
O Android oferece uma implementação de referência de todos os componentes necessários para implementar o Framework de virtualização do Android. No momento, essa implementação está limitada ao ARM64. Nesta página, explicamos a arquitetura do framework.
Contexto
A arquitetura Arm permite até quatro níveis de exceção, sendo o nível 0 (EL0) o menos privilegiado e o nível 3 (EL3) o mais privilegiado. A maior parte da base de código do Android (todos os componentes do espaço do usuário) é executada no EL0. O restante do que é comumente chamado de "Android" é o kernel do Linux, que é executado no EL1.
A camada EL2 permite a introdução de um hipervisor que isola memória e dispositivos em pVMs individuais no EL1/EL0, com fortes garantias de confidencialidade e integridade.
Hipervisor
A máquina virtual baseada em kernel protegida (pKVM) é baseada no hipervisor KVM Linux, que foi estendido com a capacidade de restringir o acesso aos payloads executados em máquinas virtuais convidadas marcadas como "protegidas" no momento da criação.
O KVM/arm64 oferece suporte a diferentes modos de execução, dependendo da disponibilidade de
determinados recursos da CPU, ou seja, as extensões de host de virtualização (VHE, na sigla em inglês) (ARMv8.1
e versões mais recentes). Em um desses modos, conhecido como modo não VHE, o código do hipervisor é dividido da imagem do kernel durante a inicialização e instalado no EL2, enquanto o kernel é executado no EL1. Embora faça parte da base de código do Linux, o componente EL2 do KVM é pequeno e responsável pela troca entre vários EL1s. O componente do hipervisor é compilado com
Linux, mas reside em uma seção de memória separada e dedicada da imagem
vmlinux. A pKVM aproveita esse design estendendo o código do hipervisor com novos
recursos que permitem restringir o kernel do host Android e o espaço
do usuário, além de limitar o acesso do host à memória do convidado e ao hipervisor.
Módulos de fornecedor pKVM
Um módulo de fornecedor pKVM é um módulo específico de hardware que contém funcionalidades específicas do dispositivo, como drivers da unidade de gerenciamento de memória de entrada/saída (IOMMU). Com eles, é possível transferir recursos de segurança que exigem acesso de nível de exceção 2 (EL2) para o pKVM.
Para saber como implementar e carregar um módulo de fornecedor pKVM, consulte Implementar um módulo de fornecedor pKVM.
Procedimento de inicialização
A figura a seguir descreve o procedimento de inicialização do pKVM:
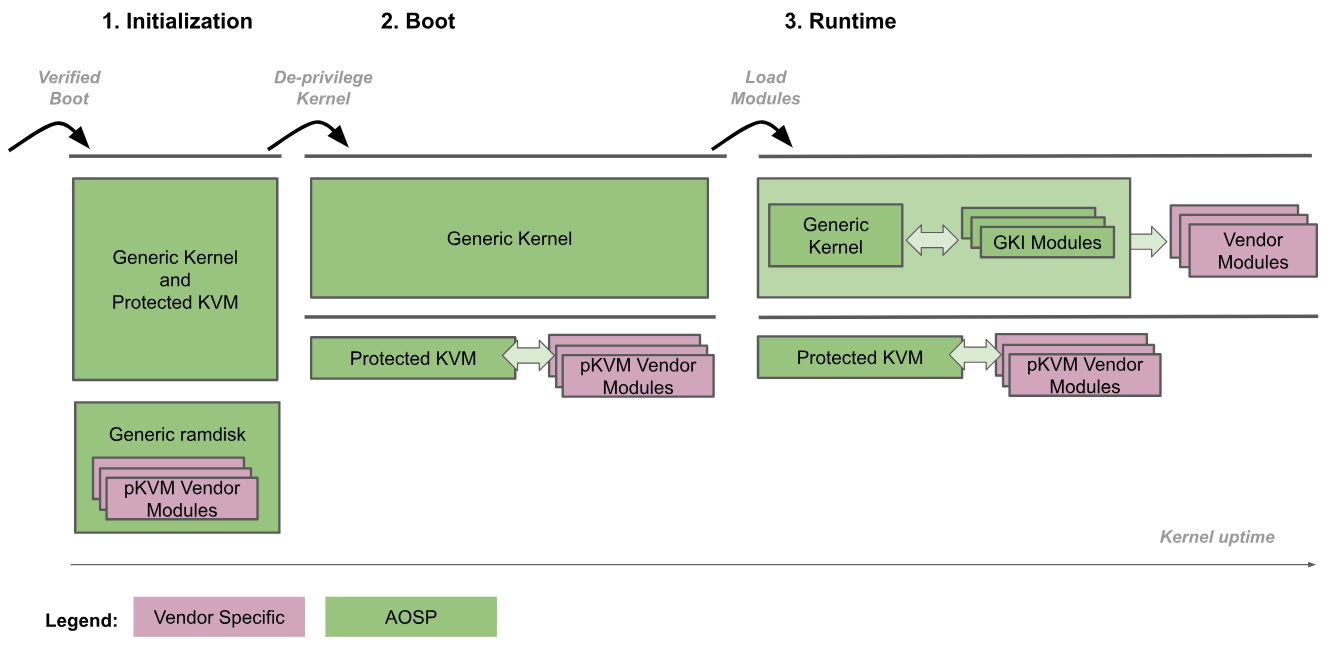
- Inicialização:o carregador de inicialização entra no kernel genérico em EL2. O código do kernel confiável nos níveis EL2 e EL1 inicializa o pKVM e os módulos dele. Durante essa fase, o EL1 é confiável para o EL2, então nenhum código não confiável é executado.
