
本页描述了用于在驱动程序和框架之间有效地通信操作数缓冲区的数据结构和方法。
在模型编译时,框架将常量操作数的值提供给驱动程序。根据常量操作数的生命周期,其值位于 HIDL 向量或共享内存池中。
- 如果生命周期为
CONSTANT_COPY,则值位于模型结构的operandValues字段中。因为 HIDL 向量中的值是在进程间通信 (IPC) 期间复制的,所以这通常仅用于保存少量数据,例如标量操作数(例如ADD中的激活标量)和小张量参数(例如,RESHAPE中的形状张量)。 - 如果生命周期是
CONSTANT_REFERENCE,则这些值位于模型结构的pools字段中。在 IPC 期间仅复制共享内存池的句柄,而不是复制原始值。因此,使用共享内存池保存大量数据(例如,卷积中的权重参数)比 HIDL 向量更有效。
在模型执行时,框架向驱动程序提供输入和输出操作数的缓冲区。与可能在 HIDL 向量中发送的编译时常量不同,执行的输入和输出数据始终通过内存池集合进行通信。
HIDL 数据类型hidl_memory在编译和执行中都用于表示未映射的共享内存池。驱动程序应根据hidl_memory数据类型的名称相应地映射内存以使其可用。支持的内存名称为:
-
ashmem:Android 共享内存。有关更多详细信息,请参阅内存。 -
mmap_fd:由文件描述符通过mmap支持的共享内存。 -
hardware_buffer_blob:由 AHardwareBuffer 支持的共享内存,格式AHARDWARE_BUFFER_FORMAT_BLOB。可从神经网络 (NN) HAL 1.2 获得。有关更多详细信息,请参阅AHardwareBuffer 。 -
hardware_buffer:由不使用格式AHARDWARE_BUFFER_FORMAT_BLOB的通用 AHardwareBuffer 支持的共享内存。仅在模型执行中支持非 BLOB 模式硬件缓冲区。可从 NN HAL 1.2 获得。有关更多详细信息,请参阅AHardwareBuffer 。
从 NN HAL 1.3 开始,NNAPI 支持为驱动程序管理的缓冲区提供分配器接口的内存域。驱动程序管理的缓冲区也可以用作执行输入或输出。有关更多详细信息,请参阅内存域。
NNAPI 驱动程序必须支持ashmem和mmap_fd内存名称的映射。从 NN HAL 1.3 开始,驱动程序还必须支持hardware_buffer_blob的映射。对一般非 BLOB 模式hardware_buffer和内存域的支持是可选的。
A硬件缓冲区
AHardwareBuffer 是一种包装Gralloc 缓冲区的共享内存。在 Android 10 中,神经网络 API (NNAPI) 支持使用AHardwareBuffer ,允许驱动程序在不复制数据的情况下执行执行,从而提高应用程序的性能和功耗。例如,相机 HAL 堆栈可以使用相机 NDK 和媒体 NDK API 生成的 AHardwareBuffer 句柄将 AHardwareBuffer 对象传递给 NNAPI 以进行机器学习工作负载。有关详细信息,请参阅ANeuralNetworksMemory_createFromAHardwareBuffer 。
NNAPI 中使用的 AHardwareBuffer 对象通过名为hardware_buffer或hardware_buffer_blob的hidl_memory结构传递给驱动程序。 hidl_memory结构hardware_buffer_blob仅表示具有AHARDWAREBUFFER_FORMAT_BLOB格式的 AHardwareBuffer 对象。
框架所需的信息编码在hidl_memory结构的hidl_handle字段中。 hidl_handle字段包装native_handle ,它对有关 AHardwareBuffer 或 Gralloc 缓冲区的所有必需元数据进行编码。
