
Um ein kontinuierliches Integrations-Dashboard zu unterstützen, das skalierbar, leistungsstark und flexibel ist, muss das VTS-Dashboard-Backend sorgfältig entworfen werden und über ein umfassendes Verständnis der Datenbankfunktionalität verfügen. Google Cloud Datastore ist eine NoSQL-Datenbank, die transaktionale ACID-Garantien und letztendliche Konsistenz sowie starke Konsistenz innerhalb von Entitätsgruppen bietet. Die Struktur unterscheidet sich jedoch stark von SQL-Datenbanken (und sogar von Cloud Bigtable). Anstelle von Tabellen, Zeilen und Zellen gibt es Arten, Entitäten und Eigenschaften.
In den folgenden Abschnitten werden die Datenstruktur und Abfragemuster zum Erstellen eines effektiven Backends für den VTS Dashboard-Webdienst beschrieben.
Entitäten
Die folgenden Entitäten speichern Zusammenfassungen und Ressourcen von VTS-Testläufen:
- Testentität . Speichert Metadaten zu Testläufen eines bestimmten Tests. Sein Schlüssel ist der Testname und zu seinen Eigenschaften gehören die Anzahl der Fehler, die Anzahl der bestandenen Tests und eine Liste der Testfallunterbrechungen ab dem Zeitpunkt, an dem die Alarmjobs ihn aktualisieren.
- Testlauf-Entität . Enthält Metadaten aus Läufen eines bestimmten Tests. Es muss die Start- und Endzeitstempel des Tests, die Test-Build-ID, die Anzahl der bestandenen und fehlgeschlagenen Testfälle, die Art der Ausführung (z. B. vor der Übermittlung, nach der Übermittlung oder lokal), eine Liste von Protokolllinks und den Host speichern Maschinenname und Anzahl der Abdeckungszusammenfassungen.
- Geräteinformationsentität . Enthält Details zu den während des Testlaufs verwendeten Geräten. Es enthält die Build-ID des Geräts, den Produktnamen, das Build-Ziel, den Zweig und ABI-Informationen. Dies wird getrennt von der Testlaufeinheit gespeichert, um Testläufe mit mehreren Geräten im Eins-zu-viele-Verfahren zu unterstützen.
- Profiling Point Run-Entität . Fasst die für einen bestimmten Profilierungspunkt innerhalb eines Testlaufs gesammelten Daten zusammen. Es beschreibt die Achsenbeschriftungen, den Namen des Profilierungspunkts, die Werte, den Typ und den Regressionsmodus der Profilierungsdaten.
- Abdeckungseinheit . Beschreibt die für eine Datei erfassten Abdeckungsdaten. Es enthält die Git-Projektinformationen, den Dateipfad und die Liste der Coverage-Zählungen pro Zeile in der Quelldatei.
- Testfalllauf-Entität . Beschreibt das Ergebnis eines bestimmten Testfalls aus einem Testlauf, einschließlich des Testfallnamens und seines Ergebnisses.
- Benutzerfavoriten-Entität . Jedes Benutzerabonnement kann in einer Entität dargestellt werden, die einen Verweis auf den Test und die vom App Engine-Benutzerdienst generierte Benutzer-ID enthält. Dies ermöglicht eine effiziente bidirektionale Abfrage (dh für alle Benutzer, die einen Test abonniert haben, und für alle von einem Benutzer favorisierten Tests).
Entitätsgruppierung
Jedes Testmodul stellt den Stamm einer Entitätsgruppe dar. Testlaufentitäten sind sowohl untergeordnete Elemente dieser Gruppe als auch übergeordnete Elemente für Geräteentitäten, Profilierungspunktentitäten und Abdeckungsentitäten, die für den jeweiligen Test und Testlaufvorfahren relevant sind.
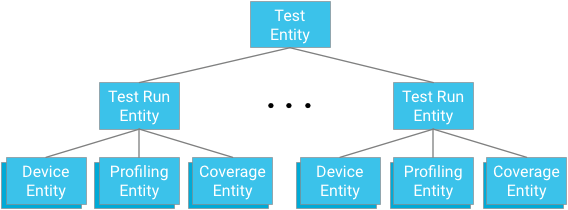
Kernpunkt: Beim Entwerfen von Abstammungsbeziehungen müssen Sie die Notwendigkeit, effektive und konsistente Abfragemechanismen bereitzustellen, gegen die durch die Datenbank erzwungenen Einschränkungen abwägen.