- Kernel sem privilégios:o kernel genérico detecta que está sendo executado no EL2 e remove os privilégios para o EL1. O pKVM e os módulos dele continuam sendo executados no EL2.
- Tempo de execução: o kernel genérico continua a inicializar normalmente, carregando todos os drivers de dispositivo necessários até chegar ao espaço do usuário. Nesse momento, o pKVM está no lugar e processa as tabelas de páginas de estágio 2.
O procedimento de inicialização confia no carregador de inicialização para verificar e manter a integridade da imagem do kernel para a fase de inicialização. Depois que o kernel é desprivilegiado, ele não é mais considerado confiável pelo hipervisor, que passa a ser responsável por se proteger mesmo que o kernel esteja comprometido.
Ter o kernel do Android e o hipervisor na mesma imagem binária permite uma interface de comunicação muito bem acoplada entre eles. Esse acoplamento estreito garante atualizações atômicas dos dois componentes, o que evita a necessidade de manter a interface entre eles estável e oferece muita flexibilidade sem comprometer a capacidade de manutenção a longo prazo. O acoplamento estreito também permite otimizações de desempenho quando os dois componentes podem cooperar sem afetar as garantias de segurança fornecidas pelo hipervisor.
Além disso, a adoção da GKI no ecossistema Android permite automaticamente que o hipervisor pKVM seja implantado em dispositivos Android no mesmo binário do kernel.
Proteção de acesso à memória da CPU
A arquitetura Arm especifica uma unidade de gerenciamento de memória (MMU) dividida em dois estágios independentes, que podem ser usados para implementar a conversão de endereços e o controle de acesso a diferentes partes da memória. A MMU de estágio 1 é controlada pelo EL1 e permite um primeiro nível de tradução de endereços. A MMU de estágio 1 é usada pelo Linux para gerenciar o espaço de endereço virtual fornecido a cada processo do espaço do usuário e ao próprio espaço de endereço virtual.
A MMU de estágio 2 é controlada pelo EL2 e permite a aplicação de uma segunda conversão de endereço no endereço de saída da MMU de estágio 1, resultando em um endereço físico (PA). A tradução da etapa 2 pode ser usada por hipervisores para controlar e traduzir acessos à memória de todas as VMs convidadas. Como mostrado na Figura 2, quando os dois estágios de tradução estão ativados, o endereço de saída do estágio 1 é chamado de endereço físico intermediário (IPA, na sigla em inglês). Observação: o endereço virtual (VA) é traduzido para um IPA e depois para um PA.
