
אנדרואיד 8.0 כולל מבחני ביצועים של קלסר ו-hwbinder עבור תפוקה והשהייה. בעוד שקיימים תרחישים רבים לאיתור בעיות ביצועים מורגשות, הפעלת תרחישים כאלה עשויה להיות גוזלת זמן ולעתים קרובות התוצאות אינן זמינות עד לאחר שילוב מערכת. השימוש במבחני הביצועים המסופקים מקל על הבדיקה במהלך הפיתוח, לזהות בעיות חמורות מוקדם יותר ולשפר את חווית המשתמש.
מבחני ביצועים כוללים את ארבע הקטגוריות הבאות:
- תפוקת קלסר (זמין ב-
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - זמן השהיית קלסר (זמין ב-
frameworks/native/libs/binder/tests/schd-dbg.cpp) - תפוקת hwbinder (זמין ב-
system/libhwbinder/vts/performance/Benchmark.cpp) - חביון hwbinder (זמין ב-
system/libhwbinder/vts/performance/Latency.cpp)
על קלסר ו-hwbinder
Binder ו-hwbinder הן תשתיות תקשורת בין-תהליכים של אנדרואיד (IPC) שחולקות את אותו מנהל התקן לינוקס אך יש להן את ההבדלים האיכותיים הבאים:
| אספקט | כּוֹרֵך | hwbinder |
|---|---|---|
| מַטָרָה | ספק סכימת IPC למטרה כללית למסגרת | לתקשר עם חומרה |
| תכונה | מותאם לשימוש במסגרת אנדרואיד | זמן אחזור תקורה מינימלי נמוך |
| שנה מדיניות תזמון עבור חזית/רקע | כן | לא |
| ויכוחים חולפים | משתמש בסריאליזציה הנתמכת על ידי אובייקט Parcel | משתמש במאגרי פיזור ומונע את התקורה להעתקת נתונים הנדרשים להסדרת חבילות |
| ירושה עדיפות | לא | כן |
תהליכי קלסר ו-hwbinder
Visualizer של systrace מציג עסקאות באופן הבא:
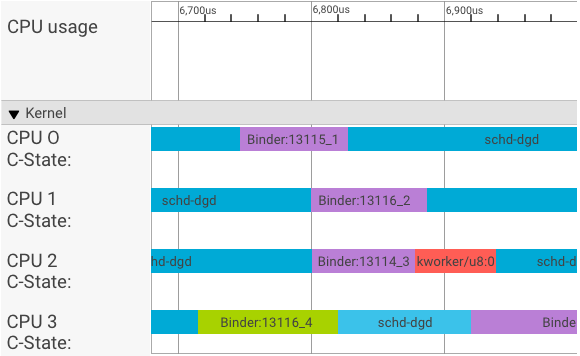
בדוגמה לעיל:
- ארבעת (4) תהליכי schd-dbg הם תהליכי לקוח.
- ארבעת (4) תהליכי הקלסר הם תהליכי שרת (השם מתחיל ב- Binder ומסתיים במספר רצף).
- תהליך לקוח תמיד מזווג עם תהליך שרת, המוקדש ללקוח שלו.
- כל צמדי התהליך של שרת-לקוח מתוזמנים באופן עצמאי על ידי הליבה במקביל.
ב-CPU 1, ליבת מערכת ההפעלה מבצעת את הלקוח כדי להוציא את הבקשה. לאחר מכן הוא משתמש באותו מעבד בכל פעם שאפשר כדי להעיר תהליך שרת, לטפל בבקשה ולהחליף את ההקשר בחזרה לאחר השלמת הבקשה.
תפוקה לעומת חביון
בעסקה מושלמת, שבה תהליך הלקוח והשרת מתחלפים בצורה חלקה, מבחני תפוקה והשהייה אינם מייצרים מסרים שונים באופן מהותי. עם זאת, כאשר ליבת מערכת ההפעלה מטפלת בבקשת פסיקה (IRQ) מחומרה, ממתינה למנעולים, או פשוט בוחרת לא לטפל בהודעה מיד, יכולה להיווצר בועת חביון.

