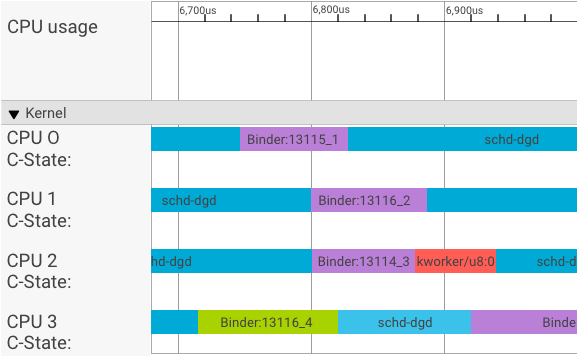
Dans l'exemple ci-dessus:
- Les quatre (4) processus schd-dbg sont des processus client.
- Les quatre (4) processus de liaison sont des processus de serveur (le nom commence par Binder et se termine par un numéro de séquence).
- Un processus client est toujours associé à un processus serveur, qui lui est dédié.
- Toutes les paires de processus client-serveur sont planifiées indépendamment par le noyau de manière simultanée.
Dans le processeur 1, le noyau de l'OS exécute le client pour envoyer la requête. Il utilise ensuite le même processeur dans la mesure du possible pour réveiller un processus de serveur, traiter la requête et rétablir le contexte une fois la requête terminée.
Débit par rapport à la latence
Dans une transaction parfaite, où le processus client et serveur bascule de manière transparente, les tests de débit et de latence ne produisent pas de messages sensiblement différents. Toutefois, lorsque le noyau de l'OS gère une demande d'interruption (IRQ) provenant du matériel, attend des verrous ou choisit simplement de ne pas gérer un message immédiatement, une bulle de latence peut se former.

Le test de débit génère un grand nombre de transactions avec différentes tailles de charge utile, ce qui fournit une bonne estimation du temps de transaction régulier (dans les scénarios les plus favorables) et du débit maximal que le liaisonneur peut atteindre.
En revanche, le test de latence n'effectue aucune action sur la charge utile pour minimiser la durée de la transaction régulière. Nous pouvons utiliser le temps de transaction pour estimer le coût du liant, créer des statistiques pour le pire des cas et calculer le ratio des transactions dont la latence respecte un délai spécifié.
Gérer les inversions de priorité
Une inversion de priorité se produit lorsqu'un thread de priorité supérieure attend logiquement un thread de priorité inférieure. Les applications en temps réel (RT) présentent un problème d'inversion de priorité:
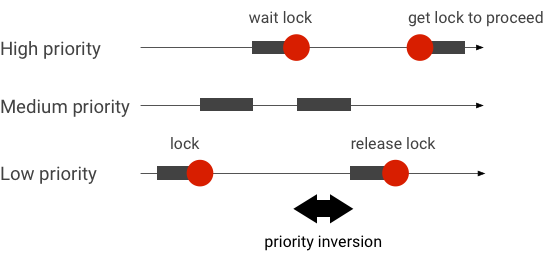
Lorsque vous utilisez la planification Linux Completely Fair Scheduler (CFS), un thread a toujours une chance d'être exécuté, même si d'autres threads ont une priorité plus élevée. Par conséquent, les applications avec planification CFS gèrent l'inversion de priorité comme un comportement attendu et non comme un problème. Toutefois, lorsque le framework Android a besoin d'une planification RT pour garantir le privilège des threads de priorité élevée, l'inversion de priorité doit être résolue.