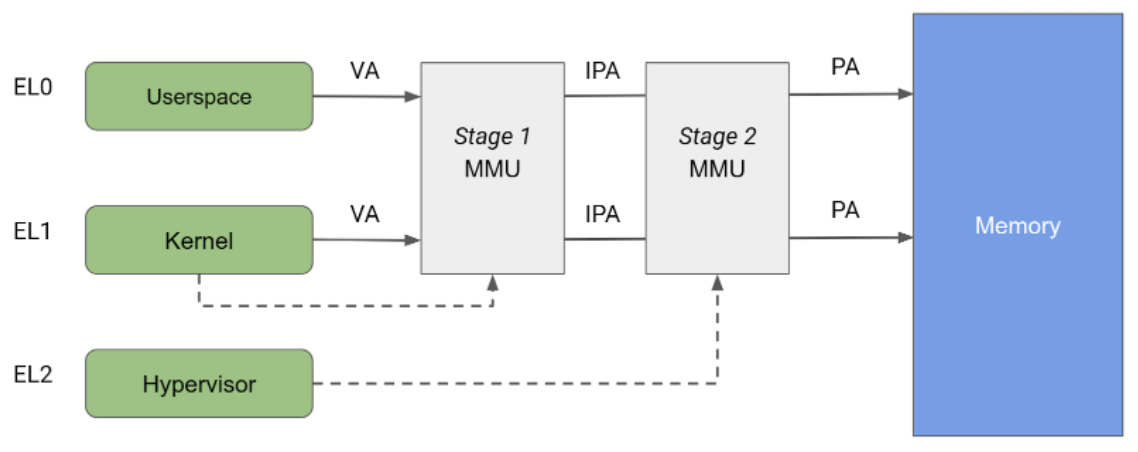
Historicamente, o KVM é executado com a tradução de estágio 2 ativada ao executar convidados e com o estágio 2 desativado ao executar o kernel do Linux do host. Essa arquitetura permite que os acessos à memória da MMU de estágio 1 do host passem pela MMU de estágio 2, permitindo acesso irrestrito do host às páginas de memória do convidado. Por outro lado, o pKVM permite a proteção de estágio 2 mesmo no contexto do host e coloca o hipervisor no comando da proteção das páginas de memória do convidado em vez do host.
O KVM usa a tradução de endereços na fase 2 para implementar mapeamentos complexos de IPA/PA para convidados, o que cria a ilusão de memória contígua para convidados, apesar da fragmentação física. No entanto, o uso da MMU da fase 2 para o host é restrito apenas ao controle de acesso. O host da etapa 2 é mapeado por identidade, garantindo que a memória contígua no espaço IPA do host seja contígua no espaço PA. Essa arquitetura permite o uso de mapeamentos grandes na tabela de páginas e, consequentemente, reduz a pressão no buffer de pesquisa de tradução (TLB, na sigla em inglês). Como um mapeamento de identidade pode ser indexado pelo PA, o estágio 2 do host também é usado para rastrear a propriedade da página diretamente na tabela de páginas.
Proteção de acesso direto à memória (DMA)
Como descrito anteriormente, a remoção do mapeamento de páginas convidadas do host Linux nas tabelas de páginas da CPU é uma etapa necessária, mas insuficiente, para proteger a memória do convidado. O pKVM também precisa proteger contra acessos à memória feitos por dispositivos compatíveis com DMA sob o controle do kernel host e contra a possibilidade de um ataque de DMA iniciado por um host malicioso. Para evitar que um dispositivo desse tipo acesse a memória do convidado, o pKVM exige hardware de unidade de gerenciamento de memória de entrada/saída (IOMMU) para cada dispositivo compatível com DMA no sistema, conforme mostrado na figura 3.
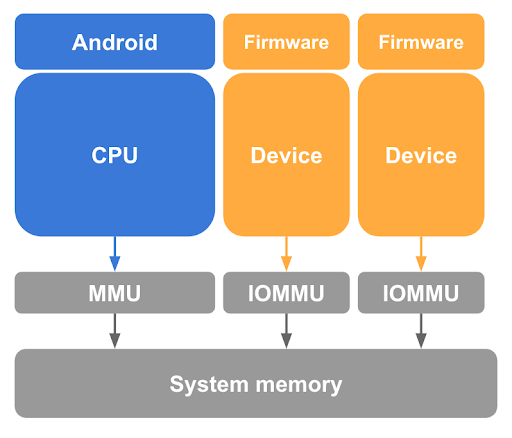
No mínimo, o hardware da IOMMU oferece os meios de conceder e revogar acesso de leitura/gravação de um dispositivo à memória física com granularidade de página. No entanto, esse hardware de IOMMU limita o uso de dispositivos em pVMs, já que eles presumem um estágio 2 mapeado por identidade.
Para garantir o isolamento entre máquinas virtuais, as transações de memória geradas em nome de diferentes entidades precisam ser diferenciadas pela IOMMU para que o conjunto apropriado de tabelas de páginas possa ser usado para a tradução.
Além disso, reduzir a quantidade de código específico do SoC no EL2 é uma estratégia fundamental para diminuir a base de computação confiável (TCB, na sigla em inglês) geral do pKVM e vai contra a inclusão de drivers de IOMMU no hipervisor. Para reduzir esse problema, o host no EL1 é responsável por tarefas auxiliares de gerenciamento de IOMMU, como gerenciamento de energia, inicialização e, quando apropriado, tratamento de interrupções.