מבחן התפוקה מייצר מספר רב של עסקאות בגדלים שונים של מטען, המספק הערכה טובה לזמן העסקה הרגיל (במקרה הטוב ביותר) ואת התפוקה המקסימלית שהקלסר יכול להשיג.
לעומת זאת, מבחן ההשהיה לא מבצע פעולות על המטען כדי למזער את זמן העסקאות הרגיל. אנו יכולים להשתמש בזמן העסקה כדי להעריך את תקורה של הקלסר, לעשות סטטיסטיקות למקרה הגרוע ולחשב את היחס בין עסקאות שזמן ההשהיה שלהן עומד בדד-ליין מוגדר.
טפל בהיפוכי עדיפות
היפוך עדיפות מתרחש כאשר שרשור עם עדיפות גבוהה יותר מחכה באופן הגיוני לשרשור עם עדיפות נמוכה יותר. לאפליקציות בזמן אמת (RT) יש בעיית היפוך עדיפות:
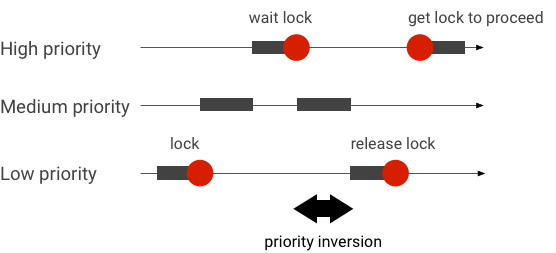
בעת שימוש בתזמון של Linux Completely Fair Scheduler (CFS), לשרשור תמיד יש סיכוי לפעול גם כאשר לשרשורים אחרים יש עדיפות גבוהה יותר. כתוצאה מכך, יישומים עם תזמון CFS מטפלים בהיפוך עדיפות כהתנהגות צפויה ולא כבעיה. במקרים שבהם מסגרת האנדרואיד זקוקה לתזמון RT כדי להבטיח את ההרשאה של שרשורים בעדיפות גבוהה, עם זאת, יש לפתור היפוך עדיפות.
דוגמה להיפוך עדיפות במהלך עסקת קלסר (חוט RT נחסם באופן הגיוני על ידי שרשורי CFS אחרים כאשר ממתינים לשרשור קלסר לשירות):
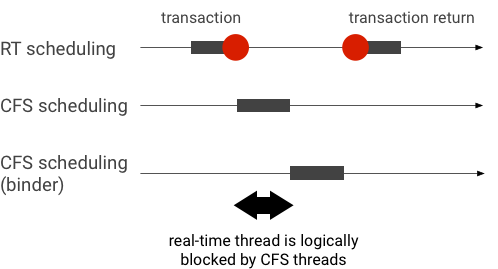
כדי להימנע מחסימות, אתה יכול להשתמש בירושה עדיפות כדי להסלים זמנית את פתיל ה-Binder לשרשור RT כאשר הוא נותן שירות לבקשה מלקוח RT. זכור שלתזמון RT יש משאבים מוגבלים ויש להשתמש בו בזהירות. במערכת עם n מעבדים, המספר המרבי של חוטי RT נוכחיים הוא גם n ; שרשורי RT נוספים עשויים להצטרך להמתין (ולפיכך להחמיץ את המועדים שלהם) אם כל המעבדים נלקחים על ידי שרשורי RT אחרים.
כדי לפתור את כל היפוכי העדיפויות האפשריים, תוכל להשתמש בירושה של עדיפות גם עבור מקשר וגם עבור hwbinder. עם זאת, מכיוון שהקלסר נמצא בשימוש נרחב בכל המערכת, הפעלת תורשה עדיפות עבור עסקאות קלסר עשויה לשלוח ספאם למערכת עם יותר שרשורי RT ממה שהיא יכולה לשרת.
הפעל מבחני תפוקה
בדיקת התפוקה מופעלת כנגד תפוקת עסקאות בינדר/hwbinder. במערכת שאינה עמוסה יתר על המידה, בועות חביון נדירות וניתן לבטל את השפעתן כל עוד מספר האיטרציות גבוה מספיק.