Exemple d'inversion de priorité lors d'une transaction de liaison (le thread RT est bloqué de manière logique par d'autres threads CFS lorsqu'il attend qu'un thread de liaison soit traité):
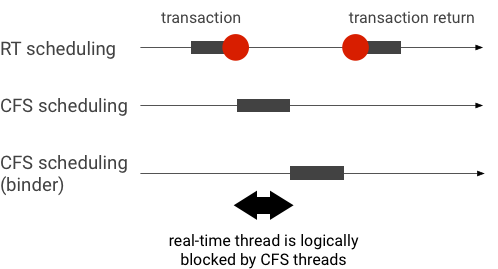
Pour éviter les blocages, vous pouvez utiliser l'héritage de priorité pour escalader temporairement le thread de liaison vers un thread RT lorsqu'il traite une requête d'un client RT. N'oubliez pas que la planification RT dispose de ressources limitées et doit être utilisée avec précaution. Dans un système avec n CPU, le nombre maximal de threads RT actuels est également de n. Des threads RT supplémentaires peuvent devoir attendre (et manquer ainsi leurs échéances) si tous les CPU sont occupés par d'autres threads RT.
Pour résoudre toutes les inversions de priorité possibles, vous pouvez utiliser l'héritage de priorité pour le liaison et le hwbinder. Toutefois, comme le liaisonneur est largement utilisé dans le système, l'activation de l'héritage de priorité pour les transactions de liaisonneur peut inonder le système de plus de threads RT qu'il ne peut en traiter.
Exécuter des tests de débit
Le test de débit est exécuté sur le débit des transactions binder/hwbinder. Dans un système qui n'est pas surchargé, les bulles de latence sont rares et leur impact peut être éliminé tant que le nombre d'itérations est suffisamment élevé.
- Le test de débit du liaison se trouve dans
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Le test de débit hwbinder se trouve dans
system/libhwbinder/vts/performance/Benchmark.cpp.
Résultats des tests
Exemples de résultats de test de débit pour les transactions utilisant différentes tailles de charge utile:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Temps indique le délai aller-retour mesuré en temps réel.
- CPU indique le temps cumulé lorsque les processeurs sont planifiés pour le test.
- Itérations : indique le nombre de fois où la fonction de test a été exécutée.
Par exemple, pour une charge utile de 8 octets:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… le débit maximal que le liaisonneur peut atteindre est calculé comme suit:
Débit maximal avec une charge utile de 8 octets = (8 * 21 296)/69 974 ~= 2,423 b/ns ~= 2,268 Go/s
Options de test
Pour obtenir des résultats au format .json, exécutez le test avec l'argument --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Exécuter des tests de latence
Le test de latence mesure le temps nécessaire au client pour commencer à initialiser la transaction, passer au processus de serveur pour la gestion et recevoir le résultat. Le test recherche également des comportements de planificateur connus qui peuvent avoir un impact négatif sur la latence des transactions, comme un planificateur qui n'est pas compatible avec l'héritage de priorité ou qui n'honore pas l'indicateur de synchronisation.
- Le test de latence du liaisonneur se trouve dans
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Le test de latence hwbinder se trouve dans
system/libhwbinder/vts/performance/Latency.cpp.
Résultats des tests
Les résultats (au format .json) affichent des statistiques sur la latence moyenne/meilleure/la plus mauvaise et le nombre de délais manqués.
Options de test
Les tests de latence acceptent les options suivantes:
| Commande | Description |
|---|---|
-i value |
Spécifiez le nombre d'itérations. |
-pair value |
Spécifiez le nombre de paires de processus. |
-deadline_us 2500 |
Spécifiez l'échéance en heures. |
-v |
Obtenez une sortie détaillée (débogage). |
-trace |
Arrêtez la trace lorsqu'une échéance est atteinte. |
Les sections suivantes décrivent chaque option, l'utilisation et des exemples de résultats.
Spécifier les itérations
Exemple avec un grand nombre d'itérations et la sortie détaillée désactivée:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Les résultats de ces tests indiquent ce qui suit:
"pair":3- Crée une paire client-serveur.
"iterations": 5000- Inclut 5 000 itérations.
"deadline_us":2500- L'échéance est de 2 500 µs (2,5 ms). La plupart des transactions devraient respecter cette valeur.
"I": 10000- Une seule itération de test comprend deux (2) transactions :
- Une transaction par priorité normale (
CFS other) - Une transaction par priorité en temps réel (
RT-fifo)
- Une transaction par priorité normale (
"S": 9352- 9 352 transactions sont synchronisées sur le même processeur.