No entanto, colocar o host no controle do estado do dispositivo impõe requisitos adicionais à interface de programação do hardware IOMMU para garantir que as verificações de permissão não possam ser ignoradas por outros meios, por exemplo, seguindo uma redefinição do dispositivo.
Uma IOMMU padrão e bem compatível para dispositivos Arm que possibilita isolamento e atribuição direta é a arquitetura da unidade de gerenciamento de memória do sistema (SMMU) Arm. Essa arquitetura é a solução de referência recomendada.
Propriedade da memória
No momento da inicialização, toda a memória que não é do hipervisor é considerada de propriedade do host e é rastreada como tal pelo hipervisor. Quando uma pVM é gerada, o host doa páginas de memória para permitir que ela seja inicializada, e o hipervisor faz a transição da propriedade dessas páginas do host para a pVM. Assim, o hipervisor implementa restrições de controle de acesso na tabela de páginas de estágio 2 do host para impedir que ele acesse as páginas novamente, oferecendo confidencialidade ao convidado.
A comunicação entre o host e os convidados é possível graças ao compartilhamento controlado de memória entre eles. Os convidados podem compartilhar algumas das páginas com o host usando uma hiperchamada, que instrui o hipervisor a remapear essas páginas na tabela de páginas de estágio 2 do host. Da mesma forma, a comunicação do host com a TrustZone é possível graças a operações de compartilhamento e/ou empréstimo de memória, todas monitoradas e controladas de perto pelo pKVM usando a especificação do Firmware Framework for Arm (FF-A).
Como os requisitos de memória de uma pVM podem mudar com o tempo, uma hipercaminhada é fornecida, permitindo que a propriedade de páginas específicas pertencentes ao chamador seja devolvida ao host. Na prática, essa hipercaminhada é usada com o protocolo de balão virtio para permitir que o VMM solicite memória de volta da pVM e que a pVM notifique o VMM sobre páginas liberadas de maneira controlada.
O hipervisor é responsável por rastrear a propriedade de todas as páginas de memória no sistema e se elas estão sendo compartilhadas ou emprestadas a outras entidades. A maior parte desse rastreamento de estado é feita usando metadados anexados às tabelas de páginas de estágio 2 do host e dos convidados, usando bits reservados nas entradas da tabela de páginas (PTEs) que, como o nome sugere, são reservados para uso de software.
O host precisa garantir que não tentará acessar páginas que foram tornadas inacessíveis pelo hipervisor. Um acesso ilegal ao host faz com que o hipervisor injete uma exceção síncrona no host, o que pode resultar em uma tarefa do espaço do usuário responsável recebendo um sinal SEGV ou em uma falha no kernel do host. Para evitar acessos acidentais, as páginas doadas aos convidados não podem ser trocadas ou mescladas pelo kernel do host.
Processamento de interrupções e timers
As interrupções são uma parte essencial da maneira como um convidado interage com os dispositivos e para a comunicação entre CPUs, em que as interrupções entre processadores (IPIs) são o principal mecanismo de comunicação. O modelo KVM delega todo o gerenciamento de interrupções virtuais ao host no EL1, que, para essa finalidade, se comporta como uma parte não confiável do hipervisor.
O pKVM oferece uma emulação completa do controlador de interrupção genérico versão 3 (GICv3) com base no código KVM atual. O timer e as IPIs são processados como parte desse código de emulação não confiável.
Suporte ao GICv3
A interface entre EL1 e EL2 precisa garantir que o estado completo de interrupção esteja visível para o host EL1, incluindo cópias dos registros do hipervisor relacionados a interrupções. Essa visibilidade geralmente é alcançada usando regiões de memória compartilhada, uma por CPU virtual (vCPU).
O código de suporte do tempo de execução do registro do sistema pode ser simplificado para oferecer suporte apenas ao registro de interrupção gerada por software (SGIR, na sigla em inglês) e ao registro de captura de interrupção de desativação (DIR, na sigla em inglês). A arquitetura exige que esses registros sempre façam trapping para EL2, enquanto os outros traps até agora só foram úteis para mitigar erratas. Todo o resto está sendo processado no hardware.
No lado do MMIO, tudo é emulado no EL1, reutilizando toda a infraestrutura atual no KVM. Por fim, o Wait for Interrupt (WFI) é sempre transmitido para o EL1, porque é uma das primitivas de programação básicas usadas pelo KVM.