驱动程序必须正确解码提供的hidl_handle字段并访问由hidl_handle描述的内存。当调用getSupportedOperations_1_2 、 getSupportedOperations_1_1或getSupportedOperations方法时,驱动程序应该检测它是否可以解码提供的hidl_handle并访问hidl_handle描述的内存。如果不支持用于常量操作数的hidl_handle字段,则模型准备必须失败。如果不支持用于执行的输入或输出操作数的hidl_handle字段,则执行必须失败。如果模型准备或执行失败,建议驱动程序返回GENERAL_FAILURE错误代码。
内存域
对于运行 Android 11 或更高版本的设备,NNAPI 支持为驱动程序管理的缓冲区提供分配器接口的内存域。这允许跨执行传递设备本机内存,抑制在同一驱动程序上连续执行之间不必要的数据复制和转换。此流程如图 1 所示。
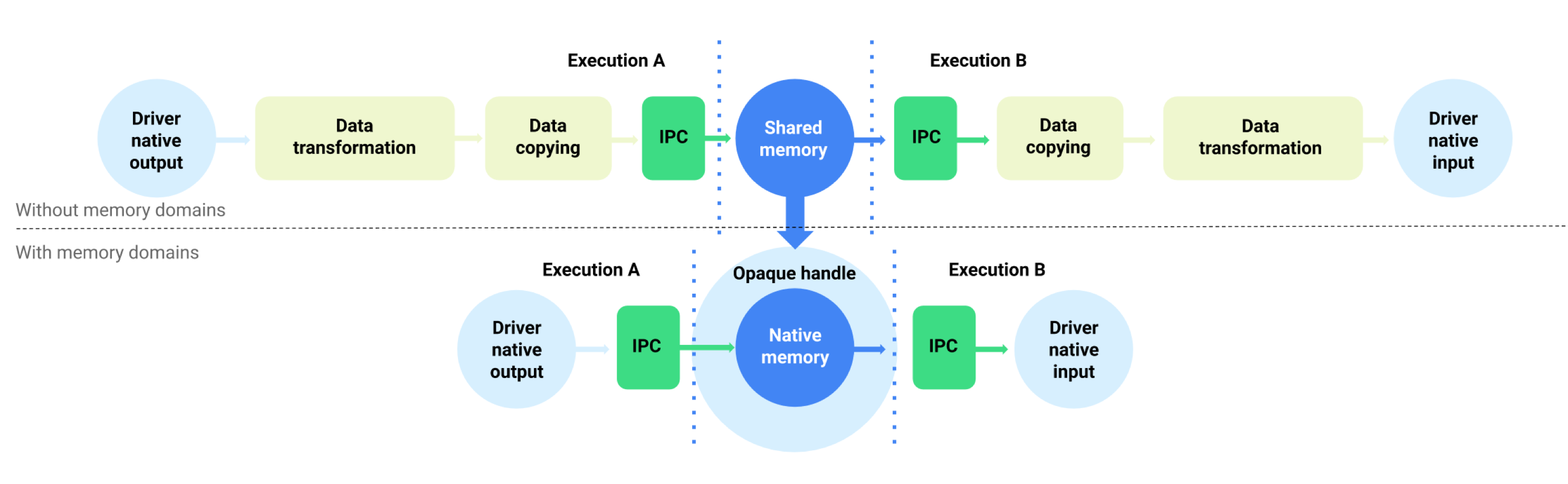
图 1.使用内存域的缓冲区数据流
内存域功能适用于大部分位于驱动程序内部且不需要在客户端频繁访问的张量。这种张量的例子包括序列模型中的状态张量。对于需要在客户端频繁访问 CPU 的张量,最好使用共享内存池。
要支持内存域功能,请实现IDevice::allocate以允许框架请求驱动程序管理的缓冲区分配。在分配期间,框架为缓冲区提供以下属性和使用模式:
-
BufferDesc描述了缓冲区所需的属性。 -
BufferRole将缓冲区的潜在使用模式描述为准备好的模型的输入或输出。缓冲区分配时可以指定多个角色,分配的缓冲区只能作为指定的角色使用。
分配的缓冲区在驱动程序内部。驱动程序可以选择任何缓冲区位置或数据布局。当缓冲区分配成功后,驱动程序的客户端可以使用返回的令牌或IBuffer对象来引用缓冲区或与缓冲区进行交互。
当引用缓冲区作为执行的Request结构中的MemoryPool对象之一时,会提供来自IDevice::allocate的令牌。为了防止一个进程试图访问在另一个进程中分配的缓冲区,驱动程序必须在每次使用缓冲区时应用适当的验证。驱动程序必须验证缓冲区使用是分配期间提供的BufferRole角色之一,如果使用非法,则必须立即执行失败。
IBuffer对象用于显式内存复制。在某些情况下,驱动程序的客户端必须从共享内存池初始化驱动程序管理的缓冲区或将缓冲区复制到共享内存池。示例用例包括:
- 状态张量的初始化
- 缓存中间结果
- CPU 上的后备执行
为了支持这些用例,如果驱动程序支持内存域分配,则必须使用ashmem 、 mmap_fd和hardware_buffer_blob实现IBuffer::copyTo和IBuffer::copyFrom 。驱动程序支持非 BLOB 模式hardware_buffer是可选的。
在缓冲区分配过程中,缓冲区的维度可以从 BufferRole 指定的所有角色的相应模型操作数以及BufferRole中提供的维度BufferDesc 。结合所有维度信息,缓冲区可能具有未知的维度或等级。在这种情况下,缓冲器处于灵活状态,当用作模型输入时,尺寸是固定的,而当用作模型输出时,缓冲器处于动态状态。相同的缓冲区可以在不同的执行中用于不同形状的输出,并且驱动程序必须正确处理缓冲区大小调整。
内存域是一个可选功能。由于多种原因,驱动程序可以确定它不能支持给定的分配请求。例如:
- 请求的缓冲区具有动态大小。
- 驱动程序有内存限制,阻止它处理大缓冲区。
多个不同的线程可以同时从驱动程序管理的缓冲区中读取。同时访问缓冲区进行写或读/写是未定义的,但它不能使驱动程序服务崩溃或无限期地阻塞调用者。驱动程序可以返回错误或使缓冲区的内容处于不确定状态。