"R": 0.9352- Indique le ratio auquel le client et le serveur sont synchronisés dans le même processeur.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Cas moyen (
avg), pire (wst) et meilleur (bst) pour toutes les transactions émises par un appelant de priorité normale. Deux transactionsmissla date limite, ce qui fait que le ratio de respect (meetR) est de 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Semblable à
other_ms, mais pour les transactions émises par le client avec une prioritért_fifo. Il est probable (mais pas obligatoire) quefifo_msobtienne un meilleur résultat queother_ms, avec des valeursavgetwstplus faibles et unemeetRplus élevée (la différence peut être encore plus importante avec la charge en arrière-plan).
Remarque:La charge en arrière-plan peut avoir un impact sur le résultat du débit et le tuple other_ms dans le test de latence. Seul fifo_ms peut afficher des résultats similaires tant que la charge en arrière-plan a une priorité inférieure à RT-fifo.
Spécifier les valeurs des paires
Chaque processus client est associé à un processus serveur dédié au client, et chaque paire peut être planifiée indépendamment sur n'importe quel processeur. Toutefois, la migration du processeur ne doit pas se produire pendant une transaction tant que l'indicateur SYNC est honor.
Assurez-vous que le système n'est pas surchargé. Bien que la latence élevée dans un système surchargé soit attendue, les résultats des tests pour un système surchargé ne fournissent pas d'informations utiles. Pour tester un système à pression plus élevée, utilisez -pair
#cpu-1 (ou -pair #cpu avec précaution). Les tests à l'aide de -pair n avec n > #cpu surchargent le système et génèrent des informations inutiles.
Spécifier des valeurs de délai
Après des tests approfondis sur les scénarios utilisateur (exécution du test de latence sur un produit qualifié), nous avons déterminé que 2,5 ms était la limite à respecter. Pour les nouvelles applications présentant des exigences plus élevées (par exemple, 1 000 photos/seconde), cette valeur d'échéance changera.
Spécifier une sortie détaillée
L'utilisation de l'option -v affiche une sortie détaillée. Exemple :
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Le thread de service est créé avec une priorité
SCHED_OTHERet exécuté dansCPU:1avecpid 8674. - La première transaction est ensuite lancée par un
fifo-caller. Pour traiter cette transaction, le hwbinder met à niveau la priorité du serveur (pid: 8674 tid: 8676) à 99 et le marque également d'une classe de planification temporaire (affichée sous la forme???). Le planificateur met ensuite le processus serveur enCPU:0pour l'exécuter et le synchronise avec le même processeur avec son client. - L'appelant de la deuxième transaction a une priorité
SCHED_OTHER. Le serveur se rétrograde et traite l'appelant avec une prioritéSCHED_OTHER.
Utiliser la trace pour le débogage
Vous pouvez spécifier l'option -trace pour déboguer les problèmes de latence. Lorsqu'il est utilisé, le test de latence arrête l'enregistrement du journal de trace au moment où une mauvaise latence est détectée. Exemple :
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Les composants suivants peuvent avoir une incidence sur la latence:
- Mode de compilation Android Le mode Eng est généralement plus lent que le mode userdebug.
- Framework Comment le service de framework utilise-t-il
ioctlpour configurer le liaisonneur ? - Pilote de liaison Le pilote est-il compatible avec le verrouillage précis ? Contient-il tous les correctifs de performances ?
- Version du noyau Plus le noyau est performant en temps réel, meilleurs sont les résultats.
- Configuration du kernel La configuration du kernel contient-elle des configurations
DEBUGtelles queDEBUG_PREEMPTetDEBUG_SPIN_LOCK? - Planificateur de noyau. Le noyau dispose-t-il d'un planificateur EAS (Energy-Aware Scheduler) ou HMP (Heterogeneous Multi-Processing) ? Des pilotes de kernel (pilote
cpu-freq, pilotecpu-idle,cpu-hotplug, etc.) ont-ils un impact sur le planificateur ?