- בדיקת תפוקת הקלסר נמצאת ב-
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - מבחן התפוקה של hwbinder נמצא ב-
system/libhwbinder/vts/performance/Benchmark.cpp.
תוצאות מבחן
תוצאות בדיקת תפוקה לדוגמה עבור עסקאות המשתמשות בגדלים שונים של מטען:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- זמן מציין את עיכוב הנסיעה הלוך ושוב נמדד בזמן אמת.
- CPU מציין את הזמן המצטבר שבו מתוזמנים CPUs לבדיקה.
- איטרציות מציינים את מספר הפעמים שפונקציית הבדיקה בוצעה.
לדוגמה, עבור מטען של 8 בתים:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
... התפוקה המקסימלית שהקלסר יכול להשיג מחושבת כך:
תפוקה מקסימלית עם מטען של 8 בתים = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
אפשרויות בדיקה
כדי לקבל תוצאות ב-.json, הפעל את הבדיקה עם הארגומנט --benchmark_format=json :
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}
הפעל בדיקות חביון
מבחן ההשהיה מודד את הזמן שלוקח ללקוח להתחיל באתחול העסקה, לעבור לתהליך השרת לטיפול ולקבל את התוצאה. הבדיקה גם מחפשת התנהגויות ידועות של מתזמן גרוע שיכולות להשפיע לרעה על זמן האחזור של העסקאות, כגון מתזמן שאינו תומך בירושה עדיפות או מכבד את דגל הסנכרון.
- מבחן השהיה של הקלסר הוא ב-
frameworks/native/libs/binder/tests/schd-dbg.cpp. - מבחן השהיה של hwbinder נמצא ב-
system/libhwbinder/vts/performance/Latency.cpp.
תוצאות מבחן
התוצאות (ב-.json) מציגות נתונים סטטיסטיים לגבי זמן האחזור הממוצע/הטוב ביותר/גרוע ביותר ומספר המועדים שהוחמצו.
אפשרויות בדיקה
מבחני אחזור לוקחים את האפשרויות הבאות:
| פקודה | תיאור |
|---|---|
-i value | ציין את מספר האיטרציות. |
-pair value | ציין את מספר זוגות התהליך. |
-deadline_us 2500 | ציין את המועד האחרון אצלנו. |
-v | קבל פלט מילולי (ניפוי באגים). |
-trace | עצור את המעקב על פגיעה במועד האחרון. |
הסעיפים הבאים מפרטים כל אפשרות, מתארים את השימוש ומספקים תוצאות לדוגמה.
ציין איטרציות
דוגמה עם מספר רב של איטרציות ופלט מילולי מושבתים:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}
תוצאות בדיקה אלו מראות את הדברים הבאים:
-
"pair":3 - יוצר זוג לקוח ושרת אחד.
-
"iterations": 5000 - כולל 5000 איטרציות.
-
"deadline_us":2500 - המועד האחרון הוא 2500US (2.5ms); רוב העסקאות צפויות לעמוד בערך זה.
-
"I": 10000 - איטרציית בדיקה אחת כוללת שתי (2) עסקאות:
- עסקה אחת בעדיפות רגילה (
CFS other) - עסקה אחת לפי עדיפות בזמן אמת (
RT-fifo)
- עסקה אחת בעדיפות רגילה (
-
"S": 9352 - 9352 מהעסקאות מסונכרנות באותו מעבד.
-
"R": 0.9352 - מציין את היחס שבו הלקוח והשרת מסונכרנים יחד באותו מעבד.
-
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996} - המקרה הממוצע (
avg), הגרוע ביותר (wst) והמקרה הטוב ביותר (bst) עבור כל העסקאות שהונפקו על ידי מתקשר עם עדיפות רגילה. שתי עסקאותmissאת המועד האחרון, מה שהופך את יחס המפגש (meetR) ל-0.9996. -
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1} - בדומה ל-
other_ms, אך עבור עסקאות שהונפקו על ידי הלקוח עם עדיפותrt_fifo. סביר להניח (אך לא חובה) של-fifo_msיש תוצאה טובה יותר מ-other_ms, עם ערכיavgו-wstנמוכים יותר ו-meetRגבוה יותר (ההבדל יכול להיות אפילו יותר משמעותי עם עומס ברקע).