Suporte para timer
O valor do comparador para o timer virtual precisa ser exposto ao EL1 em cada WFI de captura para que o EL1 possa injetar interrupções de timer enquanto a vCPU está bloqueada. O timer físico é totalmente emulado, e todas as interrupções são retransmitidas para o EL1.
Processamento de MMIO
Para se comunicar com o monitor de máquina virtual (VMM) e realizar a emulação de GIC, os traps de MMIO precisam ser retransmitidos ao host em EL1 para triagem adicional. O pKVM requer o seguinte:
- IPA e tamanho do acesso
- Dados em caso de gravação
- Endianness da CPU no ponto de captura
Além disso, traps com um registro de uso geral (GPR) como origem/destino são transmitidas usando um pseudorregistrador de transferência abstrata.
Interfaces de convidados
Um convidado pode se comunicar com um convidado protegido usando uma combinação de hiperchamadas e acesso à memória em regiões isoladas. As hiperchamadas são expostas de acordo com o padrão SMCCC (link em inglês), com um intervalo reservado para uma alocação de fornecedor pela KVM. As seguintes hiperchamadas são de importância especial para convidados do pKVM.
Hiperchamadas genéricas
- O PSCI oferece um mecanismo padrão para o convidado controlar o ciclo de vida das vCPUs, incluindo ativação, desativação e desligamento do sistema.
- O TRNG fornece um mecanismo padrão para que o convidado solicite entropia do pKVM, que retransmite a chamada para o EL3. Esse mecanismo é particularmente útil quando não é possível confiar no host para virtualizar um gerador de números aleatórios (RNG) de hardware.
Hiperchamadas pKVM
- Compartilhamento de memória com o host. Inicialmente, toda a memória do visitante fica inacessível ao host, mas o acesso do host é necessário para a comunicação de memória compartilhada e para dispositivos paravirtualizados que dependem de buffers compartilhados. As hiperchamadas para compartilhar e remover o compartilhamento de páginas com o host permitem que o convidado decida exatamente quais partes da memória são disponibilizadas para o restante do Android sem a necessidade de um handshake.
- Desistência de memória para o host. Toda a memória do convidado geralmente pertence a ele até ser destruída. Esse estado pode ser inadequado para VMs de longa duração com requisitos de memória que variam ao longo do tempo. A hipercaminhada
relinquishpermite que um convidado transfira explicitamente a propriedade das páginas de volta para o host sem exigir o encerramento do convidado. - Interceptação de acesso à memória do host. Tradicionalmente, se um convidado do KVM acessar um endereço que não corresponde a uma região de memória válida, a linha de execução da vCPU será encerrada no host, e o acesso será usado normalmente para MMIO e emulado pelo VMM no espaço do usuário. Para facilitar esse processamento, o pKVM precisa anunciar detalhes sobre a instrução com falha, como endereço, parâmetros de registro e, possivelmente, o conteúdo de volta ao host. Isso pode expor dados sensíveis de um convidado protegido sem intenção se a interceptação não for prevista. O pKVM resolve esse problema tratando essas falhas como fatais, a menos que o convidado tenha emitido uma hiperchamada para identificar o intervalo de IPA com falha como um em que os acessos são permitidos para interceptar de volta ao host. Essa solução é chamada de proteção de MMIO.
Dispositivo de E/S virtual (virtio)
O Virtio é um padrão popular, portátil e desenvolvido para implementar e interagir com dispositivos paravirtualizados. A maioria dos dispositivos expostos a hóspedes protegidos é implementada usando virtio. O Virtio também é a base da implementação do vsock usada para comunicação entre um convidado protegido e o restante do Android.
Os dispositivos Virtio geralmente são implementados no espaço do usuário do host pelo VMM, que intercepta acessos de memória presos do convidado à interface MMIO do dispositivo Virtio e emula o comportamento esperado. O acesso à MMIO é relativamente caro porque cada acesso ao dispositivo exige uma viagem de ida e volta ao VMM e vice-versa. Portanto, a maior parte da transferência de dados real entre o dispositivo e o convidado ocorre usando um conjunto de virtqueues na memória. Uma das principais premissas do virtio é que o host pode acessar a memória do convidado de maneira arbitrária. Essa proposição é evidente no design da virtqueue, que pode conter ponteiros para buffers no convidado que a emulação de dispositivo pretende acessar diretamente.