Vorteile
Die Konsistenzanforderung stellt sicher, dass zukünftige Vorgänge die Auswirkungen einer Transaktion erst sehen, wenn sie festgeschrieben wird, und dass Transaktionen in der Vergangenheit für aktuelle Vorgänge sichtbar sind. In Cloud Datastore werden durch die Entitätsgruppierung Inseln mit starker Lese- und Schreibkonsistenz innerhalb der Gruppe erstellt, die in diesem Fall alle Testläufe und Daten umfasst, die sich auf ein Testmodul beziehen. Dies bietet folgende Vorteile:
- Lesevorgänge und Aktualisierungen des Testmodulstatus durch Alarmjobs können als atomar behandelt werden
- Garantiert konsistente Ansicht der Testfallergebnisse innerhalb der Testmodule
- Schnellere Abfrage innerhalb der Stammbäume
Einschränkungen
Es wird nicht empfohlen, schneller als eine Entität pro Sekunde in eine Entitätsgruppe zu schreiben, da einige Schreibvorgänge möglicherweise abgelehnt werden. Solange die Alert-Jobs und das Hochladen nicht schneller als ein Schreibvorgang pro Sekunde erfolgen, ist die Struktur solide und garantiert eine starke Konsistenz.
Letztendlich ist die Obergrenze von einem Schreibvorgang pro Testmodul und Sekunde angemessen, da Testläufe einschließlich des Overheads des VTS-Frameworks normalerweise mindestens eine Minute dauern. Sofern ein Test nicht dauerhaft gleichzeitig auf mehr als 60 verschiedenen Hosts ausgeführt wird, kann es nicht zu einem Schreibengpass kommen. Dies wird noch unwahrscheinlicher, wenn man bedenkt, dass jedes Modul Teil eines Testplans ist, der oft länger als eine Stunde dauert. Anomalien können leicht behoben werden, wenn Hosts die Tests gleichzeitig ausführen, was zu kurzen Schreibstößen auf denselben Hosts führt (z. B. indem Schreibfehler erkannt und erneut versucht werden).
Überlegungen zur Skalierung
Ein Testlauf muss nicht unbedingt den Test als übergeordnetes Element haben (er könnte beispielsweise einen anderen Schlüssel annehmen und Testnamen und Teststartzeit als Eigenschaften haben); Allerdings wird dadurch eine starke Konsistenz gegen eine letztendliche Konsistenz ausgetauscht. Beispielsweise sieht der Warnungsjob möglicherweise keine gegenseitig konsistente Momentaufnahme der letzten Testläufe innerhalb eines Testmoduls, was bedeutet, dass der globale Status möglicherweise keine vollständig genaue Darstellung der Abfolge von Testläufen darstellt. Dies kann sich auch auf die Anzeige von Testläufen innerhalb eines einzelnen Testmoduls auswirken, die nicht unbedingt eine konsistente Momentaufnahme der Laufsequenz darstellen müssen. Letztendlich wird der Snapshot konsistent sein, es gibt jedoch keine Garantie dafür, dass die Daten aktuell sind.
Testfälle
Ein weiterer potenzieller Engpass sind große Tests mit vielen Testfällen. Die beiden operativen Einschränkungen sind der maximale Schreibdurchsatz innerhalb einer Entitätsgruppe von einem pro Sekunde sowie eine maximale Transaktionsgröße von 500 Entitäten.