הערה: עומס רקע עשוי להשפיע על תוצאת התפוקה ועל ה- other_ms tuple במבחן ההשהיה. רק ה- fifo_ms עשוי להציג תוצאות דומות כל עוד לעומס הרקע יש עדיפות נמוכה יותר מ- RT-fifo .
ציין ערכי זוג
כל תהליך לקוח משויך לתהליך שרת המיועד ללקוח, וניתן לתזמן כל זוג באופן עצמאי לכל מעבד. עם זאת, העברת המעבד לא אמורה להתרחש במהלך עסקה כל עוד דגל SYNC הוא honor .
ודא שהמערכת אינה עמוסה מדי! בעוד שצפוי זמן אחזור גבוה במערכת עמוסה מדי, תוצאות בדיקה עבור מערכת עמוסה לא מספקות מידע שימושי. כדי לבדוק מערכת עם לחץ גבוה יותר, השתמש -pair #cpu-1 (או -pair #cpu בזהירות). בדיקה באמצעות -pair n עם n > #cpu מעמיסה על המערכת ויוצרת מידע חסר תועלת.
ציין ערכי מועד אחרון
לאחר בדיקת תרחישים מקיפים של משתמשים (הרצת מבחן ההשהיה על מוצר מוסמך), קבענו ש-2.5 אלפיות השנייה הוא המועד האחרון לעמוד בו. עבור יישומים חדשים עם דרישות גבוהות יותר (כגון 1000 תמונות/שנייה), ערך המועד האחרון ישתנה.
ציין פלט מילולי
שימוש באפשרות -v מציג פלט מילולי. דוגמא:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- שרשור השירות נוצר עם עדיפות
SCHED_OTHERומופעל ב-CPU:1עםpid 8674. - לאחר מכן, העסקה הראשונה מתחילה על ידי
fifo-caller. כדי לשרת את העסקה הזו, ה-hwbinder משדרג את העדיפות של השרת (pid: 8674 tid: 8676) ל-99 וגם מסמן אותו במחלקת תזמון חולפת (מודפס כ???). לאחר מכן, המתזמן שם את תהליך השרת ב-CPU:0כדי להפעיל אותו ומסנכרן אותו עם אותו מעבד עם הלקוח שלו. - למתקשר העסקה השנייה יש עדיפות
SCHED_OTHER. השרת משדרג את עצמו ומשרת את המתקשר בעדיפותSCHED_OTHER.
השתמש במעקב עבור ניפוי באגים
אתה יכול לציין את האפשרות -trace כדי לנפות באגים בבעיות חביון. בשימוש, בדיקת החביון מפסיקה את הקלטת ה-tracelog ברגע שבו מזוהה חביון רע. דוגמא:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
הרכיבים הבאים יכולים להשפיע על זמן האחזור:
- מצב בנייה של אנדרואיד . מצב Eng בדרך כלל איטי יותר ממצב userdebug.
- מסגרת . כיצד שירות המסגרת משתמש
ioctlכדי להגדיר את ה-Binder? - נהג קלסר . האם הנהג תומך בנעילה עדינה? האם הוא מכיל את כל הפאצ'ים להפניית ביצועים?
- גרסת הקרנל . ככל שלקרנל יש יכולת טובה יותר בזמן אמת, כך התוצאות טובות יותר.
- תצורת ליבה . האם תצורת הליבה מכילה תצורות
DEBUGכגוןDEBUG_PREEMPTו-DEBUG_SPIN_LOCK? - מתזמן ליבה . האם לליבה יש מתזמן Energy-Aware (EAS) או מתזמן רב-עיבוד הטרוגני (HMP)? האם מנהלי התקנים של ליבה כלשהם (מנהל התקן של
cpu-freq, מנהל התקןcpu-idle,cpu-hotplugוכו') משפיעים על המתזמן?