Embora as hiperchamadas de compartilhamento de memória descritas anteriormente possam ser usadas para compartilhar buffers de dados virtio do convidado para o host, esse compartilhamento é necessariamente realizado na granularidade da página e pode acabar expondo mais dados do que o necessário se o tamanho do buffer for menor que o de uma página. Em vez disso, o convidado é configurado para alocar as virtqueues e os buffers de dados correspondentes de uma janela fixa de memória compartilhada, com os dados sendo copiados (repassados) para e da janela conforme necessário.
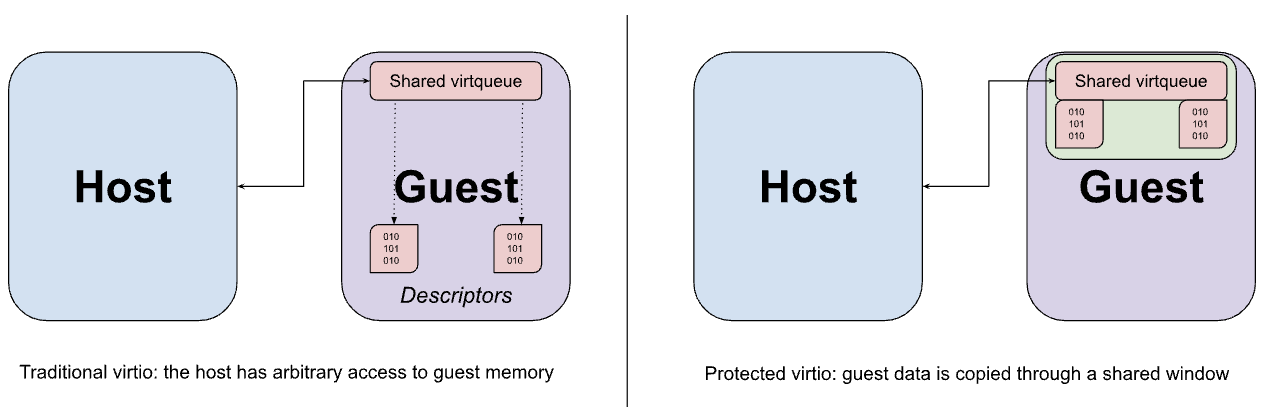
Interação com a TrustZone
Embora os convidados não possam interagir diretamente com a TrustZone, o host ainda precisa poder emitir chamadas SMC para o mundo seguro. Essas chamadas podem especificar buffers de memória endereçados fisicamente que são inacessíveis ao host. Como o software seguro geralmente não tem conhecimento da acessibilidade do buffer, um host malicioso pode usar esse buffer para realizar um ataque de confused deputy (análogo a um ataque de DMA). Para evitar esses ataques, o pKVM intercepta todas as chamadas de SMC do host para EL2 e atua como um proxy entre o host e o monitor seguro no EL3.
As chamadas PSCI do host são encaminhadas para o firmware EL3 com modificações mínimas. Especificamente, o ponto de entrada de uma CPU que está entrando on-line ou retomando da suspensão é reescrito para que a tabela de páginas de estágio 2 seja instalada no EL2 antes de retornar ao host no EL1. Durante a inicialização, essa proteção é imposta pelo pKVM.
Essa arquitetura depende de um SoC compatível com PSCI, de preferência usando uma versão atualizada do TF-A como firmware EL3.
O Firmware Framework for Arm (FF-A) padroniza as interações entre os mundos normal e seguro, principalmente na presença de um hipervisor seguro. Uma parte importante da especificação define um mecanismo para compartilhar memória com o mundo seguro, usando um formato de mensagem comum e um modelo de permissões bem definido para as páginas subjacentes. O pKVM encaminha mensagens FF-A para garantir que o host não esteja tentando compartilhar memória com o lado seguro para o qual não tem permissões suficientes.
Essa arquitetura depende do software do mundo seguro para aplicar o modelo de acesso à memória. Assim, os apps confiáveis e qualquer outro software em execução no mundo seguro só podem acessar a memória se ela for de propriedade exclusiva do mundo seguro ou tiver sido compartilhada explicitamente com ele usando o FF-A. Em um sistema com S-EL2, a aplicação do modelo de acesso à memória deve ser feita por um núcleo do gerenciador de partições seguras (SPMC), como o Hafnium, que mantém tabelas de páginas de estágio 2 para o mundo seguro. Em um sistema sem S-EL2, o TEE pode aplicar um modelo de acesso à memória usando as tabelas de páginas de estágio 1.