Ein Ansatz wäre, einen Testfall anzugeben, der einen Testlauf als Vorgänger hat (ähnlich wie Abdeckungsdaten, Profilierungsdaten und Geräteinformationen gespeichert werden):
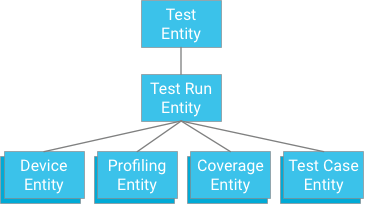
Obwohl dieser Ansatz Atomizität und Konsistenz bietet, bringt er den Tests starke Einschränkungen mit sich: Wenn eine Transaktion auf 500 Entitäten beschränkt ist, kann ein Test nicht mehr als 498 Testfälle umfassen (vorausgesetzt, es liegen keine Abdeckungs- oder Profilierungsdaten vor). Wenn ein Test diesen Wert überschreiten würde, könnte eine einzelne Transaktion nicht alle Testfallergebnisse auf einmal schreiben, und die Aufteilung der Testfälle in separate Transaktionen könnte den maximalen Schreibdurchsatz der Entitätsgruppe von einer Iteration pro Sekunde überschreiten. Da sich diese Lösung ohne Leistungseinbußen nicht gut skalieren lässt, wird sie nicht empfohlen.
Anstatt die Testfallergebnisse jedoch als untergeordnete Elemente des Testlaufs zu speichern, können die Testfälle unabhängig voneinander gespeichert und ihre Schlüssel dem Testlauf bereitgestellt werden (ein Testlauf enthält eine Liste von Identifikatoren für seine Testfallentitäten):

Auf den ersten Blick scheint dies die starke Konsistenzgarantie zu verletzen. Wenn der Client jedoch über eine Testlaufentität und eine Liste von Testfall-IDs verfügt, muss er keine Abfrage erstellen. Stattdessen können die Testfälle direkt anhand ihrer Bezeichner abgerufen werden, was immer garantiert konsistent ist. Dieser Ansatz erleichtert die Beschränkung der Anzahl der Testfälle, die ein Testlauf haben kann, erheblich und sorgt gleichzeitig für eine starke Konsistenz, ohne dass übermäßiges Schreiben innerhalb einer Entitätsgruppe droht.
Datenzugriffsmuster
Das VTS-Dashboard verwendet die folgenden Datenzugriffsmuster:
- Benutzerfavoriten . Kann abgefragt werden, indem ein Gleichheitsfilter für Benutzerfavoritenentitäten verwendet wird, die das bestimmte App Engine-Benutzerobjekt als Eigenschaft haben.
- Testauflistung . Einfache Abfrage von Testentitäten. Um die Bandbreite zum Rendern der Homepage zu reduzieren, kann eine Prognose für die Anzahl der bestandenen und fehlgeschlagenen Tests verwendet werden, um die potenziell lange Auflistung der IDs fehlgeschlagener Testfälle und anderer Metadaten, die von den Alarmierungsjobs verwendet werden, wegzulassen.
- Testläufe . Das Abfragen von Testlaufentitäten erfordert eine Sortierung nach Schlüssel (Zeitstempel) und eine mögliche Filterung nach Testlaufeigenschaften wie Build-ID, Anzahl der bestandenen Tests usw. Durch die Durchführung einer Vorfahrenabfrage mit einem Testentitätsschlüssel ist der Lesevorgang stark konsistent. Zu diesem Zeitpunkt können alle Testfallergebnisse mithilfe der Liste der in einer Testlaufeigenschaft gespeicherten IDs abgerufen werden. Aufgrund der Art der Datenspeicher-Abrufvorgänge ist dies auch garantiert ein äußerst konsistentes Ergebnis.
- Profilierungs- und Abdeckungsdaten . Die Abfrage von Profilierungs- oder Abdeckungsdaten im Zusammenhang mit einem Test kann erfolgen, ohne dass auch andere Testlaufdaten abgerufen werden müssen (z. B. andere Profilierungs-/Abdeckungsdaten, Testfalldaten usw.). Eine Ancestor-Abfrage unter Verwendung der Test-Test- und Testlauf-Entitätsschlüssel ruft alle während des Testlaufs aufgezeichneten Profilierungspunkte ab. Indem auch nach dem Namen des Profilierungspunkts oder Dateinamen gefiltert wird, kann eine einzelne Profilierungs- oder Abdeckungsentität abgerufen werden. Aufgrund der Art von Vorfahrenabfragen ist dieser Vorgang stark konsistent.
Einzelheiten zur Benutzeroberfläche und Screenshots dieser Datenmuster in Aktion finden Sie unter VTS Dashboard-Benutzeroberfläche .