Se a chamada SMC para EL2 não for uma chamada PSCI ou uma mensagem definida pelo FF-A, as SMCs não processadas serão encaminhadas para EL3. A premissa é que o firmware seguro (necessariamente confiável) pode processar SMCs não processadas com segurança porque ele entende as precauções necessárias para manter o isolamento da pVM.
Monitor da máquina virtual
O crosvm é um monitor da máquina virtual (VMM) que executa máquinas virtuais pela interface KVM do Linux. O que torna o crosvm único é o foco na segurança com o uso da linguagem de programação Rust e um sandbox em torno de dispositivos virtuais para proteger o kernel do host. Para mais informações sobre o crosvm, consulte a documentação oficial aqui.
Descritores de arquivos e ioctls
O KVM expõe o dispositivo de caractere /dev/kvm ao espaço do usuário com ioctls que compõem a API KVM. Os ioctls pertencem às seguintes categorias:
- As ioctls do sistema consultam e definem atributos globais que afetam todo o subsistema KVM e criam pVMs.
- Os ioctls de VM consultam e definem atributos que criam CPUs virtuais (vCPUs) e dispositivos, afetando uma pVM inteira, como o layout da memória e o número de CPUs virtuais (vCPUs) e dispositivos.
- Os ioctls de vCPU consultam e definem atributos que controlam a operação de uma única CPU virtual.
- Os ioctls do dispositivo consultam e definem atributos que controlam a operação de um único dispositivo virtual.
Cada processo do crosvm executa exatamente uma instância de uma máquina virtual. Esse processo usa o ioctl do sistema KVM_CREATE_VM para criar um descritor de arquivo de VM que pode ser usado para emitir ioctls de pVM. Um ioctl KVM_CREATE_VCPU ou KVM_CREATE_DEVICE
em um FD de VM cria uma vCPU/dispositivo e retorna um descritor de arquivo que aponta para o
novo recurso. Os ioctls em um FD de vCPU ou dispositivo podem ser usados para controlar o dispositivo
criado usando o ioctl em um FD de VM. Para vCPUs, isso inclui a importante tarefa de executar código convidado.
Internamente, o crosvm registra os descritores de arquivo da VM com o kernel usando
a interface epoll acionada por borda. Em seguida, o kernel notifica o crosvm sempre que
há um novo evento pendente em qualquer um dos descritores de arquivo.
O pKVM adiciona um novo recurso, KVM_CAP_ARM_PROTECTED_VM, que pode ser usado para
receber informações sobre o ambiente pVM e configurar o modo protegido para uma VM.
O crosvm usa isso durante a criação da pVM se a flag --protected-vm for transmitida,
para consultar e reservar a quantidade adequada de memória para
firmware da pVM e, em seguida, ativar o modo protegido.
Alocação de memória
Uma das principais responsabilidades de um VMM é alocar a memória da VM e gerenciar o layout dela. O crosvm gera um layout de memória fixo descrito na tabela abaixo.
| FDT no modo normal | PHYS_MEMORY_END - 0x200000
|
| Lib espaço | ...
|
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Kernel | 0x80080000
|
| Carregador de inicialização | 0x80200000
|
| FDT no modo BIOS | 0x80000000
|
| Base da memória física | 0x80000000
|
| firmware da pVM | 0x7FE00000
|
| Memória do dispositivo | 0x10000 - 0x40000000
|
A memória física é alocada com mmap e doada à VM para preencher as regiões de memória, chamadas de memslots, com o ioctl KVM_SET_USER_MEMORY_REGION. Portanto, toda a memória da pVM convidada é atribuída à instância do crosvm que a gerencia e pode resultar na interrupção do processo (encerrando a VM) se o host começar a ficar sem memória livre. Quando uma VM é interrompida, a memória é apagada automaticamente pelo hipervisor e retornada ao kernel do host.
No KVM comum, o VMM mantém o acesso a toda a memória do convidado. Com o pKVM, a memória do convidado é desalocada do espaço de endereço físico do host quando é doada ao convidado. A única exceção é a memória compartilhada explicitamente pelo convidado, como para dispositivos virtio.
As regiões de MMIO no espaço de endereço do convidado não são mapeadas. O acesso a essas regiões pelo convidado é interceptado e resulta em um evento de E/S no FD da VM. Esse mecanismo é usado para implementar dispositivos virtuais. No modo protegido, o convidado precisa reconhecer que uma região do espaço de endereços está sendo usada para MMIO com uma hiperchamada, reduzindo o risco de vazamento acidental de informações.
Programação
Cada CPU virtual é representada por uma linha de execução POSIX e programada pelo host
Linux. A linha de execução chama o ioctl KVM_RUN no FD da vCPU, resultando
na troca do hipervisor para o contexto da vCPU convidada. O programador do host considera o tempo gasto em um contexto convidado como tempo usado pela linha de execução da vCPU correspondente. KVM_RUN é retornado quando há um evento que precisa ser processado pelo
VMM, como E/S, fim de interrupção ou vCPU interrompida. A VMM processa o evento e chama KVM_RUN novamente.
Durante KVM_RUN, a linha de execução permanece passível de remoção pelo programador do host, exceto
pela execução do código do hipervisor EL2, que não é passível de remoção. A pVM convidada não tem um mecanismo para controlar esse comportamento.
Como todas as linhas de execução de vCPU são programadas como qualquer outra tarefa do espaço do usuário, elas estão sujeitas a todos os mecanismos padrão de QoS. Especificamente, cada encadeamento de vCPU pode ser associado a CPUs físicas, colocado em conjuntos de CPUs, aumentado ou limitado usando fixação de utilização, ter a prioridade/política de programação alterada e muito mais.
Dispositivos virtuais
O crosvm é compatível com vários dispositivos, incluindo:
- virtio-blk para imagens de disco compostas, somente leitura ou leitura-gravação
- vhost-vsock para comunicação com o host
- virtio-pci como transporte virtio
- pl030: relógio em tempo real (RTC)
- UART 16550a para comunicação serial
firmware da pVM
O firmware da PVM (pvmfw) é o primeiro código executado por uma PVM, semelhante à ROM de inicialização de um dispositivo físico. O objetivo principal do pvmfw é fazer o bootstrap da inicialização segura e derivar o segredo exclusivo da PVM. O pvmfw não se limita ao uso com nenhum SO específico, como o Microdroid, desde que o SO seja compatível com o crosvm e tenha sido assinado corretamente.
O binário pvmfw é armazenado em uma partição flash de mesmo nome e é atualizado usando OTA.
Inicialização do dispositivo
A seguinte sequência de etapas é adicionada ao procedimento de inicialização de um dispositivo com pKVM ativado:
- O carregador de inicialização do Android (ABL) carrega o pvmfw da partição dele na memória e verifica a imagem.
- A ABL recebe os segredos do mecanismo de composição do identificador do dispositivo (DICE) (identificadores de dispositivo compostos (CDIs) e cadeia de certificados DICE) de uma raiz de confiança.
- A ABL deriva os CDIs necessários para pvmfw e os anexa ao binário pvmfw.
- O ABL adiciona um nó
linux,pkvm-guest-firmware-memoryde região de memória reservada à DT, descrevendo o local e o tamanho do binário pvmfw e os secrets derivados na etapa anterior. - O ABL transfere o controle para o Linux, que inicializa o pKVM.
- O pKVM desvincula a região de memória pvmfw das tabelas de páginas de estágio 2 do host e a protege do host (e dos convidados) durante todo o tempo de atividade do dispositivo.
Após a inicialização do dispositivo, o Microdroid é inicializado de acordo com as etapas na seção Sequência de inicialização do documento Microdroid.
Inicialização da pVM
Ao criar uma pVM, o crosvm (ou outro VMM) precisa criar um memslot grande o suficiente para ser preenchido com a imagem pvmfw pelo hipervisor. O VMM também é restrito na lista de registros cujo valor inicial pode ser definido (x0-x14 para a vCPU principal, nenhum para vCPUs secundárias). Os registros restantes são reservados e fazem parte da ABI hypervisor-pvmfw.
Quando a pVM é executada, o hipervisor primeiro entrega o controle da vCPU primária
ao pvmfw. O firmware espera que o crosvm tenha carregado um kernel assinado pelo AVB, que pode ser um carregador de inicialização ou qualquer outra imagem, e um FDT não assinado para a memória em offsets conhecidos. O pvmfw valida a assinatura do AVB e, se for bem-sucedido, gera uma árvore de dispositivos confiável do FDT recebido, apaga os segredos da memória e ramifica para o ponto de entrada da carga útil. Se uma das etapas de
verificação falhar, o firmware vai emitir uma hiperchamada PSCI SYSTEM_RESET.
Entre as inicializações, as informações sobre a instância de pVM são armazenadas em uma partição (dispositivo virtio-blk) e criptografadas com o secret do pvmfw para garantir que, após uma reinicialização, o secret seja provisionado para a instância correta.